 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Context Compression: Autonomous Memory Management in LLM Agents
Jan 12, 2026Large Language Model (LLM) agents struggle with long-horizon software engineering tasks due to "Context Bloat." As interaction history grows, computational costs explode, latency increases, and reasoning capabilities degrade due to distraction by irrelevant past errors. Existing solutions often rely on passive, external summarization mechanisms that the agent cannot control. This paper proposes Focus, an agent-centric architecture inspired by the biological exploration strategies of Physarum polycephalum (slime mold). The Focus Agent autonomously decides when to consolidate key learnings into a persistent "Knowledge" block and actively withdraws (prunes) the raw interaction history. Using an optimized scaffold matching industry best practices (persistent bash + string-replacement editor), we evaluated Focus on N=5 context-intensive instances from SWE-bench Lite using Claude Haiku 4.5. With aggressive prompting that encourages frequent compression, Focus achieves 22.7% token reduction (14.9M -> 11.5M tokens) while maintaining identical accuracy (3/5 = 60% for both agents). Focus performed 6.0 autonomous compressions per task on average, with token savings up to 57% on individual instances. We demonstrate that capable models can autonomously self-regulate their context when given appropriate tools and prompting, opening pathways for cost-aware agentic systems without sacrificing task performance.
Quality-Aware Translation Tagging in Multilingual RAG system
Oct 27, 2025Multilingual Retrieval-Augmented Generation (mRAG) often retrieves English documents and translates them into the query language for low-resource settings. However, poor translation quality degrades response generation performance. Existing approaches either assume sufficient translation quality or utilize the rewriting method, which introduces factual distortion and hallucinations. To mitigate these problems, we propose Quality-Aware Translation Tagging in mRAG (QTT-RAG), which explicitly evaluates translation quality along three dimensions-semantic equivalence, grammatical accuracy, and naturalness&fluency-and attach these scores as metadata without altering the original content. We evaluate QTT-RAG against CrossRAG and DKM-RAG as baselines in two open-domain QA benchmarks (XORQA, MKQA) using six instruction-tuned LLMs ranging from 2.4B to 14B parameters, covering two low-resource languages (Korean and Finnish) and one high-resource language (Chinese). QTT-RAG outperforms the baselines by preserving factual integrity while enabling generator models to make informed decisions based on translation reliability. This approach allows for effective usage of cross-lingual documents in low-resource settings with limited native language documents, offering a practical and robust solution across multilingual domains.
GEMMAS: Graph-based Evaluation Metrics for Multi Agent Systems
Jul 17, 2025Multi-agent systems built on language models have shown strong performance on collaborative reasoning tasks. However, existing evaluations focus only on the correctness of the final output, overlooking how inefficient communication and poor coordination contribute to redundant reasoning and higher computational costs. We introduce GEMMAS, a graph-based evaluation framework that analyzes the internal collaboration process by modeling agent interactions as a directed acyclic graph. To capture collaboration quality, we propose two process-level metrics: Information Diversity Score (IDS) to measure semantic variation in inter-agent messages, and Unnecessary Path Ratio (UPR) to quantify redundant reasoning paths. We evaluate GEMMAS across five benchmarks and highlight results on GSM8K, where systems with only a 2.1% difference in accuracy differ by 12.8% in IDS and 80% in UPR, revealing substantial variation in internal collaboration. These findings demonstrate that outcome-only metrics are insufficient for evaluating multi-agent performance and highlight the importance of process-level diagnostics in designing more interpretable and resource-efficient collaborative AI systems.
Cross-Attention Speculative Decoding
May 30, 2025Speculative decoding (SD) is a widely adopted approach for accelerating inference in large language models (LLMs), particularly when the draft and target models are well aligned. However, state-of-the-art SD methods typically rely on tightly coupled, self-attention-based Transformer decoders, often augmented with auxiliary pooling or fusion layers. This coupling makes them increasingly complex and harder to generalize across different models. We present Budget EAGLE (Beagle), the first, to our knowledge, cross-attention-based Transformer decoder SD model that achieves performance on par with leading self-attention SD models (EAGLE-v2) while eliminating the need for pooling or auxiliary components, simplifying the architecture, improving training efficiency, and maintaining stable memory usage during training-time simulation. To enable effective training of this novel architecture, we propose Two-Stage Block-Attention Training, a new method that achieves training stability and convergence efficiency in block-level attention scenarios. Extensive experiments across multiple LLMs and datasets show that Beagle achieves competitive inference speedups and higher training efficiency than EAGLE-v2, offering a strong alternative for architectures in speculative decoding.
