 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-VC: Zero-shot Streaming Voice Conversion in Codec Space
Apr 14, 2026Zero-shot voice conversion (VC) aims to convert a source utterance into the voice of an unseen target speaker while preserving its linguistic content. Although recent systems have improved conversion quality, building zero-shot VC systems for interactive scenarios remains challenging because high-fidelity speaker transfer and low-latency streaming inference are difficult to achieve simultaneously. In this work, we present X-VC, a zero-shot streaming VC system that performs one-step conversion in the latent space of a pretrained neural codec. X-VC uses a dual-conditioning acoustic converter that jointly models source codec latents and frame-level acoustic conditions derived from target reference speech, while injecting utterance-level target speaker information through adaptive normalization. To reduce the mismatch between training and inference, we train the model with generated paired data and a role-assignment strategy that combines standard, reconstruction, and reversed modes. For streaming inference, we further adopt a chunkwise inference scheme with overlap smoothing that is aligned with the segment-based training paradigm of the codec. Experiments on Seed-TTS-Eval show that X-VC achieves the best streaming WER in both English and Chinese, strong speaker similarity in same-language and cross-lingual settings, and substantially lower offline real-time factor than the compared baselines. These results suggest that codec-space one-step conversion is a practical approach for building high-quality low-latency zero-shot VC systems. Audio samples are available at https://x-vc.github.io. Our code and checkpoints will also be released.
MSR-HuBERT: Self-supervised Pre-training for Adaptation to Multiple Sampling Rates
Mar 24, 2026Self-supervised learning (SSL) has advanced speech processing. However, existing speech SSL methods typically assume a single sampling rate and struggle with mixed-rate data due to temporal resolution mismatch. To address this limitation, we propose MSRHuBERT, a multi-sampling-rate adaptive pre-training method. Building on HuBERT, we replace its single-rate downsampling CNN with a multi-sampling-rate adaptive downsampling CNN that maps raw waveforms from different sampling rates to a shared temporal resolution without resampling. This design enables unified mixed-rate pre-training and fine-tuning. In experiments spanning 16 to 48 kHz, MSRHuBERT outperforms HuBERT on speech recognition and full-band speech reconstruction, preserving high-frequency detail while modeling low-frequency semantic structure. Moreover, MSRHuBERT retains HuBERT's mask-prediction objective and Transformer encoder, so existing analyses and improvements that were developed for HuBERT can apply directly.
AudioRAG: A Challenging Benchmark for Audio Reasoning and Information Retrieval
Feb 11, 2026Due to recent advancements in Large Audio-Language Models (LALMs) that demonstrate remarkable performance across a range of sound-, speech- and music-related tasks, there is a growing interest in proposing benchmarks to assess these models. Existing benchmarks generally focus only on reasoning with internal knowledge, neglecting real-world scenarios that require external information grounding. To bridge this gap, we introduce AudioRAG, a novel benchmark designed to evaluate audio-based reasoning augmented by information retrieval in realistic web environments. This benchmark comprises both LLM-generated and manually curated question-answer pairs. Our evaluations reveal that even the state-of-the-art LALMs struggle to answer these questions. We therefore propose an agentic pipeline that integrates audio reasoning with retrieval-augmented generation, providing a stronger baseline for future research.
EmoShift: Lightweight Activation Steering for Enhanced Emotion-Aware Speech Synthesis
Jan 30, 2026Achieving precise and controllable emotional expression is crucial for producing natural and context-appropriate speech in text-to-speech (TTS) synthesis. However, many emotion-aware TTS systems, including large language model (LLM)-based designs, rely on scaling fixed emotion embeddings or external guidance, limiting their ability to model emotion-specific latent characteristics. To address this gap, we present EmoShift, a lightweight activation-steering framework incorporating a EmoSteer layer, which learns a steering vector for each target emotion in the output embedding space to capture its latent offset and maintain stable, appropriate expression across utterances and categories. With only 10M trainable parameters,less than 1/30 of full fine-tuning, EmoShift outperforms zero-shot and fully fine-tuned baselines in objective and subjective evaluations, enhancing emotional expressiveness while preserving naturalness and speaker similarity. Further analysis confirms the proposed EmoSteer layer's effectiveness and reveals its potential for controllable emotional intensity in speech synthesis.
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Jan 06, 2026Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
POTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
ASDA: Audio Spectrogram Differential Attention Mechanism for Self-Supervised Representation Learning
Jul 03, 2025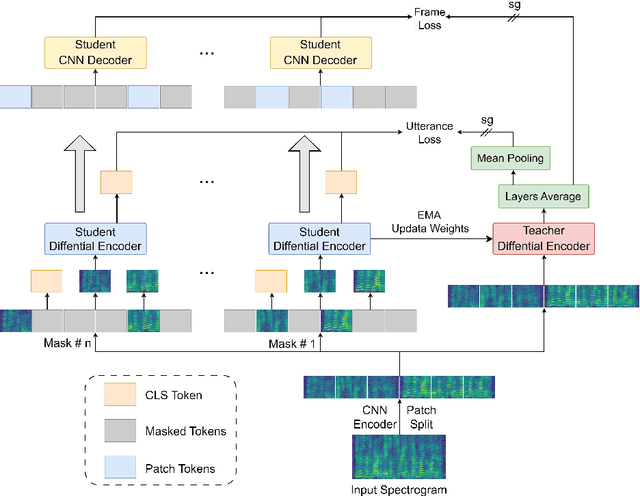



