 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCPAgentBench: A Real-world Task Benchmark for Evaluating LLM Agent MCP Tool Use
Dec 31, 2025Large Language Models (LLMs) are increasingly serving as autonomous agents, and their utilization of external tools via the Model Context Protocol (MCP) is considered a future trend. Current MCP evaluation sets suffer from issues such as reliance on external MCP services and a lack of difficulty awareness. To address these limitations, we propose MCPAgentBench, a benchmark based on real-world MCP definitions designed to evaluate the tool-use capabilities of agents. We construct a dataset containing authentic tasks and simulated MCP tools. The evaluation employs a dynamic sandbox environment that presents agents with candidate tool lists containing distractors, thereby testing their tool selection and discrimination abilities. Furthermore, we introduce comprehensive metrics to measure both task completion rates and execution efficiency. Experiments conducted on various latest mainstream Large Language Models reveal significant performance differences in handling complex, multi-step tool invocations. All code is open-source at Github.
JoDiffusion: Jointly Diffusing Image with Pixel-Level Annotations for Semantic Segmentation Promotion
Dec 15, 2025Given the inherently costly and time-intensive nature of pixel-level annotation, the generation of synthetic datasets comprising sufficiently diverse synthetic images paired with ground-truth pixel-level annotations has garnered increasing attention recently for training high-performance semantic segmentation models. However, existing methods necessitate to either predict pseudo annotations after image generation or generate images conditioned on manual annotation masks, which incurs image-annotation semantic inconsistency or scalability problem. To migrate both problems with one stone, we present a novel dataset generative diffusion framework for semantic segmentation, termed JoDiffusion. Firstly, given a standard latent diffusion model, JoDiffusion incorporates an independent annotation variational auto-encoder (VAE) network to map annotation masks into the latent space shared by images. Then, the diffusion model is tailored to capture the joint distribution of each image and its annotation mask conditioned on a text prompt. By doing these, JoDiffusion enables simultaneously generating paired images and semantically consistent annotation masks solely conditioned on text prompts, thereby demonstrating superior scalability. Additionally, a mask optimization strategy is developed to mitigate the annotation noise produced during generation. Experiments on Pascal VOC, COCO, and ADE20K datasets show that the annotated dataset generated by JoDiffusion yields substantial performance improvements in semantic segmentation compared to existing methods.
Say More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding
Sep 04, 2025Existing speech tokenizers typically assign a fixed number of tokens per second, regardless of the varying information density or temporal fluctuations in the speech signal. This uniform token allocation mismatches the intrinsic structure of speech, where information is distributed unevenly over time. To address this, we propose VARSTok, a VAriable-frame-Rate Speech Tokenizer that adapts token allocation based on local feature similarity. VARSTok introduces two key innovations: (1) a temporal-aware density peak clustering algorithm that adaptively segments speech into variable-length units, and (2) a novel implicit duration coding scheme that embeds both content and temporal span into a single token index, eliminating the need for auxiliary duration predictors. Extensive experiments show that VARSTok significantly outperforms strong fixed-rate baselines. Notably, it achieves superior reconstruction naturalness while using up to 23% fewer tokens than a 40 Hz fixed-frame-rate baseline. VARSTok further yields lower word error rates and improved naturalness in zero-shot text-to-speech synthesis. To the best of our knowledge, this is the first work to demonstrate that a fully dynamic, variable-frame-rate acoustic speech tokenizer can be seamlessly integrated into downstream speech language models. Speech samples are available at https://zhengrachel.github.io/VARSTok.
