 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Confidence Gates For Joint Training Of SE And ASR
Paper and Code
Apr 01, 2022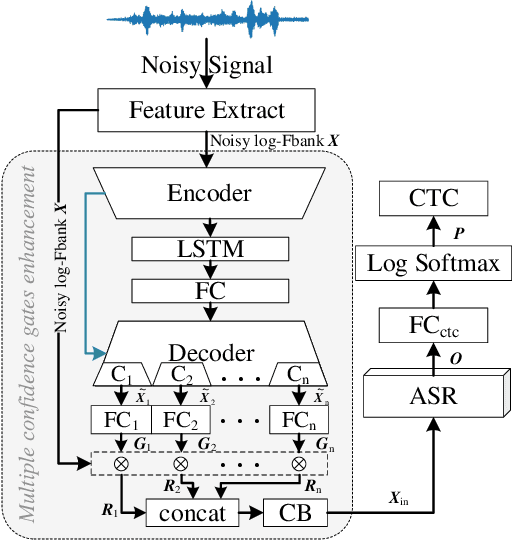
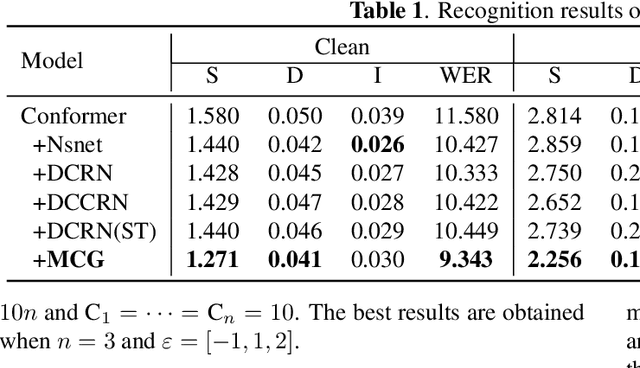
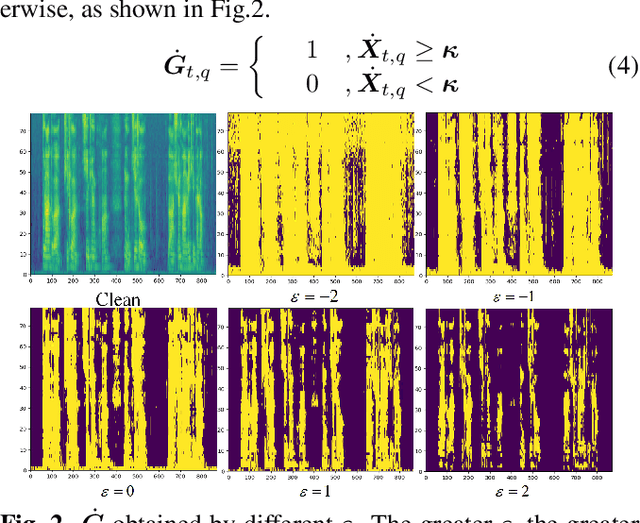
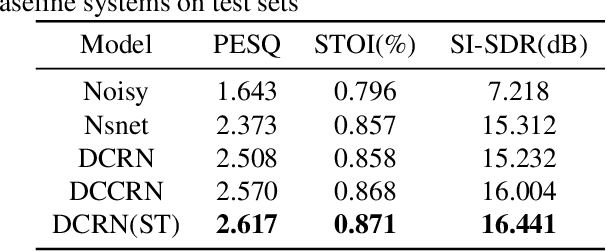
Joint training of speech enhancement model (SE) and speech recognition model (ASR) is a common solution for robust ASR in noisy environments. SE focuses on improving the auditory quality of speech, but the enhanced feature distribution is changed, which is uncertain and detrimental to the ASR. To tackle this challenge, an approach with multiple confidence gates for jointly training of SE and ASR is proposed. A speech confidence gates prediction module is designed to replace the former SE module in joint training. The noisy speech is filtered by gates to obtain features that are easier to be fitting by the ASR network. The experimental results show that the proposed method has better performance than the traditional robust speech recognition system on test sets of clean speech, synthesized noisy speech, and real noisy speech.