 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaker LLMs' Opinions Also Matter: Mixture of Opinions Enhances LLM's Mathematical Reasoning
Feb 26, 2025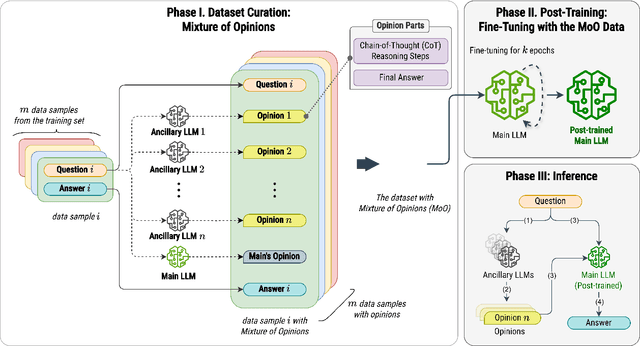
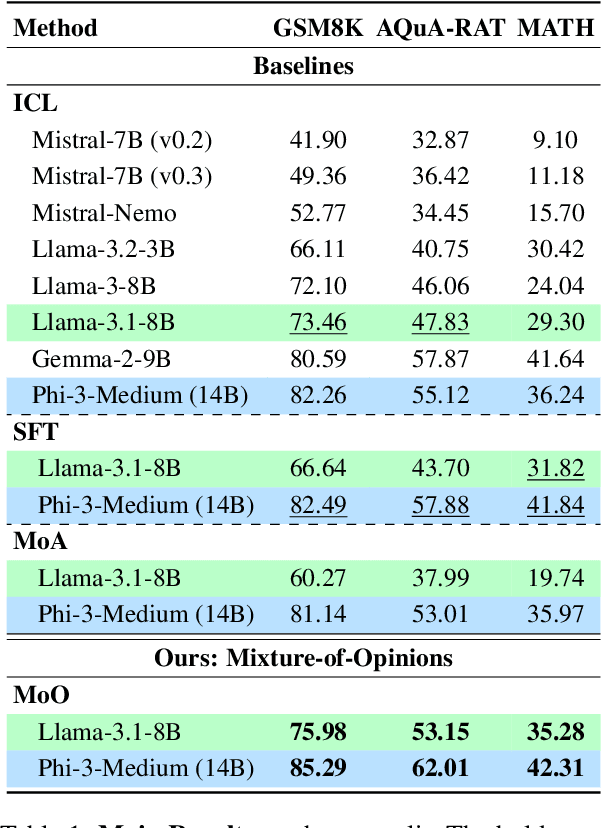
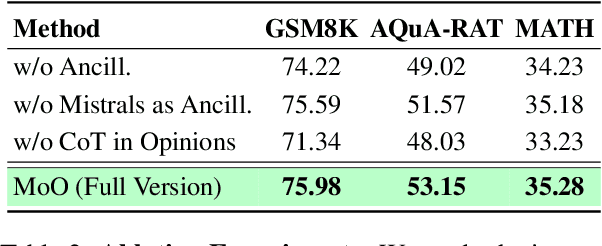
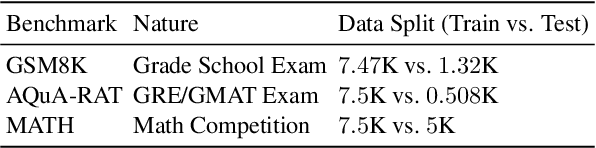
Recent advances in Large Language Models (LLMs) have raised interest in their formal reasoning capabilities, particularly in mathematics. While closed LLMs like GPT-4 perform well on mathematical benchmarks, e.g., GSM8K, it remains unclear whether small to medium-sized open LLMs can achieve similar performance, questioning their reliability. To close this gap, we propose a post-training approach leveraging a mixture of opinions (MoO) from weaker ancillary LLMs to enhance a (relatively) stronger LLM's reasoning. For that, each post-training sample is augmented with Chain-of-Thought (CoT) reasoning steps and answers from ancillary LLMs, enabling the main LLM to learn from diverse perspectives. We compare MoO with standard supervised fine-tuning (SFT), few-shot prompting, and the Mixture of Agents (MoA) method on mathematical reasoning benchmarks. Our results show that incorporating weaker LLMs' opinions improves mathematical reasoning by an average of 5%, highlighting the value of diverse perspectives in reasoning tasks.
