 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater360: Reconstructing Underwater Scenes from Panoramic Images with Omnidirectional Gaussian Splatting
May 26, 2026Underwater scene reconstruction is essential for immersive exploration of aquatic environments, yet remains challenging due to complex participating-media effects such as absorption and scattering, as well as the limited field of view (FoV) of conventional cameras. Although combining panoramic imaging with 3D Gaussian Splatting (3DGS) offers a promising direction for photorealistic underwater rendering, traditional 3DGS struggles with both spherical projection distortion and underwater medium degradation. In this paper, we propose \textbf{Underwater360}, a physics-informed omnidirectional 3DGS framework for underwater panoramic scene reconstruction. First, we introduce an Omnidirectional Gaussian Splatting module that performs ray casting directly in spherical camera space instead of relying on 2D projection approximations, thereby reducing geometric distortions under 360$^\circ$ FoV. Second, we design a physics-based appearance-medium modeling architecture with pose-conditioned appearance embeddings to explicitly decouple intrinsic scene radiance from depth-dependent backscatter and attenuation, enabling physically grounded scene appearance restoration. Finally, we establish a new panoramic underwater benchmark dataset containing both synthetic and real-world scenes. Extensive experiments demonstrate that Underwater360 achieves superior performance in underwater novel view synthesis and scene appearance restoration, delivering improved rendering quality and cross-view consistency in complex underwater environments. The code and datasets are released at https://github.com/SwcK423/Underwater360
CTFS : Collaborative Teacher Framework for Forward-Looking Sonar Image Semantic Segmentation with Extremely Limited Labels
Mar 22, 2026As one of the most important underwater sensing technologies, forward-looking sonar exhibits unique imaging characteristics. Sonar images are often affected by severe speckle noise, low texture contrast, acoustic shadows, and geometric distortions. These factors make it difficult for traditional teacher-student frameworks to achieve satisfactory performance in sonar semantic segmentation tasks under extremely limited labeled data conditions. To address this issue, we propose a Collaborative Teacher Semantic Segmentation Framework for forward-looking sonar images. This framework introduces a multi-teacher collaborative mechanism composed of one general teacher and multiple sonar-specific teachers. By adopting a multi-teacher alternating guidance strategy, the student model can learn general semantic representations while simultaneously capturing the unique characteristics of sonar images, thereby achieving more comprehensive and robust feature modeling. Considering the challenges of sonar images, which can lead teachers to generate a large number of noisy pseudo-labels, we further design a cross-teacher reliability assessment mechanism. This mechanism dynamically quantifies the reliability of pseudo-labels by evaluating the consistency and stability of predictions across multiple views and multiple teachers, thereby mitigating the negative impact caused by noisy pseudo-labels. Notably, on the FLSMD dataset, when only 2% of the data is labeled, our method achieves a 5.08% improvement in mIoU compared to other state-of-the-art approaches.
RSOD: Reliability-Guided Sonar Image Object Detection with Extremely Limited Labels
Jan 19, 2026Object detection in sonar images is a key technology in underwater detection systems. Compared to natural images, sonar images contain fewer texture details and are more susceptible to noise, making it difficult for non-experts to distinguish subtle differences between classes. This leads to their inability to provide precise annotation data for sonar images. Therefore, designing effective object detection methods for sonar images with extremely limited labels is particularly important. To address this, we propose a teacher-student framework called RSOD, which aims to fully learn the characteristics of sonar images and develop a pseudo-label strategy suitable for these images to mitigate the impact of limited labels. First, RSOD calculates a reliability score by assessing the consistency of the teacher's predictions across different views. To leverage this score, we introduce an object mixed pseudo-label method to tackle the shortage of labeled data in sonar images. Finally, we optimize the performance of the student by implementing a reliability-guided adaptive constraint. By taking full advantage of unlabeled data, the student can perform well even in situations with extremely limited labels. Notably, on the UATD dataset, our method, using only 5% of labeled data, achieves results that can compete against those of our baseline algorithm trained on 100% labeled data. We also collected a new dataset to provide more valuable data for research in the field of sonar.
