 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy Aware Cascade Network: Bridging Epistemic Uncertainty and Geometric Manifold for 3D Tooth Segmentation
Jan 12, 2026Accurate three-dimensional (3D) tooth segmentation from Cone-Beam Computed Tomography (CBCT) is a prerequisite for digital dental workflows. However, achieving high-fidelity segmentation remains challenging due to adhesion artifacts in naturally occluded scans, which are caused by low contrast and indistinct inter-arch boundaries. To address these limitations, we propose the Anatomy Aware Cascade Network (AACNet), a coarse-to-fine framework designed to resolve boundary ambiguity while maintaining global structural consistency. Specifically, we introduce two mechanisms: the Ambiguity Gated Boundary Refiner (AGBR) and the Signed Distance Map guided Anatomical Attention (SDMAA). The AGBR employs an entropy based gating mechanism to perform targeted feature rectification in high uncertainty transition zones. Meanwhile, the SDMAA integrates implicit geometric constraints via signed distance map to enforce topological consistency, preventing the loss of spatial details associated with standard pooling. Experimental results on a dataset of 125 CBCT volumes demonstrate that AACNet achieves a Dice Similarity Coefficient of 90.17 \% and a 95\% Hausdorff Distance of 3.63 mm, significantly outperforming state-of-the-art methods. Furthermore, the model exhibits strong generalization on an external dataset with an HD95 of 2.19 mm, validating its reliability for downstream clinical applications such as surgical planning. Code for AACNet is available at https://github.com/shiliu0114/AACNet.
Helios: A Foundational Language Model for Smart Energy Knowledge Reasoning and Application
Dec 22, 2025In the global drive toward carbon neutrality, deeply coordinated smart energy systems underpin industrial transformation. However, the interdisciplinary, fragmented, and fast-evolving expertise in this domain prevents general-purpose LLMs, which lack domain knowledge and physical-constraint awareness, from delivering precise engineering-aligned inference and generation. To address these challenges, we introduce Helios, a large language model tailored to the smart energy domain, together with a comprehensive suite of resources to advance LLM research in this field. Specifically, we develop Enersys, a multi-agent collaborative framework for end-to-end dataset construction, through which we produce: (1) a smart energy knowledge base, EnerBase, to enrich the model's foundational expertise; (2) an instruction fine-tuning dataset, EnerInstruct, to strengthen performance on domain-specific downstream tasks; and (3) an RLHF dataset, EnerReinforce, to align the model with human preferences and industry standards. Leveraging these resources, Helios undergoes large-scale pretraining, SFT, and RLHF. We also release EnerBench, a benchmark for evaluating LLMs in smart energy scenarios, and demonstrate that our approach significantly enhances domain knowledge mastery, task execution accuracy, and alignment with human preferences.
HyperLoad: A Cross-Modality Enhanced Large Language Model-Based Framework for Green Data Center Cooling Load Prediction
Dec 22, 2025The rapid growth of artificial intelligence is exponentially escalating computational demand, inflating data center energy use and carbon emissions, and spurring rapid deployment of green data centers to relieve resource and environmental stress. Achieving sub-minute orchestration of renewables, storage, and loads, while minimizing PUE and lifecycle carbon intensity, hinges on accurate load forecasting. However, existing methods struggle to address small-sample scenarios caused by cold start, load distortion, multi-source data fragmentation, and distribution shifts in green data centers. We introduce HyperLoad, a cross-modality framework that exploits pre-trained large language models (LLMs) to overcome data scarcity. In the Cross-Modality Knowledge Alignment phase, textual priors and time-series data are mapped to a common latent space, maximizing the utility of prior knowledge. In the Multi-Scale Feature Modeling phase, domain-aligned priors are injected through adaptive prefix-tuning, enabling rapid scenario adaptation, while an Enhanced Global Interaction Attention mechanism captures cross-device temporal dependencies. The public DCData dataset is released for benchmarking. Under both data sufficient and data scarce settings, HyperLoad consistently surpasses state-of-the-art (SOTA) baselines, demonstrating its practicality for sustainable green data center management.