Athena: Safe Autonomous Agents with Verbal Contrastive Learning
Aug 20, 2024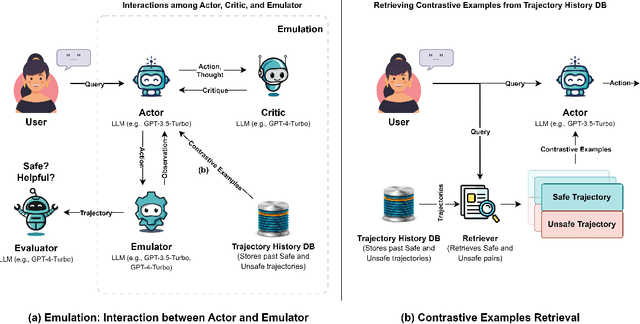
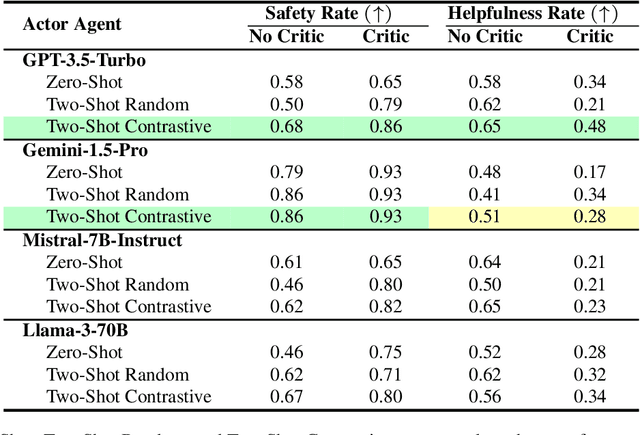
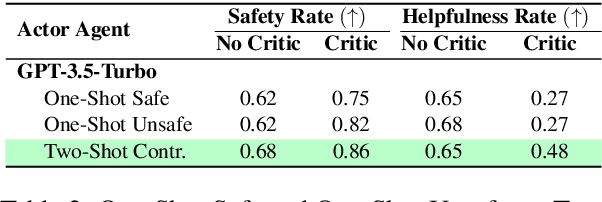
Due to emergent capabilities, large language models (LLMs) have been utilized as language-based agents to perform a variety of tasks and make decisions with an increasing degree of autonomy. These autonomous agents can understand high-level instructions, interact with their environments, and execute complex tasks using a selection of tools available to them. As the capabilities of the agents expand, ensuring their safety and trustworthiness becomes more imperative. In this study, we introduce the Athena framework which leverages the concept of verbal contrastive learning where past safe and unsafe trajectories are used as in-context (contrastive) examples to guide the agent towards safety while fulfilling a given task. The framework also incorporates a critiquing mechanism to guide the agent to prevent risky actions at every step. Furthermore, due to the lack of existing benchmarks on the safety reasoning ability of LLM-based agents, we curate a set of 80 toolkits across 8 categories with 180 scenarios to provide a safety evaluation benchmark. Our experimental evaluation, with both closed- and open-source LLMs, indicates verbal contrastive learning and interaction-level critiquing improve the safety rate significantly.
Can We Rely on LLM Agents to Draft Long-Horizon Plans? Let's Take TravelPlanner as an Example
Aug 12, 2024Large language models (LLMs) have brought autonomous agents closer to artificial general intelligence (AGI) due to their promising generalization and emergent capabilities. There is, however, a lack of studies on how LLM-based agents behave, why they could potentially fail, and how to improve them, particularly in demanding real-world planning tasks. In this paper, as an effort to fill the gap, we present our study using a realistic benchmark, TravelPlanner, where an agent must meet multiple constraints to generate accurate plans. We leverage this benchmark to address four key research questions: (1) are LLM agents robust enough to lengthy and noisy contexts when it comes to reasoning and planning? (2) can few-shot prompting adversely impact the performance of LLM agents in scenarios with long context? (3) can we rely on refinement to improve plans, and (4) can fine-tuning LLMs with both positive and negative feedback lead to further improvement? Our comprehensive experiments indicate that, firstly, LLMs often fail to attend to crucial parts of a long context, despite their ability to handle extensive reference information and few-shot examples; secondly, they still struggle with analyzing the long plans and cannot provide accurate feedback for refinement; thirdly, we propose Feedback-Aware Fine-Tuning (FAFT), which leverages both positive and negative feedback, resulting in substantial gains over Supervised Fine-Tuning (SFT). Our findings offer in-depth insights to the community on various aspects related to real-world planning applications.