Speech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Apr 22, 2025Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
TinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation
Mar 06, 2025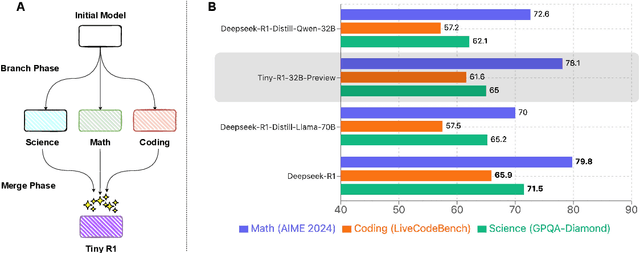
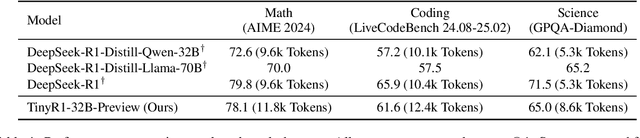
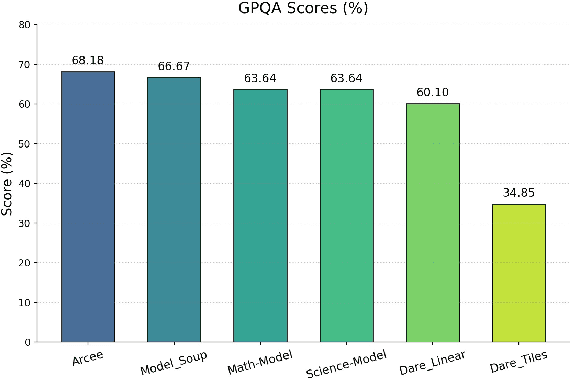
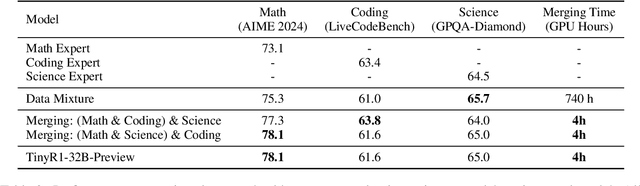
The challenge of reducing the size of Large Language Models (LLMs) while maintaining their performance has gained significant attention. However, existing methods, such as model distillation and transfer learning, often fail to achieve high accuracy. To address this limitation, we introduce the Branch-Merge distillation approach, which enhances model compression through two phases: (1) the Branch Phase, where knowledge from a large teacher model is \textit{selectively distilled} into specialized student models via domain-specific supervised fine-tuning (SFT); And (2) the Merge Phase, where these student models are merged to enable cross-domain knowledge transfer and improve generalization. We validate our distillation approach using DeepSeek-R1 as the teacher and DeepSeek-R1-Distill-Qwen-32B as the student. The resulting merged model, TinyR1-32B-Preview, outperforms its counterpart DeepSeek-R1-Distill-Qwen-32B across multiple benchmarks, including Mathematics (+5.5 points), Coding (+4.4 points) and Science (+2.9 points), while achieving near-equal performance to DeepSeek-R1 on AIME 2024. The Branch-Merge distillation approach provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and time.
Enhancing Expressive Voice Conversion with Discrete Pitch-Conditioned Flow Matching Model
Feb 08, 2025



This paper introduces PFlow-VC, a conditional flow matching voice conversion model that leverages fine-grained discrete pitch tokens and target speaker prompt information for expressive voice conversion (VC). Previous VC works primarily focus on speaker conversion, with further exploration needed in enhancing expressiveness (such as prosody and emotion) for timbre conversion. Unlike previous methods, we adopt a simple and efficient approach to enhance the style expressiveness of voice conversion models. Specifically, we pretrain a self-supervised pitch VQVAE model to discretize speaker-irrelevant pitch information and leverage a masked pitch-conditioned flow matching model for Mel-spectrogram synthesis, which provides in-context pitch modeling capabilities for the speaker conversion model, effectively improving the voice style transfer capacity. Additionally, we improve timbre similarity by combining global timbre embeddings with time-varying timbre tokens. Experiments on unseen LibriTTS test-clean and emotional speech dataset ESD show the superiority of the PFlow-VC model in both timbre conversion and style transfer. Audio samples are available on the demo page https://speechai-demo.github.io/PFlow-VC/.
Analyzing and Mitigating Inconsistency in Discrete Audio Tokens for Neural Codec Language Models
Sep 28, 2024



Building upon advancements in Large Language Models (LLMs), the field of audio processing has seen increased interest in training audio generation tasks with discrete audio token sequences. However, directly discretizing audio by neural audio codecs often results in sequences that fundamentally differ from text sequences. Unlike text, where text token sequences are deterministic, discrete audio tokens can exhibit significant variability based on contextual factors, while still producing perceptually identical audio segments. We refer to this phenomenon as \textbf{Discrete Representation Inconsistency (DRI)}. This inconsistency can lead to a single audio segment being represented by multiple divergent sequences, which creates confusion in neural codec language models and results in omissions and repetitions during speech generation. In this paper, we quantitatively analyze the DRI phenomenon within popular audio tokenizers such as EnCodec. Our approach effectively mitigates the DRI phenomenon of the neural audio codec. Furthermore, extensive experiments on the neural codec language model over LibriTTS and large-scale MLS datases (44,000 hours) demonstrate the effectiveness and generality of our method. The demo of audio samples is available online~\footnote{\url{https://consistencyinneuralcodec.github.io}}.