Cross-Attention Speculative Decoding
May 30, 2025Speculative decoding (SD) is a widely adopted approach for accelerating inference in large language models (LLMs), particularly when the draft and target models are well aligned. However, state-of-the-art SD methods typically rely on tightly coupled, self-attention-based Transformer decoders, often augmented with auxiliary pooling or fusion layers. This coupling makes them increasingly complex and harder to generalize across different models. We present Budget EAGLE (Beagle), the first, to our knowledge, cross-attention-based Transformer decoder SD model that achieves performance on par with leading self-attention SD models (EAGLE-v2) while eliminating the need for pooling or auxiliary components, simplifying the architecture, improving training efficiency, and maintaining stable memory usage during training-time simulation. To enable effective training of this novel architecture, we propose Two-Stage Block-Attention Training, a new method that achieves training stability and convergence efficiency in block-level attention scenarios. Extensive experiments across multiple LLMs and datasets show that Beagle achieves competitive inference speedups and higher training efficiency than EAGLE-v2, offering a strong alternative for architectures in speculative decoding.
Towards Long-Range ENSO Prediction with an Explainable Deep Learning Model
Mar 25, 2025El Ni\~no-Southern Oscillation (ENSO) is a prominent mode of interannual climate variability with far-reaching global impacts. Its evolution is governed by intricate air-sea interactions, posing significant challenges for long-term prediction. In this study, we introduce CTEFNet, a multivariate deep learning model that synergizes convolutional neural networks and transformers to enhance ENSO forecasting. By integrating multiple oceanic and atmospheric predictors, CTEFNet extends the effective forecast lead time to 20 months while mitigating the impact of the spring predictability barrier, outperforming both dynamical models and state-of-the-art deep learning approaches. Furthermore, CTEFNet offers physically meaningful and statistically significant insights through gradient-based sensitivity analysis, revealing the key precursor signals that govern ENSO dynamics, which align with well-established theories and reveal new insights about inter-basin interactions among the Pacific, Atlantic, and Indian Oceans. The CTEFNet's superior predictive skill and interpretable sensitivity assessments underscore its potential for advancing climate prediction. Our findings highlight the importance of multivariate coupling in ENSO evolution and demonstrate the promise of deep learning in capturing complex climate dynamics with enhanced interpretability.
Crime Forecasting: A Spatio-temporal Analysis with Deep Learning Models
Feb 11, 2025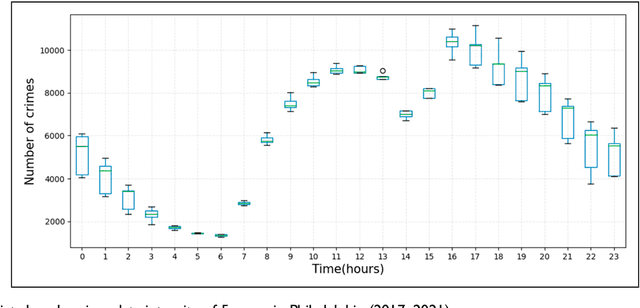
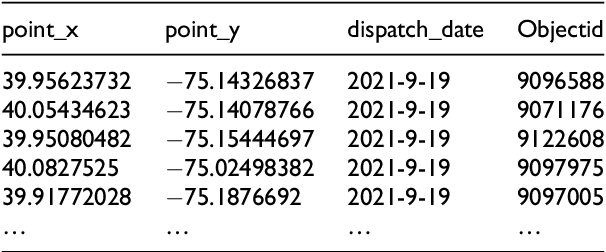
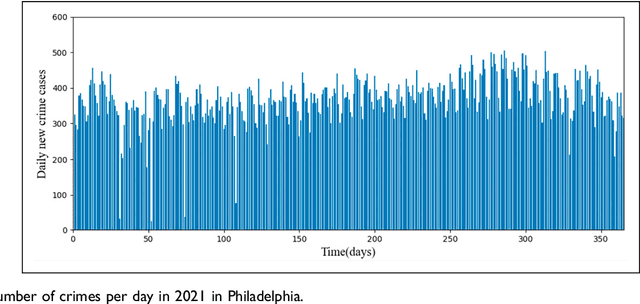
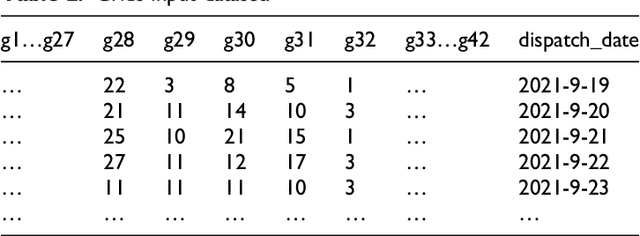
This study uses deep-learning models to predict city partition crime counts on specific days. It helps police enhance surveillance, gather intelligence, and proactively prevent crimes. We formulate crime count prediction as a spatiotemporal sequence challenge, where both input data and prediction targets are spatiotemporal sequences. In order to improve the accuracy of crime forecasting, we introduce a new model that combines Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks. We conducted a comparative analysis to access the effects of various data sequences, including raw and binned data, on the prediction errors of four deep learning forecasting models. Directly inputting raw crime data into the forecasting model causes high prediction errors, making the model unsuitable for real - world use. The findings indicate that the proposed CNN-LSTM model achieves optimal performance when crime data is categorized into 10 or 5 groups. Data binning can enhance forecasting model performance, but poorly defined intervals may reduce map granularity. Compared to dividing into 5 bins, binning into 10 intervals strikes an optimal balance, preserving data characteristics and surpassing raw data in predictive modelling efficacy.
Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption
Jan 18, 2025Infrared-visible image fusion (IVIF) is a critical task in computer vision, aimed at integrating the unique features of both infrared and visible spectra into a unified representation. Since 2018, the field has entered the deep learning era, with an increasing variety of approaches introducing a range of networks and loss functions to enhance visual performance. However, challenges such as data compatibility, perception accuracy, and efficiency remain. Unfortunately, there is a lack of recent comprehensive surveys that address this rapidly expanding domain. This paper fills that gap by providing a thorough survey covering a broad range of topics. We introduce a multi-dimensional framework to elucidate common learning-based IVIF methods, from visual enhancement strategies to data compatibility and task adaptability. We also present a detailed analysis of these approaches, accompanied by a lookup table clarifying their core ideas. Furthermore, we summarize performance comparisons, both quantitatively and qualitatively, focusing on registration, fusion, and subsequent high-level tasks. Beyond technical analysis, we discuss potential future directions and open issues in this area. For further details, visit our GitHub repository: https://github.com/RollingPlain/IVIF_ZOO.
PALMS: Parallel Adaptive Lasso with Multi-directional Signals for Latent Networks Reconstruction
Nov 18, 2024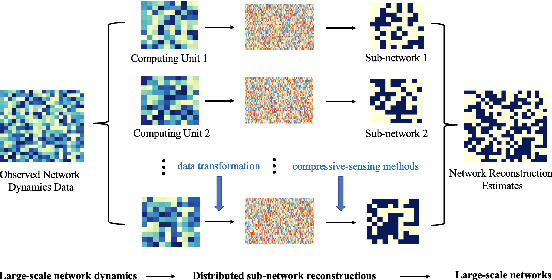

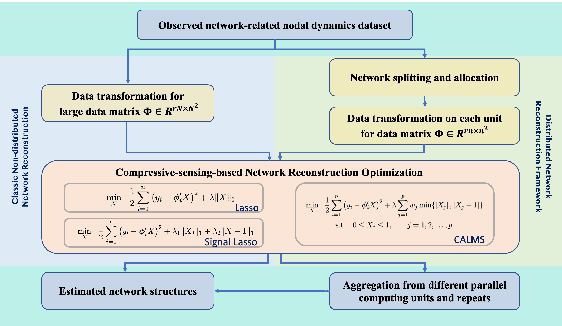
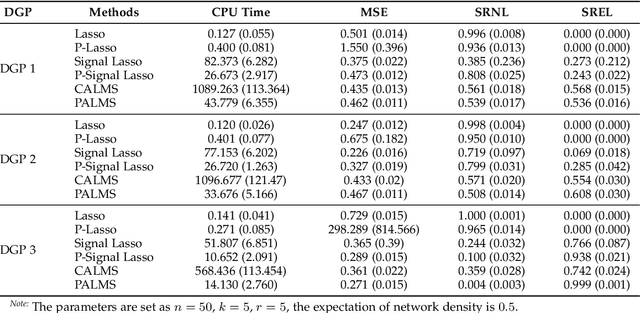
Large-scale networks exist in many field and play an important role in real-world dynamics. However, the networks are usually latent and expensive to detect, which becomes the main challenging for many applications and empirical analysis. Several statistical methods were proposed to infer the edges, but the complexity of algorithms make them hard to be applied for large-scale networks. In this paper, we proposed a general distributed and parallel computing framework for network reconstruction methods via compressive sensing technical, to make them feasible for inferring the super large networks in practice. Combining with the CALMS, we proposed for those estimators enjoy additional theoretical properties, such as the consistency and asymptotic normality, we prove that the approximate estimation utilizing the distributed algorithm can keep the theoretical results.