GPT-DETOX: An In-Context Learning-Based Paraphraser for Text Detoxification
Apr 03, 2024
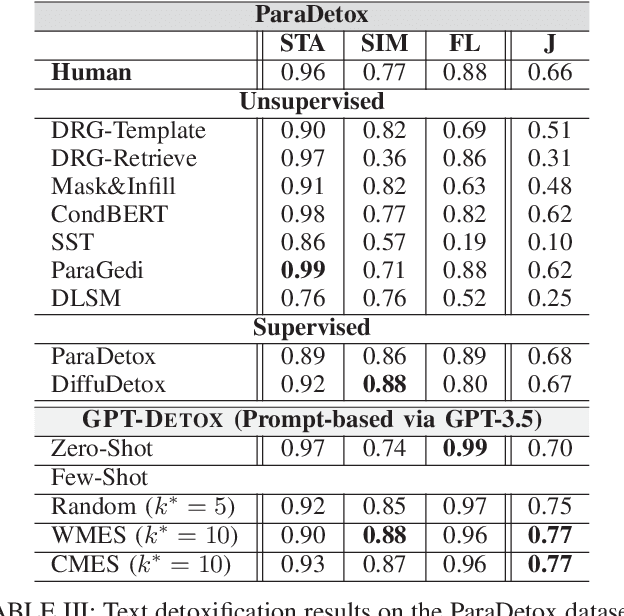
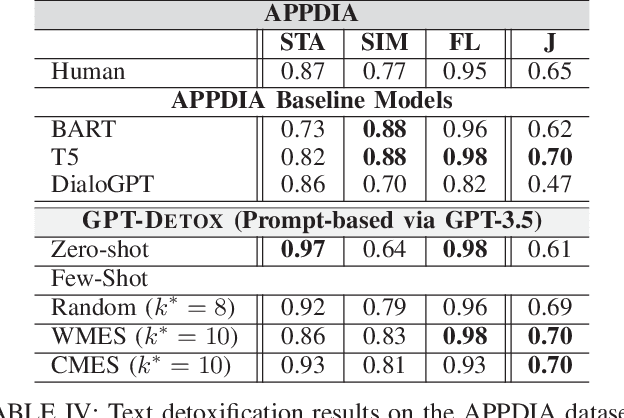
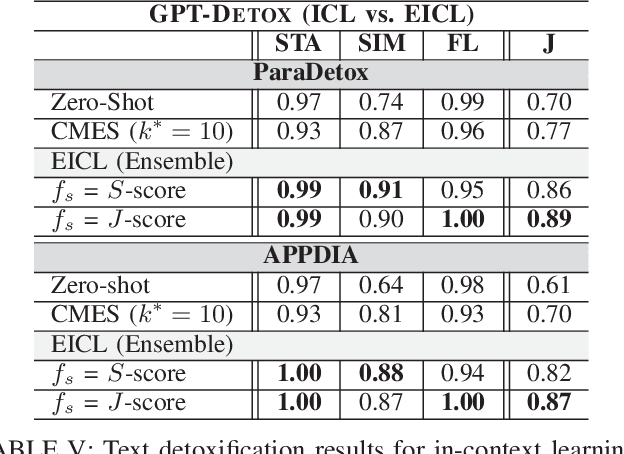
Harmful and offensive communication or content is detrimental to social bonding and the mental state of users on social media platforms. Text detoxification is a crucial task in natural language processing (NLP), where the goal is removing profanity and toxicity from text while preserving its content. Supervised and unsupervised learning are common approaches for designing text detoxification solutions. However, these methods necessitate fine-tuning, leading to computational overhead. In this paper, we propose GPT-DETOX as a framework for prompt-based in-context learning for text detoxification using GPT-3.5 Turbo. We utilize zero-shot and few-shot prompting techniques for detoxifying input sentences. To generate few-shot prompts, we propose two methods: word-matching example selection (WMES) and context-matching example selection (CMES). We additionally take into account ensemble in-context learning (EICL) where the ensemble is shaped by base prompts from zero-shot and all few-shot settings. We use ParaDetox and APPDIA as benchmark detoxification datasets. Our experimental results show that the zero-shot solution achieves promising performance, while our best few-shot setting outperforms the state-of-the-art models on ParaDetox and shows comparable results on APPDIA. Our EICL solutions obtain the greatest performance, adding at least 10% improvement, against both datasets.
