 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adapter based Multi-label Pre-training for Speech Separation and Enhancement
Nov 11, 2022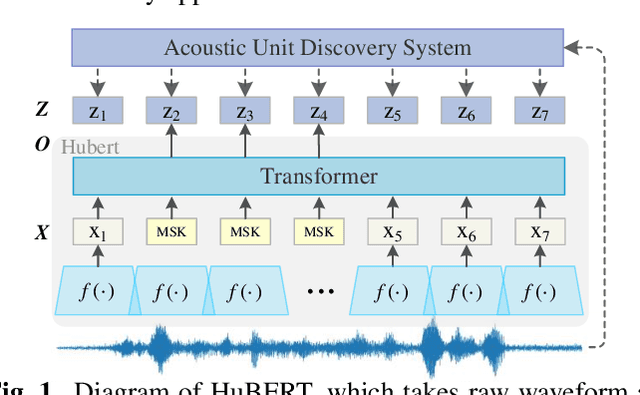

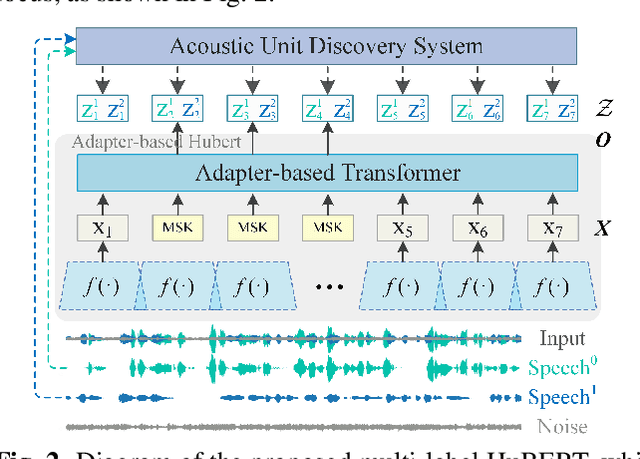
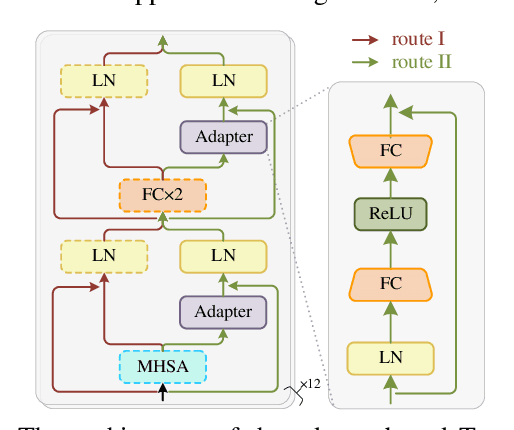
In recent years, self-supervised learning (SSL) has achieved tremendous success in various speech tasks due to its power to extract representations from massive unlabeled data. However, compared with tasks such as speech recognition (ASR), the improvements from SSL representation in speech separation (SS) and enhancement (SE) are considerably smaller. Based on HuBERT, this work investigates improving the SSL model for SS and SE. We first update HuBERT's masked speech prediction (MSP) objective by integrating the separation and denoising terms, resulting in a multiple pseudo label pre-training scheme, which significantly improves HuBERT's performance on SS and SE but degrades the performance on ASR. To maintain its performance gain on ASR, we further propose an adapter-based architecture for HuBERT's Transformer encoder, where only a few parameters of each layer are adjusted to the multiple pseudo label MSP while other parameters remain frozen as default HuBERT. Experimental results show that our proposed adapter-based multiple pseudo label HuBERT yield consistent and significant performance improvements on SE, SS, and ASR tasks, with a faster pre-training speed, at only marginal parameters increase.
