 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Sharpness: A Flatness Decomposition Framework for Efficient Continual Learning
Jan 12, 2026Continual Learning (CL) aims to enable models to sequentially learn multiple tasks without forgetting previous knowledge. Recent studies have shown that optimizing towards flatter loss minima can improve model generalization. However, existing sharpness-aware methods for CL suffer from two key limitations: (1) they treat sharpness regularization as a unified signal without distinguishing the contributions of its components. and (2) they introduce substantial computational overhead that impedes practical deployment. To address these challenges, we propose FLAD, a novel optimization framework that decomposes sharpness-aware perturbations into gradient-aligned and stochastic-noise components, and show that retaining only the noise component promotes generalization. We further introduce a lightweight scheduling scheme that enables FLAD to maintain significant performance gains even under constrained training time. FLAD can be seamlessly integrated into various CL paradigms and consistently outperforms standard and sharpness-aware optimizers in diverse experimental settings, demonstrating its effectiveness and practicality in CL.
Weaker LLMs' Opinions Also Matter: Mixture of Opinions Enhances LLM's Mathematical Reasoning
Feb 26, 2025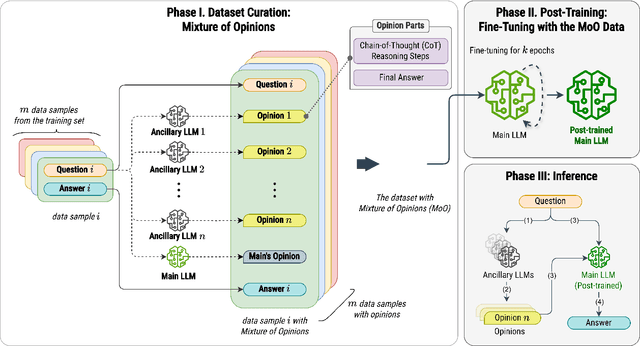
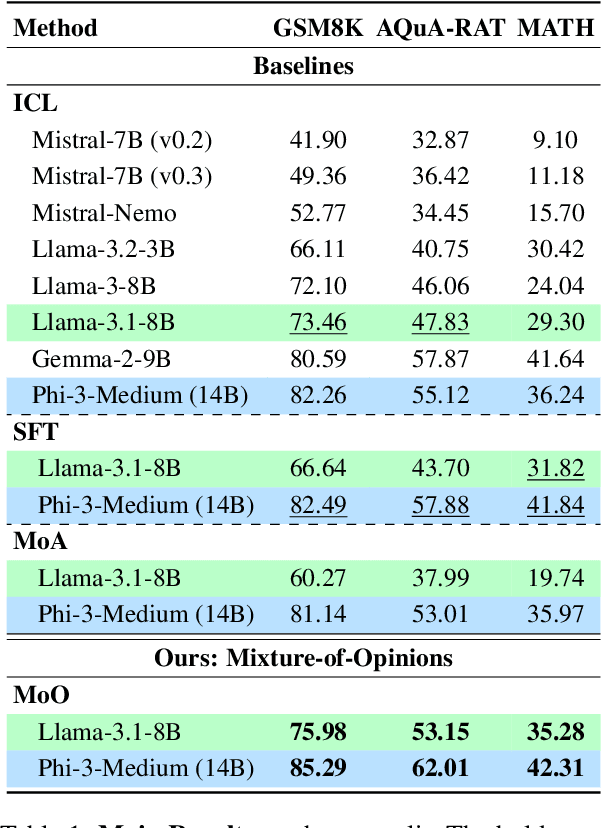
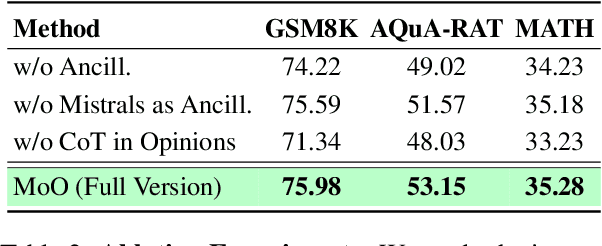
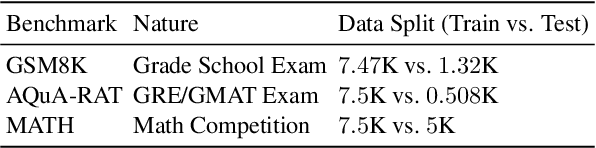
Recent advances in Large Language Models (LLMs) have raised interest in their formal reasoning capabilities, particularly in mathematics. While closed LLMs like GPT-4 perform well on mathematical benchmarks, e.g., GSM8K, it remains unclear whether small to medium-sized open LLMs can achieve similar performance, questioning their reliability. To close this gap, we propose a post-training approach leveraging a mixture of opinions (MoO) from weaker ancillary LLMs to enhance a (relatively) stronger LLM's reasoning. For that, each post-training sample is augmented with Chain-of-Thought (CoT) reasoning steps and answers from ancillary LLMs, enabling the main LLM to learn from diverse perspectives. We compare MoO with standard supervised fine-tuning (SFT), few-shot prompting, and the Mixture of Agents (MoA) method on mathematical reasoning benchmarks. Our results show that incorporating weaker LLMs' opinions improves mathematical reasoning by an average of 5%, highlighting the value of diverse perspectives in reasoning tasks.