RECipe: Does a Multi-Modal Recipe Knowledge Graph Fit a Multi-Purpose Recommendation System?
Aug 08, 2023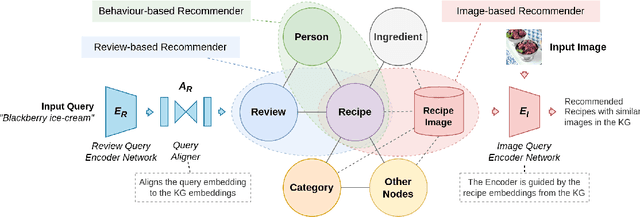
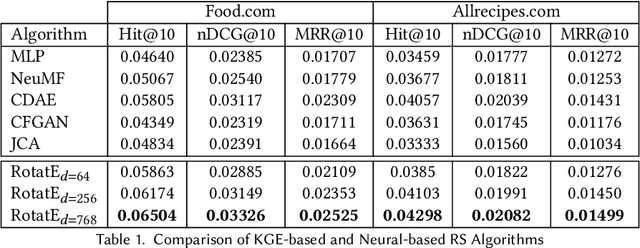
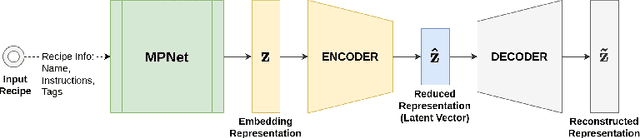
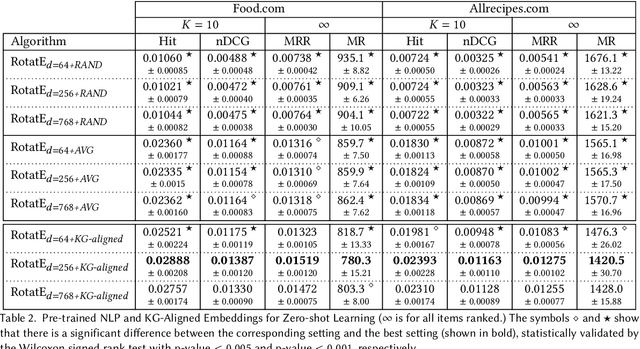
Over the past two decades, recommendation systems (RSs) have used machine learning (ML) solutions to recommend items, e.g., movies, books, and restaurants, to clients of a business or an online platform. Recipe recommendation, however, has not yet received much attention compared to those applications. We introduce RECipe as a multi-purpose recipe recommendation framework with a multi-modal knowledge graph (MMKG) backbone. The motivation behind RECipe is to go beyond (deep) neural collaborative filtering (NCF) by recommending recipes to users when they query in natural language or by providing an image. RECipe consists of 3 subsystems: (1) behavior-based recommender, (2) review-based recommender, and (3) image-based recommender. Each subsystem relies on the embedding representations of entities and relations in the graph. We first obtain (pre-trained) embedding representations of textual entities, such as reviews or ingredients, from a fine-tuned model of Microsoft's MPNet. We initialize the weights of the entities with these embeddings to train our knowledge graph embedding (KGE) model. For the visual component, i.e., recipe images, we develop a KGE-Guided variational autoencoder (KG-VAE) to learn the distribution of images and their latent representations. Once KGE and KG-VAE models are fully trained, we use them as a multi-purpose recommendation framework. For benchmarking, we created two knowledge graphs (KGs) from public datasets on Kaggle for recipe recommendation. Our experiments show that the KGE models have comparable performance to the neural solutions. We also present pre-trained NLP embeddings to address important applications such as zero-shot inference for new users (or the cold start problem) and conditional recommendation with respect to recipe categories. We eventually demonstrate the application of RECipe in a multi-purpose recommendation setting.