In recent advancements in audio self-supervised representation learning, the standard Transformer architecture has emerged as the predominant approach, yet its attention mechanism often allocates a portion of attention weights to irrelevant information, potentially impairing the model's discriminative ability. To address this, we introduce a differential attention mechanism, which effectively mitigates ineffective attention allocation through the integration of dual-softmax operations and appropriately tuned differential coefficients. Experimental results demonstrate that our ASDA model achieves state-of-the-art (SOTA) performance across multiple benchmarks, including audio classification (49.0% mAP on AS-2M, 41.5% mAP on AS20K), keyword spotting (98.3% accuracy on SPC-2), and environmental sound classification (96.1% accuracy on ESC-50). These results highlight ASDA's effectiveness in audio tasks, paving the way for broader applications.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025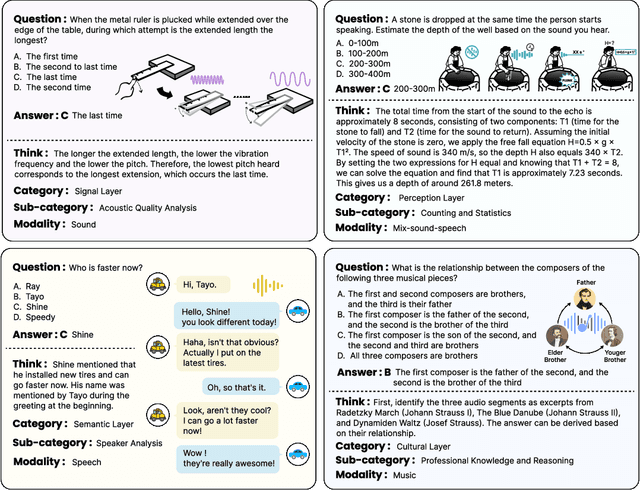

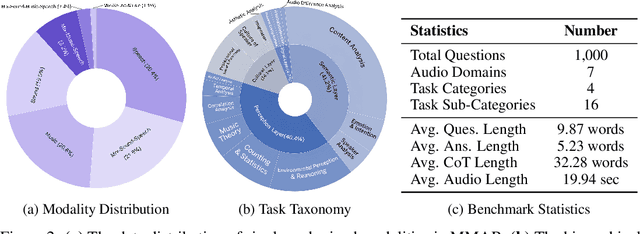
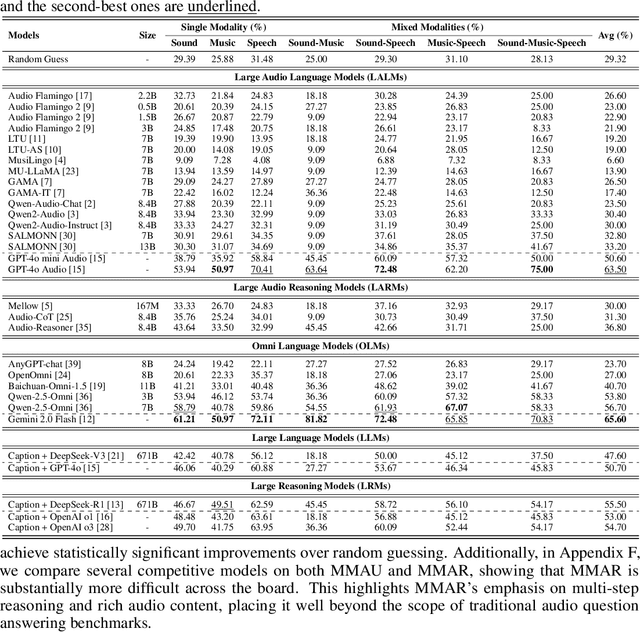
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Apr 22, 2025Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
Characteristic-Specific Partial Fine-Tuning for Efficient Emotion and Speaker Adaptation in Codec Language Text-to-Speech Models
Jan 24, 2025



Recently, emotional speech generation and speaker cloning have garnered significant interest in text-to-speech (TTS). With the open-sourcing of codec language TTS models trained on massive datasets with large-scale parameters, adapting these general pre-trained TTS models to generate speech with specific emotional expressions and target speaker characteristics has become a topic of great attention. Common approaches, such as full and adapter-based fine-tuning, often overlook the specific contributions of model parameters to emotion and speaker control. Treating all parameters uniformly during fine-tuning, especially when the target data has limited content diversity compared to the pre-training corpus, results in slow training speed and an increased risk of catastrophic forgetting. To address these challenges, we propose a characteristic-specific partial fine-tuning strategy, short as CSP-FT. First, we use a weighted-sum approach to analyze the contributions of different Transformer layers in a pre-trained codec language TTS model for emotion and speaker control in the generated speech. We then selectively fine-tune the layers with the highest and lowest characteristic-specific contributions to generate speech with target emotional expression and speaker identity. Experimental results demonstrate that our method achieves performance comparable to, or even surpassing, full fine-tuning in generating speech with specific emotional expressions and speaker identities. Additionally, CSP-FT delivers approximately 2x faster training speeds, fine-tunes only around 8% of parameters, and significantly reduces catastrophic forgetting. Furthermore, we show that codec language TTS models perform competitively with self-supervised models in speaker identification and emotion classification tasks, offering valuable insights for developing universal speech processing models.