Multiple Confidence Gates For Joint Training Of SE And ASR
Apr 01, 2022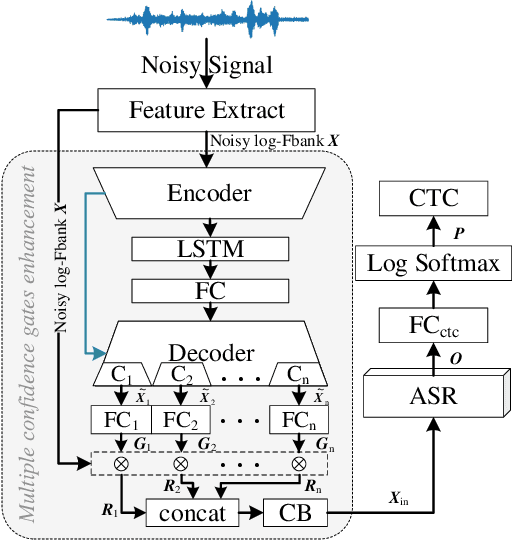
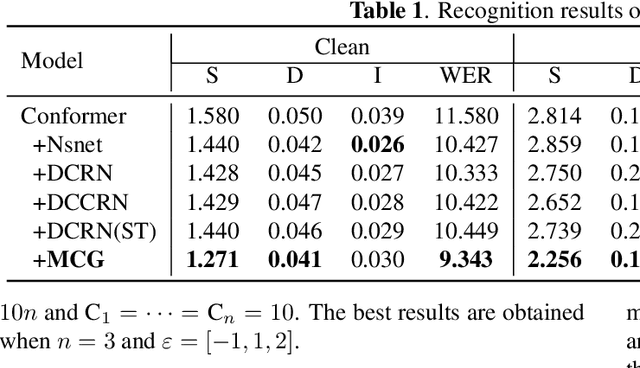
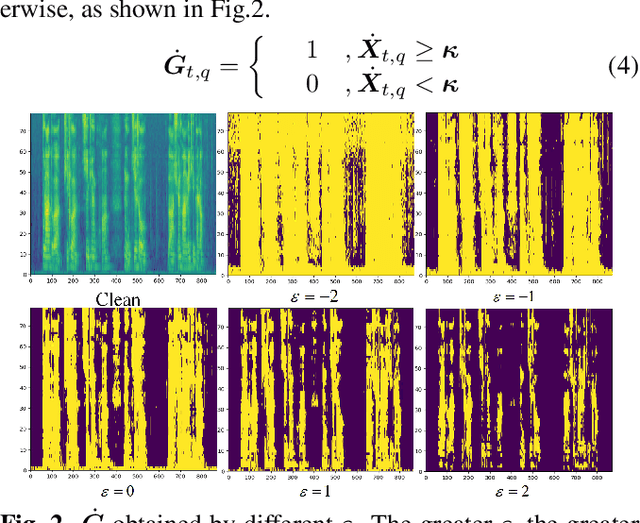
Joint training of speech enhancement model (SE) and speech recognition model (ASR) is a common solution for robust ASR in noisy environments. SE focuses on improving the auditory quality of speech, but the enhanced feature distribution is changed, which is uncertain and detrimental to the ASR. To tackle this challenge, an approach with multiple confidence gates for jointly training of SE and ASR is proposed. A speech confidence gates prediction module is designed to replace the former SE module in joint training. The noisy speech is filtered by gates to obtain features that are easier to be fitting by the ASR network. The experimental results show that the proposed method has better performance than the traditional robust speech recognition system on test sets of clean speech, synthesized noisy speech, and real noisy speech.