Self-Supervised Contrastive BERT Fine-tuning for Fusion-based Reviewed-Item Retrieval
Aug 01, 2023As natural language interfaces enable users to express increasingly complex natural language queries, there is a parallel explosion of user review content that can allow users to better find items such as restaurants, books, or movies that match these expressive queries. While Neural Information Retrieval (IR) methods have provided state-of-the-art results for matching queries to documents, they have not been extended to the task of Reviewed-Item Retrieval (RIR), where query-review scores must be aggregated (or fused) into item-level scores for ranking. In the absence of labeled RIR datasets, we extend Neural IR methodology to RIR by leveraging self-supervised methods for contrastive learning of BERT embeddings for both queries and reviews. Specifically, contrastive learning requires a choice of positive and negative samples, where the unique two-level structure of our item-review data combined with meta-data affords us a rich structure for the selection of these samples. For contrastive learning in a Late Fusion scenario, we investigate the use of positive review samples from the same item and/or with the same rating, selection of hard positive samples by choosing the least similar reviews from the same anchor item, and selection of hard negative samples by choosing the most similar reviews from different items. We also explore anchor sub-sampling and augmenting with meta-data. For a more end-to-end Early Fusion approach, we introduce contrastive item embedding learning to fuse reviews into single item embeddings. Experimental results show that Late Fusion contrastive learning for Neural RIR outperforms all other contrastive IR configurations, Neural IR, and sparse retrieval baselines, thus demonstrating the power of exploiting the two-level structure in Neural RIR approaches as well as the importance of preserving the nuance of individual review content via Late Fusion methods.
DiffuDetox: A Mixed Diffusion Model for Text Detoxification
Jun 14, 2023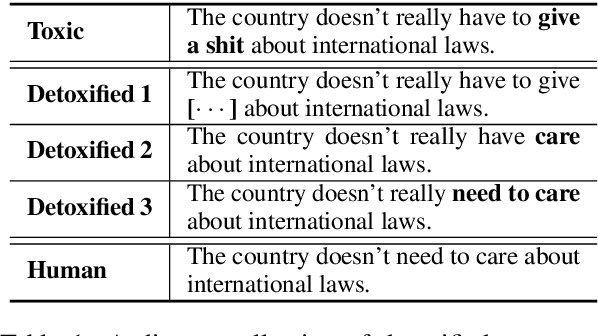
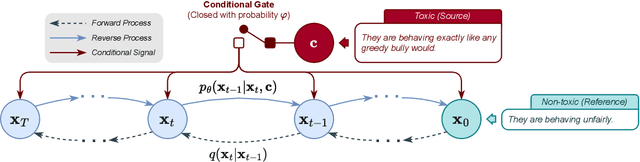
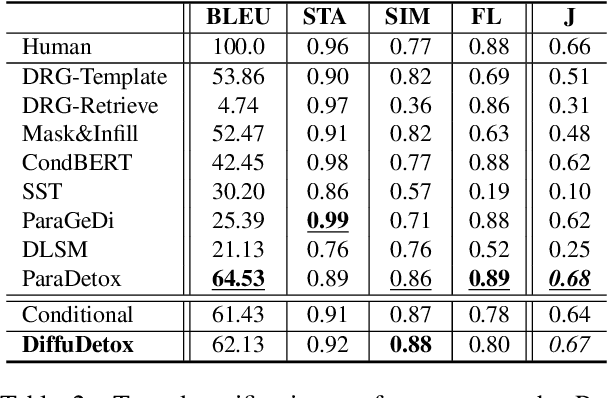
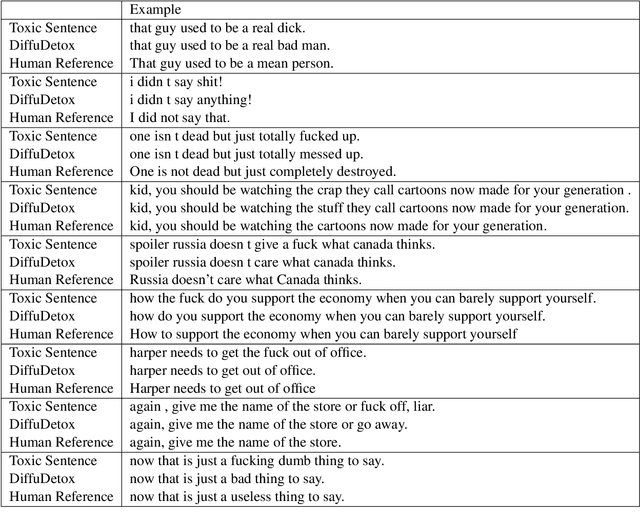