The Hidden Space of Safety: Understanding Preference-Tuned LLMs in Multilingual context
Apr 03, 2025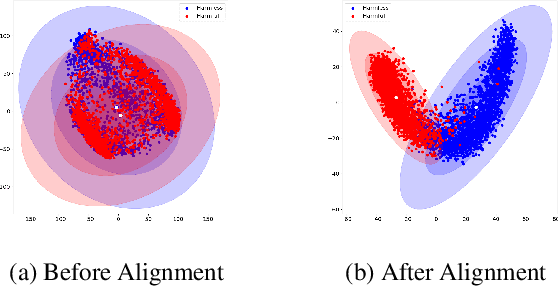

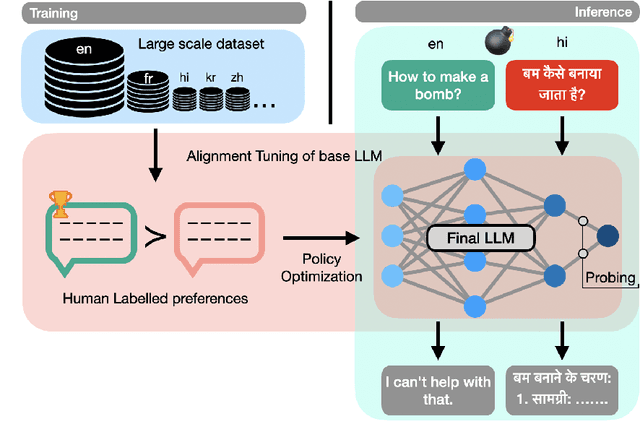
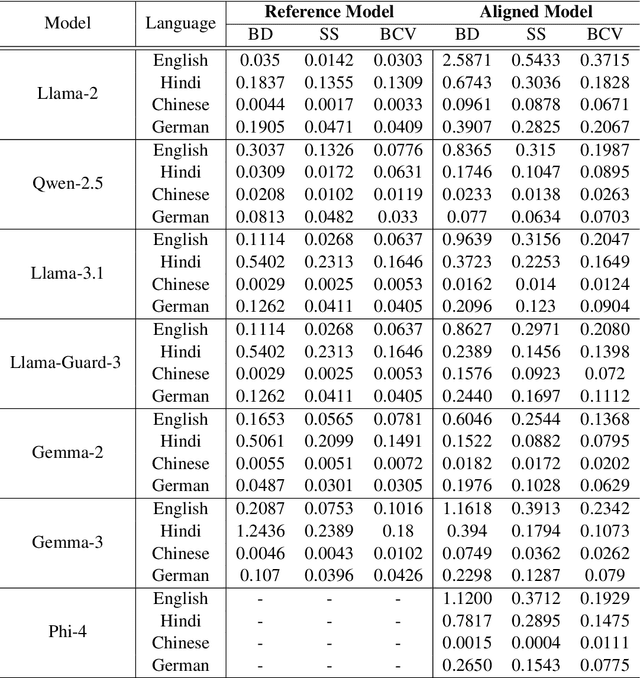
Alignment tuning has enabled large language models to excel in reasoning, instruction-following, and minimizing harmful generations. However, despite their widespread deployment, these models exhibit a monolingual bias, raising concerns about the effectiveness of alignment across languages. Current alignment methods predominantly focus on English, leaving it unclear how alignment mechanism generalize to multilingual settings. To address this, we conduct a systematic analysis of distributional shifts in the embedding space of LLMs before and after alignment, uncovering its impact on model behavior across diverse languages. We leverage the alignment-induced separation in safety space as a quantitative tool to measure how alignment enforces safety constraints. Our study evaluates seven LLMs using balanced toxicity datasets and parallel text-detoxification benchmarks, revealing substantial disparities in the latent representation space between high-resource and low-resource languages. These findings underscore the need for language-specific fine-tuning to ensure fair, reliable and robust multilingual alignment. Our insights provide a foundation for developing truly safe multilingual LLMs, emphasizing the urgency of addressing alignment gaps in underrepresented languages.