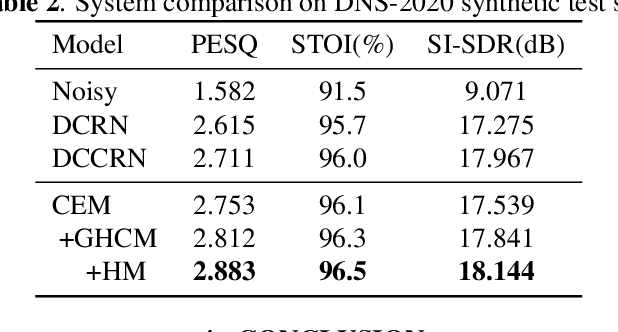
Harmonic gated compensation network plus for ICASSP 2022 DNS CHALLENGE
Feb 25, 2022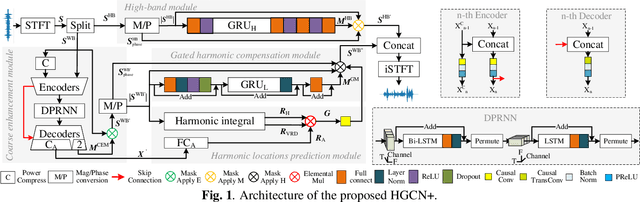
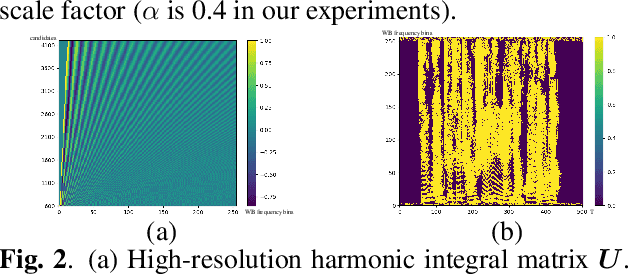

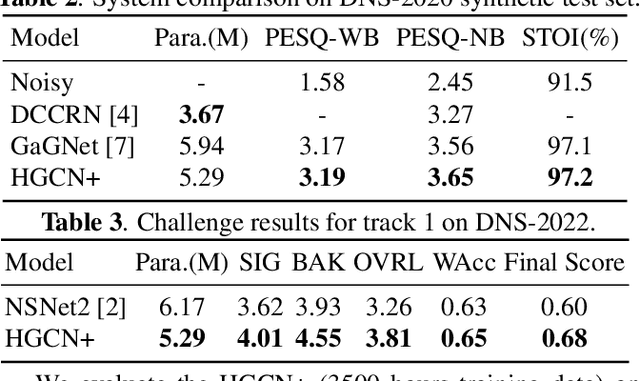
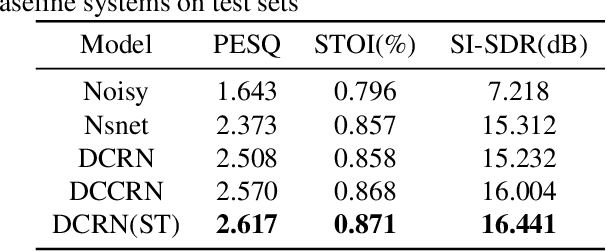
The harmonic structure of speech is resistant to noise, but the harmonics may still be partially masked by noise. Therefore, we previously proposed a harmonic gated compensation network (HGCN) to predict the full harmonic locations based on the unmasked harmonics and process the result of a coarse enhancement module to recover the masked harmonics. In addition, the auditory loudness loss function is used to train the network. For the DNS Challenge, we update HGCN with the following aspects, resulting in HGCN+. First, a high-band module is employed to help the model handle full-band signals. Second, cosine is used to model the harmonic structure more accurately. Then, the dual-path encoder and dual-path rnn (DPRNN) are introduced to take full advantage of the features. Finally, a gated residual linear structure replaces the gated convolution in the compensation module to increase the receptive field of frequency. The experimental results show that each updated module brings performance improvement to the model. HGCN+ also outperforms the referenced models on both wide-band and full-band test sets.