Text detoxification is a conditional text generation task aiming to remove offensive content from toxic text. It is highly useful for online forums and social media, where offensive content is frequently encountered. Intuitively, there are diverse ways to detoxify sentences while preserving their meanings, and we can select from detoxified sentences before displaying text to users. Conditional diffusion models are particularly suitable for this task given their demonstrated higher generative diversity than existing conditional text generation models based on language models. Nonetheless, text fluency declines when they are trained with insufficient data, which is the case for this task. In this work, we propose DiffuDetox, a mixed conditional and unconditional diffusion model for text detoxification. The conditional model takes toxic text as the condition and reduces its toxicity, yielding a diverse set of detoxified sentences. The unconditional model is trained to recover the input text, which allows the introduction of additional fluent text for training and thus ensures text fluency. Extensive experimental results and in-depth analysis demonstrate the effectiveness of our proposed DiffuDetox.
One Single Deep Bidirectional LSTM Network for Word Sense Disambiguation of Text Data
Feb 25, 2018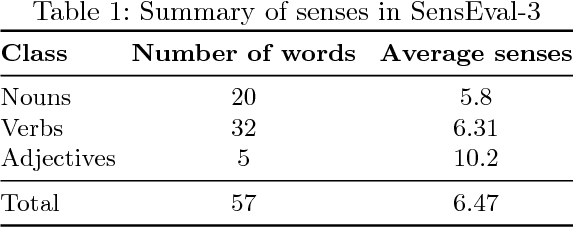
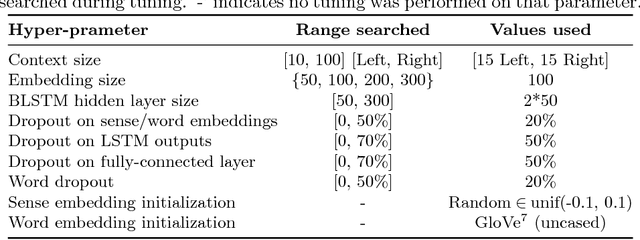


Due to recent technical and scientific advances, we have a wealth of information hidden in unstructured text data such as offline/online narratives, research articles, and clinical reports. To mine these data properly, attributable to their innate ambiguity, a Word Sense Disambiguation (WSD) algorithm can avoid numbers of difficulties in Natural Language Processing (NLP) pipeline. However, considering a large number of ambiguous words in one language or technical domain, we may encounter limiting constraints for proper deployment of existing WSD models. This paper attempts to address the problem of one-classifier-per-one-word WSD algorithms by proposing a single Bidirectional Long Short-Term Memory (BLSTM) network which by considering senses and context sequences works on all ambiguous words collectively. Evaluated on SensEval-3 benchmark, we show the result of our model is comparable with top-performing WSD algorithms. We also discuss how applying additional modifications alleviates the model fault and the need for more training data.
