 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Reconstruction using Enhanced Vision Transformer
Jul 11, 2023

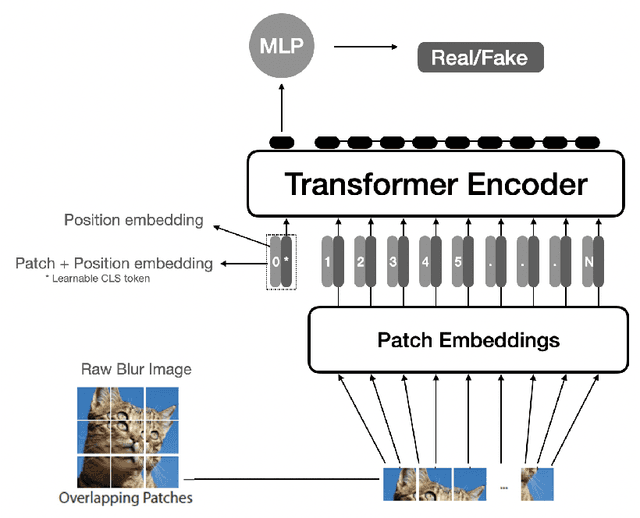

Removing noise from images is a challenging and fundamental problem in the field of computer vision. Images captured by modern cameras are inevitably degraded by noise which limits the accuracy of any quantitative measurements on those images. In this project, we propose a novel image reconstruction framework which can be used for tasks such as image denoising, deblurring or inpainting. The model proposed in this project is based on Vision Transformer (ViT) that takes 2D images as input and outputs embeddings which can be used for reconstructing denoised images. We incorporate four additional optimization techniques in the framework to improve the model reconstruction capability, namely Locality Sensitive Attention (LSA), Shifted Patch Tokenization (SPT), Rotary Position Embeddings (RoPE) and adversarial loss function inspired from Generative Adversarial Networks (GANs). LSA, SPT and RoPE enable the transformer to learn from the dataset more efficiently, while the adversarial loss function enhances the resolution of the reconstructed images. Based on our experiments, the proposed architecture outperforms the benchmark U-Net model by more than 3.5\% structural similarity (SSIM) for the reconstruction tasks of image denoising and inpainting. The proposed enhancements further show an improvement of \textasciitilde5\% SSIM over the benchmark for both tasks.