Risk Occupancy: A New and Efficient Paradigm through Vehicle-Road-Cloud Collaboration
Aug 14, 2024



This study introduces the 4D Risk Occupancy within a vehicle-road-cloud architecture, integrating the road surface spatial, risk, and temporal dimensions, and endowing the algorithm with beyond-line-of-sight, all-angles, and efficient abilities. The algorithm simplifies risk modeling by focusing on directly observable information and key factors, drawing on the concept of Occupancy Grid Maps (OGM), and incorporating temporal prediction to effectively map current and future risk occupancy. Compared to conventional driving risk fields and grid occupancy maps, this algorithm can map global risks more efficiently, simply, and reliably. It can integrate future risk information, adapting to dynamic traffic environments. The 4D Risk Occupancy also unifies the expression of BEV detection and lane line detection results, enhancing the intuitiveness and unity of environmental perception. Using DAIR-V2X data, this paper validates the 4D Risk Occupancy algorithm and develops a local path planning model based on it. Qualitative experiments under various road conditions demonstrate the practicality and robustness of this local path planning model. Quantitative analysis shows that the path planning based on risk occupation significantly improves trajectory planning performance, increasing safety redundancy by 12.5% and reducing average deceleration by 5.41% at an initial braking speed of 8 m/s, thereby improving safety and comfort. This work provides a new global perception method and local path planning method through Vehicle-Road-Cloud architecture, offering a new perceptual paradigm for achieving safer and more efficient autonomous driving.
S3D: A Simple and Cost-Effective Self-Speculative Decoding Scheme for Low-Memory GPUs
Jun 01, 2024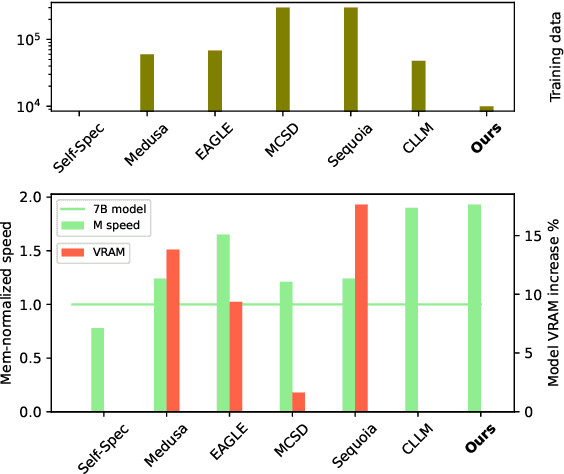
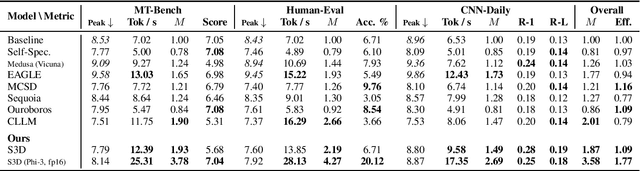
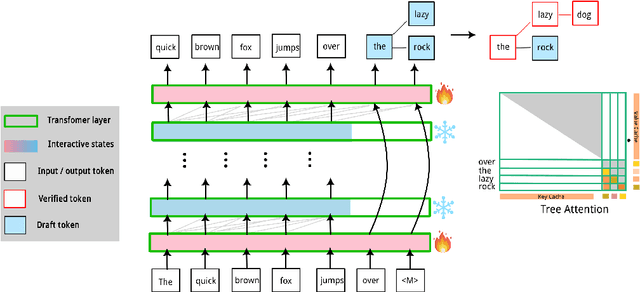
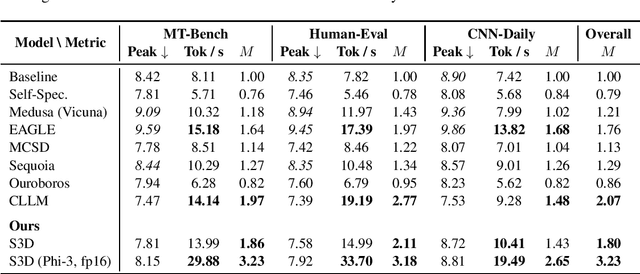
Speculative decoding (SD) has attracted a significant amount of research attention due to the substantial speedup it can achieve for LLM inference. However, despite the high speedups they offer, speculative decoding methods often achieve optimal performance on high-end devices or with a substantial GPU memory overhead. Given limited memory and the necessity of quantization, a high-performing model on a high-end GPU can slow down by up to 7 times. To this end, we propose Skippy Simultaneous Speculative Decoding (or S3D), a cost-effective self-speculative SD method based on simultaneous multi-token decoding and mid-layer skipping. When compared against recent effective open-source SD systems, our method has achieved one of the top performance-memory ratios while requiring minimal architecture changes and training data. Leveraging our memory efficiency, we created a smaller yet more effective SD model based on Phi-3. It is 1.4 to 2 times faster than the quantized EAGLE model and operates in half-precision while using less VRAM.