McDiarmid Drift Detection Methods for Evolving Data Streams
Jan 17, 2018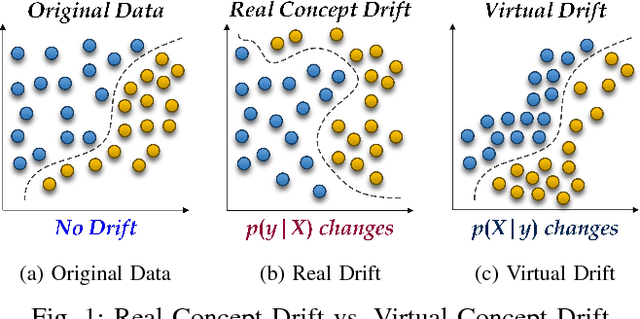
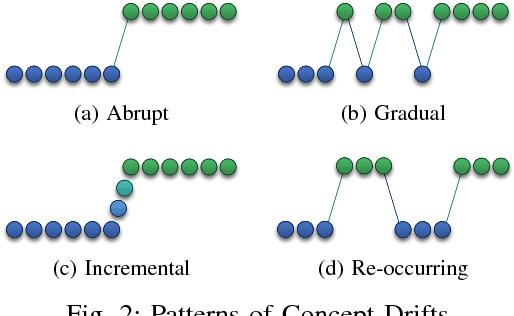
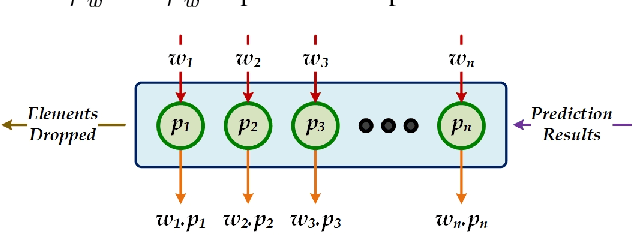
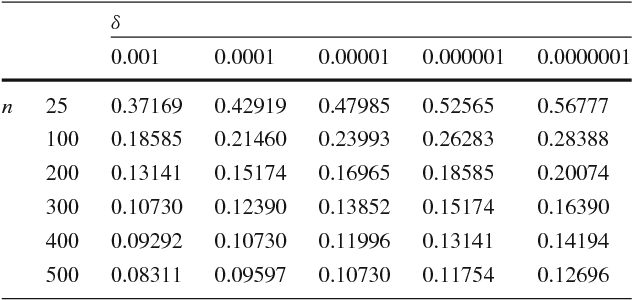
Increasingly, Internet of Things (IoT) domains, such as sensor networks, smart cities, and social networks, generate vast amounts of data. Such data are not only unbounded and rapidly evolving. Rather, the content thereof dynamically evolves over time, often in unforeseen ways. These variations are due to so-called concept drifts, caused by changes in the underlying data generation mechanisms. In a classification setting, concept drift causes the previously learned models to become inaccurate, unsafe and even unusable. Accordingly, concept drifts need to be detected, and handled, as soon as possible. In medical applications and emergency response settings, for example, change in behaviours should be detected in near real-time, to avoid potential loss of life. To this end, we introduce the McDiarmid Drift Detection Method (MDDM), which utilizes McDiarmid's inequality in order to detect concept drift. The MDDM approach proceeds by sliding a window over prediction results, and associate window entries with weights. Higher weights are assigned to the most recent entries, in order to emphasize their importance. As instances are processed, the detection algorithm compares a weighted mean of elements inside the sliding window with the maximum weighted mean observed so far. A significant difference between the two weighted means, upper-bounded by the McDiarmid inequality, implies a concept drift. Our extensive experimentation against synthetic and real-world data streams show that our novel method outperforms the state-of-the-art. Specifically, MDDM yields shorter detection delays as well as lower false negative rates, while maintaining high classification accuracies.