HGCN: harmonic gated compensation network for speech enhancement
Jan 30, 2022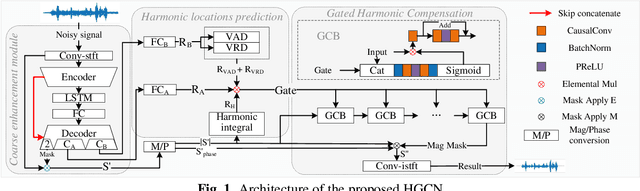
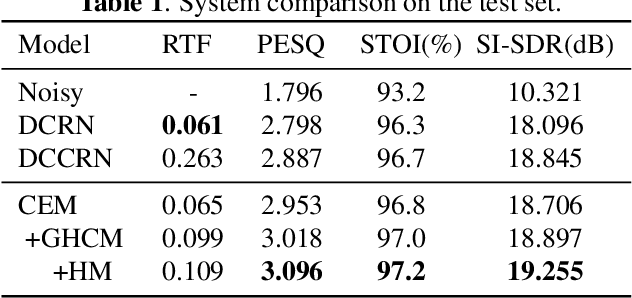
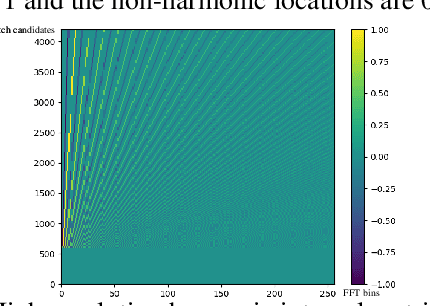
Mask processing in the time-frequency (T-F) domain through the neural network has been one of the mainstreams for single-channel speech enhancement. However, it is hard for most models to handle the situation when harmonics are partially masked by noise. To tackle this challenge, we propose a harmonic gated compensation network (HGCN). We design a high-resolution harmonic integral spectrum to improve the accuracy of harmonic locations prediction. Then we add voice activity detection (VAD) and voiced region detection (VRD) to the convolutional recurrent network (CRN) to filter harmonic locations. Finally, the harmonic gating mechanism is used to guide the compensation model to adjust the coarse results from CRN to obtain the refinedly enhanced results. Our experiments show HGCN achieves substantial gain over a number of advanced approaches in the community.
A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement
Aug 27, 2021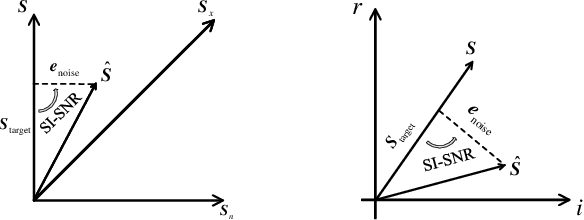
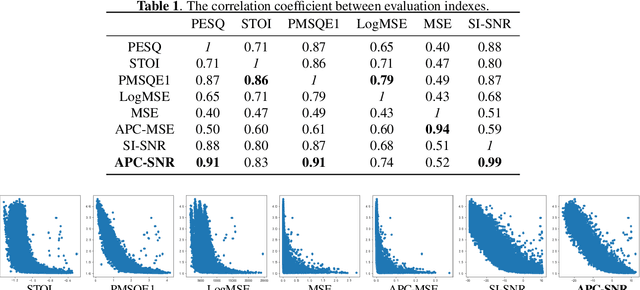
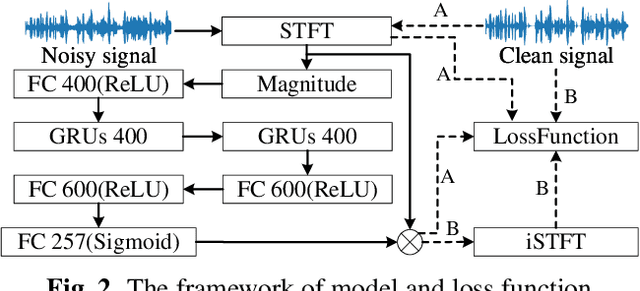
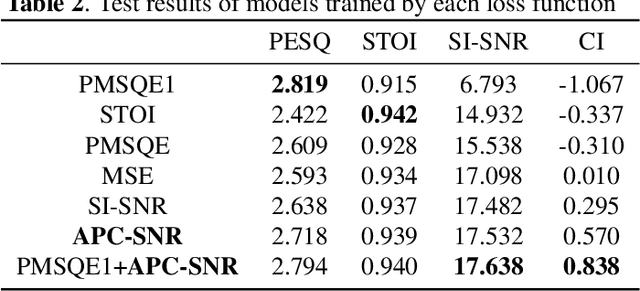
Deep learning technology has been widely applied to speech enhancement. While testing the effectiveness of various network structures, researchers are also exploring the improvement of the loss function used in network training. Although the existing methods have considered the auditory characteristics of speech or the reasonable expression of signal-to-noise ratio, the correlation with the auditory evaluation score and the applicability of the calculation for gradient optimization still need to be improved. In this paper, a signal-to-noise ratio loss function based on auditory power compression is proposed. The experimental results show that the overall correlation between the proposed function and the indexes of objective speech intelligibility, which is better than other loss functions. For the same speech enhancement model, the training effect of this method is also better than other comparison methods.