OT-ALD: Aligning Latent Distributions with Optimal Transport for Accelerated Image-to-Image Translation
Nov 14, 2025The Dual Diffusion Implicit Bridge (DDIB) is an emerging image-to-image (I2I) translation method that preserves cycle consistency while achieving strong flexibility. It links two independently trained diffusion models (DMs) in the source and target domains by first adding noise to a source image to obtain a latent code, then denoising it in the target domain to generate the translated image. However, this method faces two key challenges: (1) low translation efficiency, and (2) translation trajectory deviations caused by mismatched latent distributions. To address these issues, we propose a novel I2I translation framework, OT-ALD, grounded in optimal transport (OT) theory, which retains the strengths of DDIB-based approach. Specifically, we compute an OT map from the latent distribution of the source domain to that of the target domain, and use the mapped distribution as the starting point for the reverse diffusion process in the target domain. Our error analysis confirms that OT-ALD eliminates latent distribution mismatches. Moreover, OT-ALD effectively balances faster image translation with improved image quality. Experiments on four translation tasks across three high-resolution datasets show that OT-ALD improves sampling efficiency by 20.29% and reduces the FID score by 2.6 on average compared to the top-performing baseline models.
Solving Prior Distribution Mismatch in Diffusion Models via Optimal Transport
Oct 17, 2024


In recent years, the knowledge surrounding diffusion models(DMs) has grown significantly, though several theoretical gaps remain. Particularly noteworthy is prior error, defined as the discrepancy between the termination distribution of the forward process and the initial distribution of the reverse process. To address these deficiencies, this paper explores the deeper relationship between optimal transport(OT) theory and DMs with discrete initial distribution. Specifically, we demonstrate that the two stages of DMs fundamentally involve computing time-dependent OT. However, unavoidable prior error result in deviation during the reverse process under quadratic transport cost. By proving that as the diffusion termination time increases, the probability flow exponentially converges to the gradient of the solution to the classical Monge-Amp\`ere equation, we establish a vital link between these fields. Therefore, static OT emerges as the most intrinsic single-step method for bridging this theoretical potential gap. Additionally, we apply these insights to accelerate sampling in both unconditional and conditional generation scenarios. Experimental results across multiple image datasets validate the effectiveness of our approach.
Global Parameterization-based Texture Space Optimization
Jun 06, 2024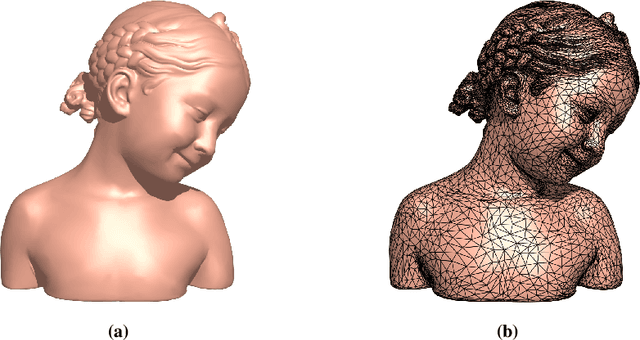

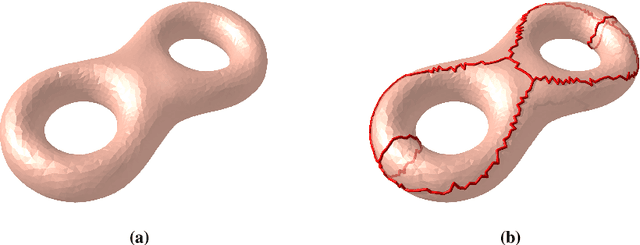
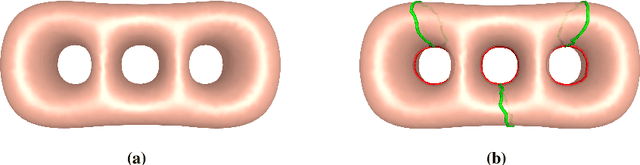
Texture mapping is a common technology in the area of computer graphics, it maps the 3D surface space onto the 2D texture space. However, the loose texture space will reduce the efficiency of data storage and GPU memory addressing in the rendering process. Many of the existing methods focus on repacking given textures, but they still suffer from high computational cost and hardly produce a wholly tight texture space. In this paper, we propose a method to optimize the texture space and produce a new texture mapping which is compact based on global parameterization. The proposed method is computationally robust and efficient. Experiments show the effectiveness of the proposed method and the potency in improving the storage and rendering efficiency.