A Fuzzy-based Approach to Predict Human Interaction by Functional Near-Infrared Spectroscopy
Sep 26, 2024



The paper introduces a Fuzzy-based Attention (Fuzzy Attention Layer) mechanism, a novel computational approach to enhance the interpretability and efficacy of neural models in psychological research. The proposed Fuzzy Attention Layer mechanism is integrated as a neural network layer within the Transformer Encoder model to facilitate the analysis of complex psychological phenomena through neural signals, such as those captured by functional Near-Infrared Spectroscopy (fNIRS). By leveraging fuzzy logic, the Fuzzy Attention Layer is capable of learning and identifying interpretable patterns of neural activity. This capability addresses a significant challenge when using Transformer: the lack of transparency in determining which specific brain activities most contribute to particular predictions. Our experimental results demonstrated on fNIRS data from subjects engaged in social interactions involving handholding reveal that the Fuzzy Attention Layer not only learns interpretable patterns of neural activity but also enhances model performance. Additionally, the learned patterns provide deeper insights into the neural correlates of interpersonal touch and emotional exchange. The application of our model shows promising potential in deciphering the subtle complexities of human social behaviors, thereby contributing significantly to the fields of social neuroscience and psychological AI.
Athena: Safe Autonomous Agents with Verbal Contrastive Learning
Aug 20, 2024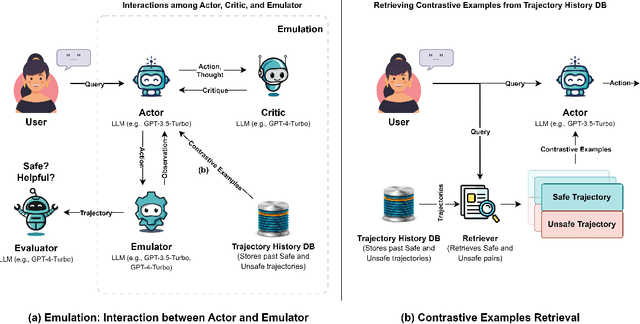
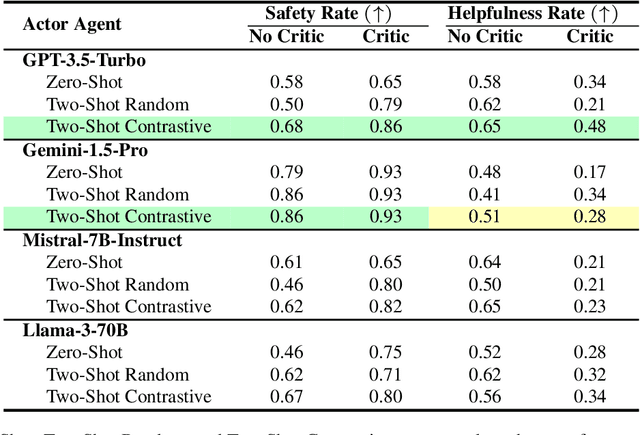
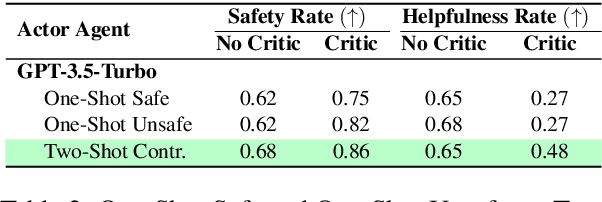
Due to emergent capabilities, large language models (LLMs) have been utilized as language-based agents to perform a variety of tasks and make decisions with an increasing degree of autonomy. These autonomous agents can understand high-level instructions, interact with their environments, and execute complex tasks using a selection of tools available to them. As the capabilities of the agents expand, ensuring their safety and trustworthiness becomes more imperative. In this study, we introduce the Athena framework which leverages the concept of verbal contrastive learning where past safe and unsafe trajectories are used as in-context (contrastive) examples to guide the agent towards safety while fulfilling a given task. The framework also incorporates a critiquing mechanism to guide the agent to prevent risky actions at every step. Furthermore, due to the lack of existing benchmarks on the safety reasoning ability of LLM-based agents, we curate a set of 80 toolkits across 8 categories with 180 scenarios to provide a safety evaluation benchmark. Our experimental evaluation, with both closed- and open-source LLMs, indicates verbal contrastive learning and interaction-level critiquing improve the safety rate significantly.