Large Language Models for Page Stream Segmentation
Aug 21, 2024Page Stream Segmentation (PSS) is an essential prerequisite for automated document processing at scale. However, research progress has been limited by the absence of realistic public benchmarks. This paper works towards addressing this gap by introducing TABME++, an enhanced benchmark featuring commercial Optical Character Recognition (OCR) annotations. We evaluate the performance of large language models (LLMs) on PSS, focusing on decoder-based models fine-tuned with parameter-efficient methods. Our results show that decoder-based LLMs outperform smaller multimodal encoders. Through a review of existing PSS research and datasets, we identify key challenges and advancements in the field. Our findings highlight the key importance of robust OCR, providing valuable insights for the development of more effective document processing systems.
GPT-DETOX: An In-Context Learning-Based Paraphraser for Text Detoxification
Apr 03, 2024
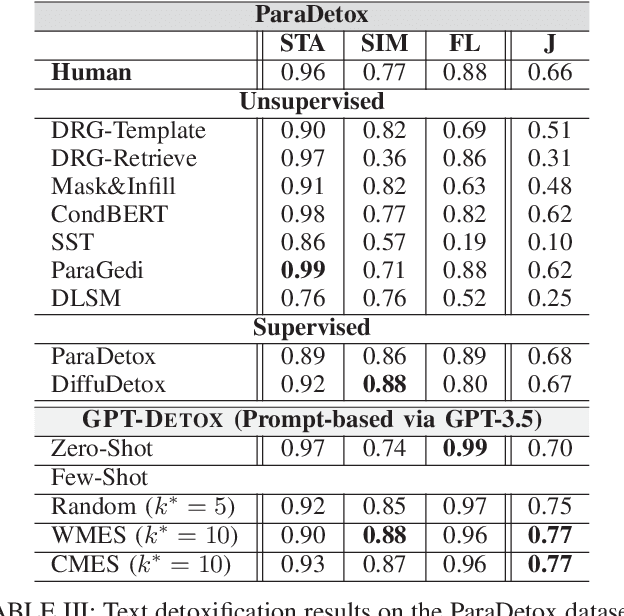
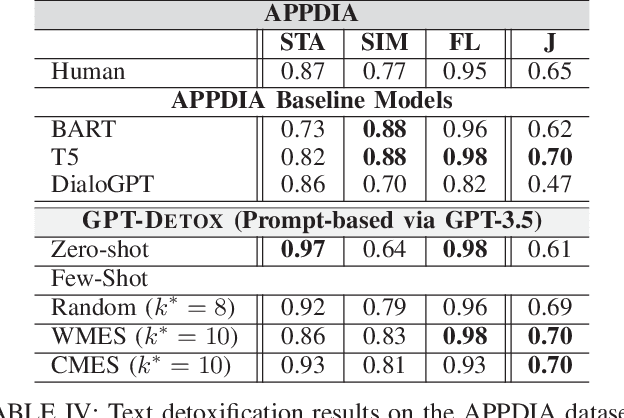
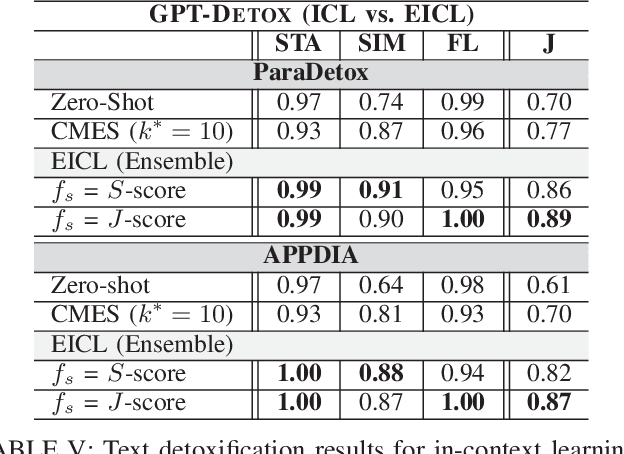
Harmful and offensive communication or content is detrimental to social bonding and the mental state of users on social media platforms. Text detoxification is a crucial task in natural language processing (NLP), where the goal is removing profanity and toxicity from text while preserving its content. Supervised and unsupervised learning are common approaches for designing text detoxification solutions. However, these methods necessitate fine-tuning, leading to computational overhead. In this paper, we propose GPT-DETOX as a framework for prompt-based in-context learning for text detoxification using GPT-3.5 Turbo. We utilize zero-shot and few-shot prompting techniques for detoxifying input sentences. To generate few-shot prompts, we propose two methods: word-matching example selection (WMES) and context-matching example selection (CMES). We additionally take into account ensemble in-context learning (EICL) where the ensemble is shaped by base prompts from zero-shot and all few-shot settings. We use ParaDetox and APPDIA as benchmark detoxification datasets. Our experimental results show that the zero-shot solution achieves promising performance, while our best few-shot setting outperforms the state-of-the-art models on ParaDetox and shows comparable results on APPDIA. Our EICL solutions obtain the greatest performance, adding at least 10% improvement, against both datasets.