Learning Heavily-Degraded Prior for Underwater Object Detection
Aug 24, 2023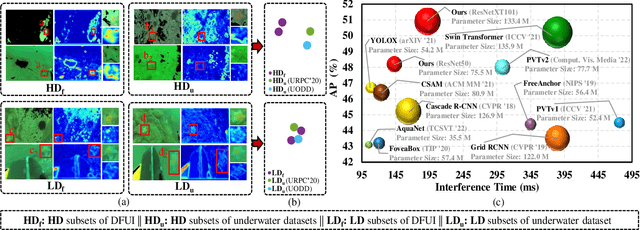
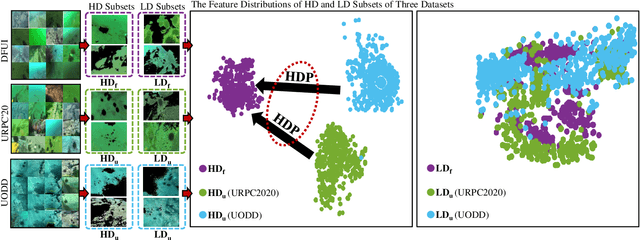

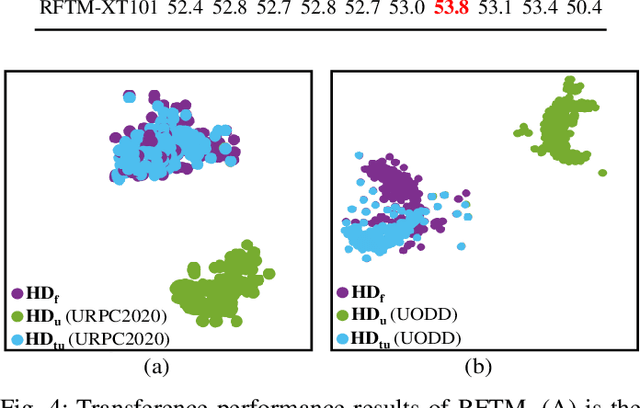
Underwater object detection suffers from low detection performance because the distance and wavelength dependent imaging process yield evident image quality degradations such as haze-like effects, low visibility, and color distortions. Therefore, we commit to resolving the issue of underwater object detection with compounded environmental degradations. Typical approaches attempt to develop sophisticated deep architecture to generate high-quality images or features. However, these methods are only work for limited ranges because imaging factors are either unstable, too sensitive, or compounded. Unlike these approaches catering for high-quality images or features, this paper seeks transferable prior knowledge from detector-friendly images. The prior guides detectors removing degradations that interfere with detection. It is based on statistical observations that, the heavily degraded regions of detector-friendly (DFUI) and underwater images have evident feature distribution gaps while the lightly degraded regions of them overlap each other. Therefore, we propose a residual feature transference module (RFTM) to learn a mapping between deep representations of the heavily degraded patches of DFUI- and underwater- images, and make the mapping as a heavily degraded prior (HDP) for underwater detection. Since the statistical properties are independent to image content, HDP can be learned without the supervision of semantic labels and plugged into popular CNNbased feature extraction networks to improve their performance on underwater object detection. Without bells and whistles, evaluations on URPC2020 and UODD show that our methods outperform CNN-based detectors by a large margin. Our method with higher speeds and less parameters still performs better than transformer-based detectors. Our code and DFUI dataset can be found in https://github.com/xiaoDetection/Learning-Heavily-Degraed-Prior.
Bilevel Generative Learning for Low-Light Vision
Aug 07, 2023Recently, there has been a growing interest in constructing deep learning schemes for Low-Light Vision (LLV). Existing techniques primarily focus on designing task-specific and data-dependent vision models on the standard RGB domain, which inherently contain latent data associations. In this study, we propose a generic low-light vision solution by introducing a generative block to convert data from the RAW to the RGB domain. This novel approach connects diverse vision problems by explicitly depicting data generation, which is the first in the field. To precisely characterize the latent correspondence between the generative procedure and the vision task, we establish a bilevel model with the parameters of the generative block defined as the upper level and the parameters of the vision task defined as the lower level. We further develop two types of learning strategies targeting different goals, namely low cost and high accuracy, to acquire a new bilevel generative learning paradigm. The generative blocks embrace a strong generalization ability in other low-light vision tasks through the bilevel optimization on enhancement tasks. Extensive experimental evaluations on three representative low-light vision tasks, namely enhancement, detection, and segmentation, fully demonstrate the superiority of our proposed approach. The code will be available at https://github.com/Yingchi1998/BGL.
Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation
Aug 04, 2023Multi-modality image fusion and segmentation play a vital role in autonomous driving and robotic operation. Early efforts focus on boosting the performance for only one task, \emph{e.g.,} fusion or segmentation, making it hard to reach~`Best of Both Worlds'. To overcome this issue, in this paper, we propose a \textbf{M}ulti-\textbf{i}nteractive \textbf{F}eature learning architecture for image fusion and \textbf{Seg}mentation, namely SegMiF, and exploit dual-task correlation to promote the performance of both tasks. The SegMiF is of a cascade structure, containing a fusion sub-network and a commonly used segmentation sub-network. By slickly bridging intermediate features between two components, the knowledge learned from the segmentation task can effectively assist the fusion task. Also, the benefited fusion network supports the segmentation one to perform more pretentiously. Besides, a hierarchical interactive attention block is established to ensure fine-grained mapping of all the vital information between two tasks, so that the modality/semantic features can be fully mutual-interactive. In addition, a dynamic weight factor is introduced to automatically adjust the corresponding weights of each task, which can balance the interactive feature correspondence and break through the limitation of laborious tuning. Furthermore, we construct a smart multi-wave binocular imaging system and collect a full-time multi-modality benchmark with 15 annotated pixel-level categories for image fusion and segmentation. Extensive experiments on several public datasets and our benchmark demonstrate that the proposed method outputs visually appealing fused images and perform averagely $7.66\%$ higher segmentation mIoU in the real-world scene than the state-of-the-art approaches. The source code and benchmark are available at \url{https://github.com/JinyuanLiu-CV/SegMiF}.
DPM-OT: A New Diffusion Probabilistic Model Based on Optimal Transport
Jul 21, 2023
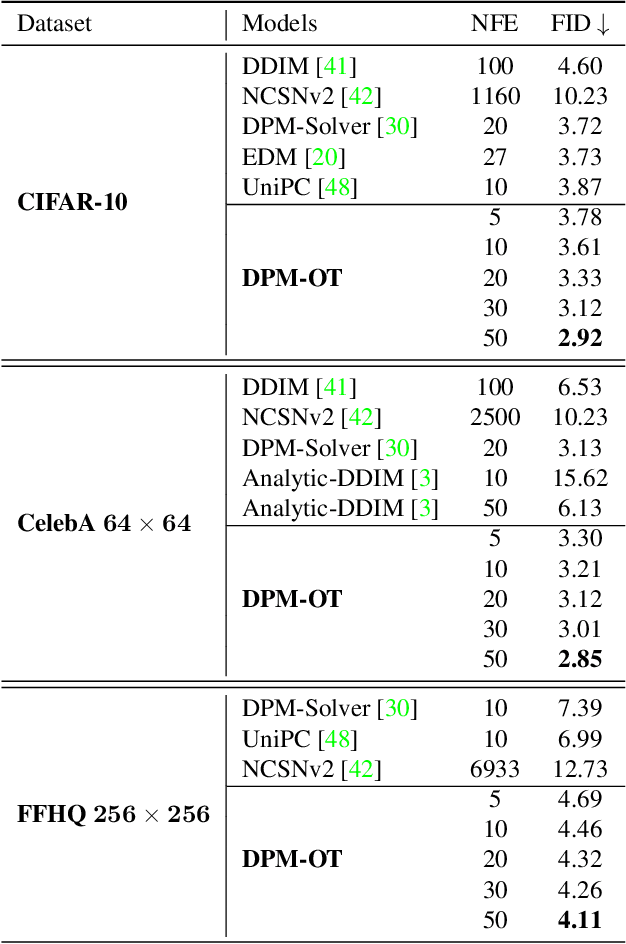


Sampling from diffusion probabilistic models (DPMs) can be viewed as a piecewise distribution transformation, which generally requires hundreds or thousands of steps of the inverse diffusion trajectory to get a high-quality image. Recent progress in designing fast samplers for DPMs achieves a trade-off between sampling speed and sample quality by knowledge distillation or adjusting the variance schedule or the denoising equation. However, it can't be optimal in both aspects and often suffer from mode mixture in short steps. To tackle this problem, we innovatively regard inverse diffusion as an optimal transport (OT) problem between latents at different stages and propose the DPM-OT, a unified learning framework for fast DPMs with a direct expressway represented by OT map, which can generate high-quality samples within around 10 function evaluations. By calculating the semi-discrete optimal transport map between the data latents and the white noise, we obtain an expressway from the prior distribution to the data distribution, while significantly alleviating the problem of mode mixture. In addition, we give the error bound of the proposed method, which theoretically guarantees the stability of the algorithm. Extensive experiments validate the effectiveness and advantages of DPM-OT in terms of speed and quality (FID and mode mixture), thus representing an efficient solution for generative modeling. Source codes are available at https://github.com/cognaclee/DPM-OT