Can We Rely on LLM Agents to Draft Long-Horizon Plans? Let's Take TravelPlanner as an Example
Aug 12, 2024Large language models (LLMs) have brought autonomous agents closer to artificial general intelligence (AGI) due to their promising generalization and emergent capabilities. There is, however, a lack of studies on how LLM-based agents behave, why they could potentially fail, and how to improve them, particularly in demanding real-world planning tasks. In this paper, as an effort to fill the gap, we present our study using a realistic benchmark, TravelPlanner, where an agent must meet multiple constraints to generate accurate plans. We leverage this benchmark to address four key research questions: (1) are LLM agents robust enough to lengthy and noisy contexts when it comes to reasoning and planning? (2) can few-shot prompting adversely impact the performance of LLM agents in scenarios with long context? (3) can we rely on refinement to improve plans, and (4) can fine-tuning LLMs with both positive and negative feedback lead to further improvement? Our comprehensive experiments indicate that, firstly, LLMs often fail to attend to crucial parts of a long context, despite their ability to handle extensive reference information and few-shot examples; secondly, they still struggle with analyzing the long plans and cannot provide accurate feedback for refinement; thirdly, we propose Feedback-Aware Fine-Tuning (FAFT), which leverages both positive and negative feedback, resulting in substantial gains over Supervised Fine-Tuning (SFT). Our findings offer in-depth insights to the community on various aspects related to real-world planning applications.
Plugin Speech Enhancement: A Universal Speech Enhancement Framework Inspired by Dynamic Neural Network
Feb 20, 2024The expectation to deploy a universal neural network for speech enhancement, with the aim of improving noise robustness across diverse speech processing tasks, faces challenges due to the existing lack of awareness within static speech enhancement frameworks regarding the expected speech in downstream modules. These limitations impede the effectiveness of static speech enhancement approaches in achieving optimal performance for a range of speech processing tasks, thereby challenging the notion of universal applicability. The fundamental issue in achieving universal speech enhancement lies in effectively informing the speech enhancement module about the features of downstream modules. In this study, we present a novel weighting prediction approach, which explicitly learns the task relationships from downstream training information to address the core challenge of universal speech enhancement. We found the role of deciding whether to employ data augmentation techniques as crucial downstream training information. This decision significantly impacts the expected speech and the performance of the speech enhancement module. Moreover, we introduce a novel speech enhancement network, the Plugin Speech Enhancement (Plugin-SE). The Plugin-SE is a dynamic neural network that includes the speech enhancement module, gate module, and weight prediction module. Experimental results demonstrate that the proposed Plugin-SE approach is competitive or superior to other joint training methods across various downstream tasks.
Harmonic gated compensation network plus for ICASSP 2022 DNS CHALLENGE
Feb 25, 2022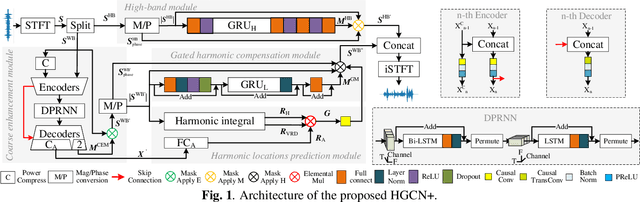

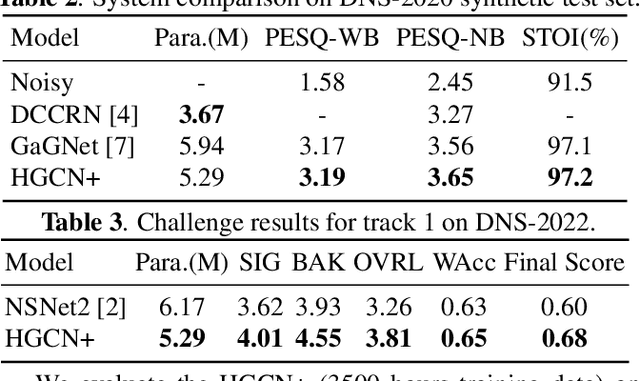
The harmonic structure of speech is resistant to noise, but the harmonics may still be partially masked by noise. Therefore, we previously proposed a harmonic gated compensation network (HGCN) to predict the full harmonic locations based on the unmasked harmonics and process the result of a coarse enhancement module to recover the masked harmonics. In addition, the auditory loudness loss function is used to train the network. For the DNS Challenge, we update HGCN with the following aspects, resulting in HGCN+. First, a high-band module is employed to help the model handle full-band signals. Second, cosine is used to model the harmonic structure more accurately. Then, the dual-path encoder and dual-path rnn (DPRNN) are introduced to take full advantage of the features. Finally, a gated residual linear structure replaces the gated convolution in the compensation module to increase the receptive field of frequency. The experimental results show that each updated module brings performance improvement to the model. HGCN+ also outperforms the referenced models on both wide-band and full-band test sets.