 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaker LLMs' Opinions Also Matter: Mixture of Opinions Enhances LLM's Mathematical Reasoning
Paper and Code
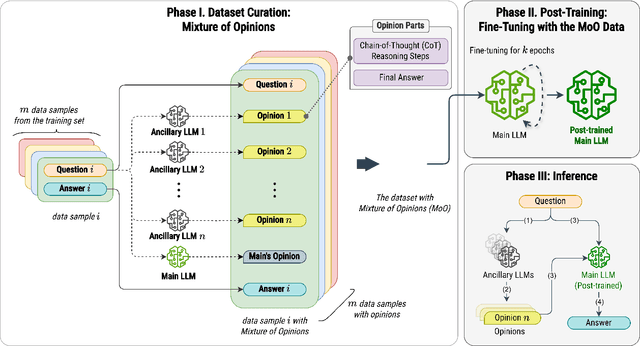
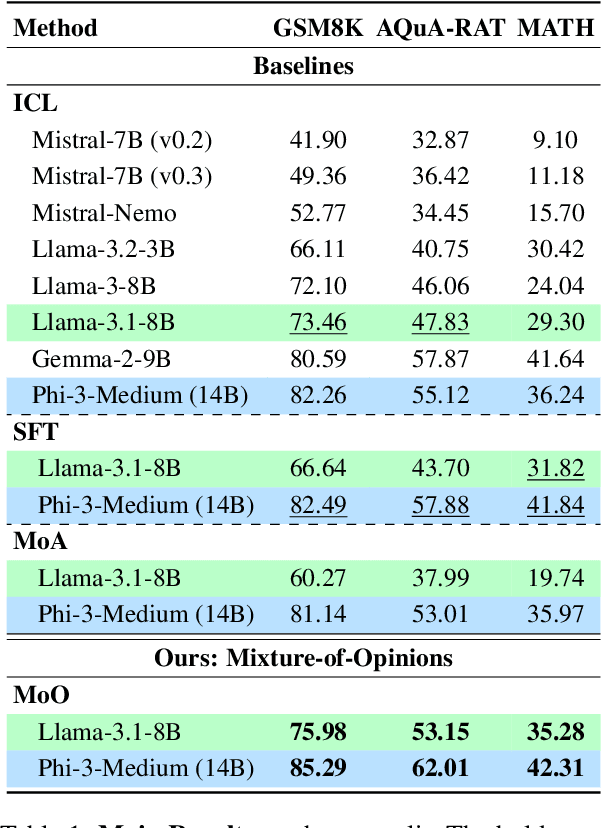
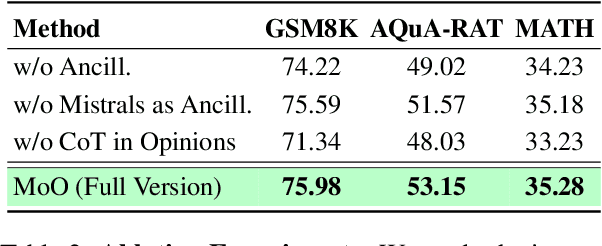
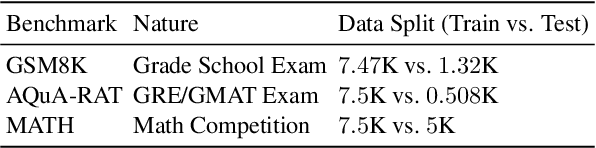
Recent advances in Large Language Models (LLMs) have raised interest in their formal reasoning capabilities, particularly in mathematics. While closed LLMs like GPT-4 perform well on mathematical benchmarks, e.g., GSM8K, it remains unclear whether small to medium-sized open LLMs can achieve similar performance, questioning their reliability. To close this gap, we propose a post-training approach leveraging a mixture of opinions (MoO) from weaker ancillary LLMs to enhance a (relatively) stronger LLM's reasoning. For that, each post-training sample is augmented with Chain-of-Thought (CoT) reasoning steps and answers from ancillary LLMs, enabling the main LLM to learn from diverse perspectives. We compare MoO with standard supervised fine-tuning (SFT), few-shot prompting, and the Mixture of Agents (MoA) method on mathematical reasoning benchmarks. Our results show that incorporating weaker LLMs' opinions improves mathematical reasoning by an average of 5%, highlighting the value of diverse perspectives in reasoning tasks.