Reservoir of Diverse Adaptive Learners and Stacking Fast Hoeffding Drift Detection Methods for Evolving Data Streams
Sep 07, 2017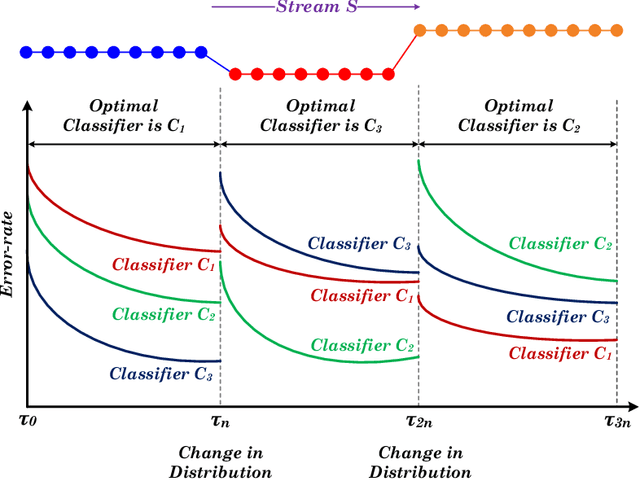
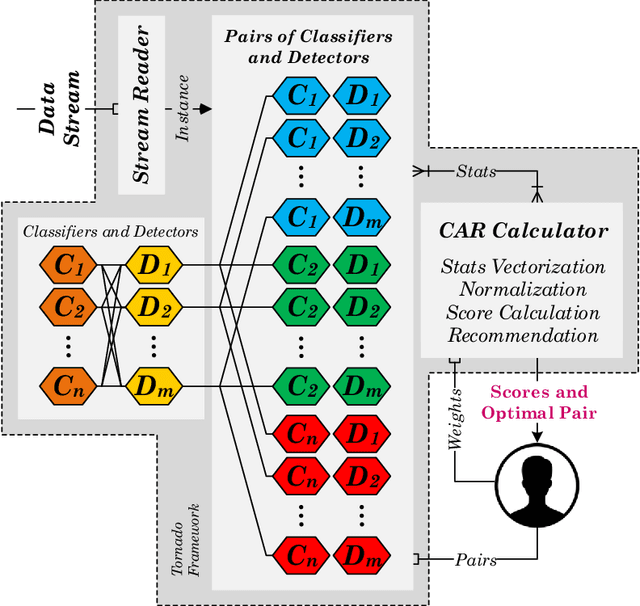
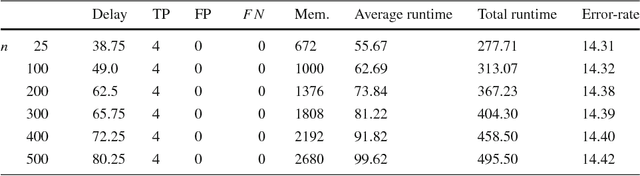
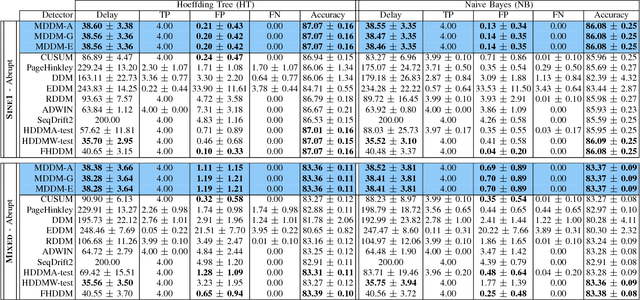
The last decade has seen a surge of interest in adaptive learning algorithms for data stream classification, with applications ranging from predicting ozone level peaks, learning stock market indicators, to detecting computer security violations. In addition, a number of methods have been developed to detect concept drifts in these streams. Consider a scenario where we have a number of classifiers with diverse learning styles and different drift detectors. Intuitively, the current 'best' (classifier, detector) pair is application dependent and may change as a result of the stream evolution. Our research builds on this observation. We introduce the $\mbox{Tornado}$ framework that implements a reservoir of diverse classifiers, together with a variety of drift detection algorithms. In our framework, all (classifier, detector) pairs proceed, in parallel, to construct models against the evolving data streams. At any point in time, we select the pair which currently yields the best performance. We further incorporate two novel stacking-based drift detection methods, namely the $\mbox{FHDDMS}$ and $\mbox{FHDDMS}_{add}$ approaches. The experimental evaluation confirms that the current 'best' (classifier, detector) pair is not only heavily dependent on the characteristics of the stream, but also that this selection evolves as the stream flows. Further, our $\mbox{FHDDMS}$ variants detect concept drifts accurately in a timely fashion while outperforming the state-of-the-art.