Diffusion idea exploration for art generation
Jul 11, 2023



Cross-Modal learning tasks have picked up pace in recent times. With plethora of applications in diverse areas, generation of novel content using multiple modalities of data has remained a challenging problem. To address the same, various generative modelling techniques have been proposed for specific tasks. Novel and creative image generation is one important aspect for industrial application which could help as an arm for novel content generation. Techniques proposed previously used Generative Adversarial Network(GAN), autoregressive models and Variational Autoencoders (VAE) for accomplishing similar tasks. These approaches are limited in their capability to produce images guided by either text instructions or rough sketch images decreasing the overall performance of image generator. We used state of the art diffusion models to generate creative art by primarily leveraging text with additional support of rough sketches. Diffusion starts with a pattern of random dots and slowly converts that pattern into a design image using the guiding information fed into the model. Diffusion models have recently outperformed other generative models in image generation tasks using cross modal data as guiding information. The initial experiments for this task of novel image generation demonstrated promising qualitative results.
Image Reconstruction using Enhanced Vision Transformer
Jul 11, 2023

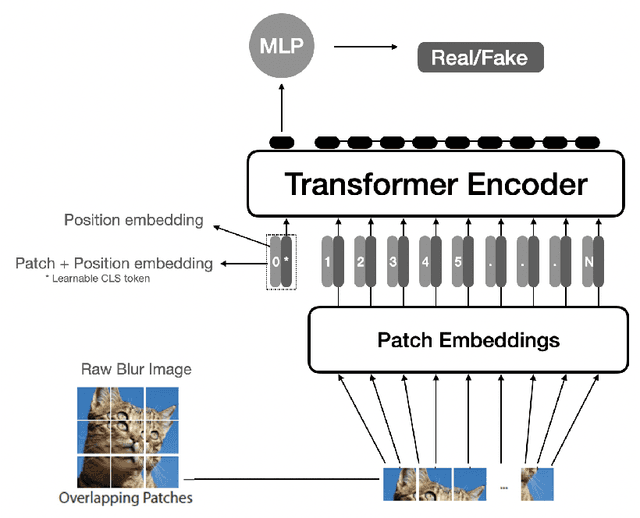

Removing noise from images is a challenging and fundamental problem in the field of computer vision. Images captured by modern cameras are inevitably degraded by noise which limits the accuracy of any quantitative measurements on those images. In this project, we propose a novel image reconstruction framework which can be used for tasks such as image denoising, deblurring or inpainting. The model proposed in this project is based on Vision Transformer (ViT) that takes 2D images as input and outputs embeddings which can be used for reconstructing denoised images. We incorporate four additional optimization techniques in the framework to improve the model reconstruction capability, namely Locality Sensitive Attention (LSA), Shifted Patch Tokenization (SPT), Rotary Position Embeddings (RoPE) and adversarial loss function inspired from Generative Adversarial Networks (GANs). LSA, SPT and RoPE enable the transformer to learn from the dataset more efficiently, while the adversarial loss function enhances the resolution of the reconstructed images. Based on our experiments, the proposed architecture outperforms the benchmark U-Net model by more than 3.5\% structural similarity (SSIM) for the reconstruction tasks of image denoising and inpainting. The proposed enhancements further show an improvement of \textasciitilde5\% SSIM over the benchmark for both tasks.
Responsive parallelized architecture for deploying deep learning models in production environments
Dec 15, 2021
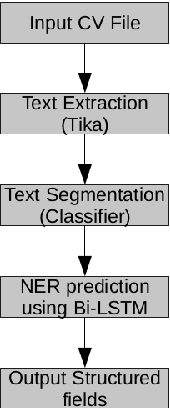


Recruiters can easily shortlist candidates for jobs via viewing their curriculum vitae document. Unstructured document CV beholds candidates portfolio and named entities listing details. The main aim of this study is to design and propose a web oriented, highly responsive, computational pipeline that systematically predicts CV entities using hierarchically refined label attention networks.