LatentArtiFusion: An Effective and Efficient Histological Artifacts Restoration Framework
Jul 29, 2024



Histological artifacts pose challenges for both pathologists and Computer-Aided Diagnosis (CAD) systems, leading to errors in analysis. Current approaches for histological artifact restoration, based on Generative Adversarial Networks (GANs) and pixel-level Diffusion Models, suffer from performance limitations and computational inefficiencies. In this paper, we propose a novel framework, LatentArtiFusion, which leverages the latent diffusion model (LDM) to reconstruct histological artifacts with high performance and computational efficiency. Unlike traditional pixel-level diffusion frameworks, LatentArtiFusion executes the restoration process in a lower-dimensional latent space, significantly improving computational efficiency. Moreover, we introduce a novel regional artifact reconstruction algorithm in latent space to prevent mistransfer in non-artifact regions, distinguishing our approach from GAN-based methods. Through extensive experiments on real-world histology datasets, LatentArtiFusion demonstrates remarkable speed, outperforming state-of-the-art pixel-level diffusion frameworks by more than 30X. It also consistently surpasses GAN-based methods by at least 5% across multiple evaluation metrics. Furthermore, we evaluate the effectiveness of our proposed framework in downstream tissue classification tasks, showcasing its practical utility. Code is available at https://github.com/bugs-creator/LatentArtiFusion.
ACE: A Generative Cross-Modal Retrieval Framework with Coarse-To-Fine Semantic Modeling
Jun 25, 2024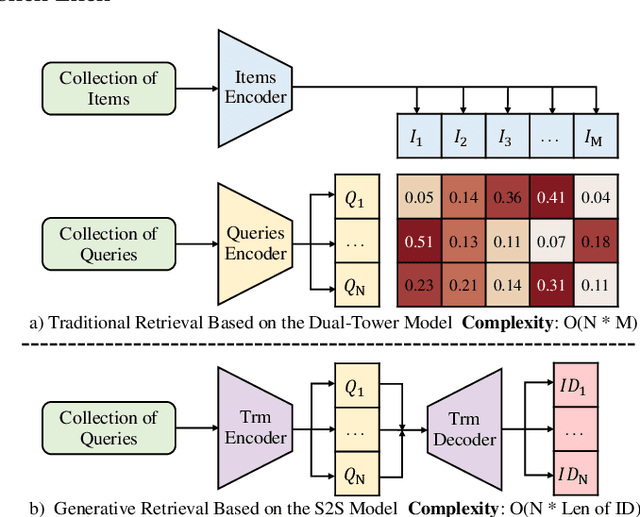



Generative retrieval, which has demonstrated effectiveness in text-to-text retrieval, utilizes a sequence-to-sequence model to directly generate candidate identifiers based on natural language queries. Without explicitly computing the similarity between queries and candidates, generative retrieval surpasses dual-tower models in both speed and accuracy on large-scale corpora, providing new insights for cross-modal retrieval. However, constructing identifiers for multimodal data remains an untapped problem, and the modality gap between natural language queries and multimodal candidates hinders retrieval performance due to the absence of additional encoders. To this end, we propose a pioneering generAtive Cross-modal rEtrieval framework (ACE), which is a comprehensive framework for end-to-end cross-modal retrieval based on coarse-to-fine semantic modeling. We propose combining K-Means and RQ-VAE to construct coarse and fine tokens, serving as identifiers for multimodal data. Correspondingly, we design the coarse-to-fine feature fusion strategy to efficiently align natural language queries and candidate identifiers. ACE is the first work to comprehensively demonstrate the feasibility of generative approach on text-to-image/audio/video retrieval, challenging the dominance of the embedding-based dual-tower architecture. Extensive experiments show that ACE achieves state-of-the-art performance in cross-modal retrieval and outperforms the strong baselines on Recall@1 by 15.27% on average.