 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Expressive Voice Conversion with Discrete Pitch-Conditioned Flow Matching Model
Feb 08, 2025



This paper introduces PFlow-VC, a conditional flow matching voice conversion model that leverages fine-grained discrete pitch tokens and target speaker prompt information for expressive voice conversion (VC). Previous VC works primarily focus on speaker conversion, with further exploration needed in enhancing expressiveness (such as prosody and emotion) for timbre conversion. Unlike previous methods, we adopt a simple and efficient approach to enhance the style expressiveness of voice conversion models. Specifically, we pretrain a self-supervised pitch VQVAE model to discretize speaker-irrelevant pitch information and leverage a masked pitch-conditioned flow matching model for Mel-spectrogram synthesis, which provides in-context pitch modeling capabilities for the speaker conversion model, effectively improving the voice style transfer capacity. Additionally, we improve timbre similarity by combining global timbre embeddings with time-varying timbre tokens. Experiments on unseen LibriTTS test-clean and emotional speech dataset ESD show the superiority of the PFlow-VC model in both timbre conversion and style transfer. Audio samples are available on the demo page https://speechai-demo.github.io/PFlow-VC/.
CueTip: An Interactive and Explainable Physics-aware Pool Assistant
Jan 30, 2025We present an interactive and explainable automated coaching assistant called CueTip for a variant of pool/billiards. CueTip's novelty lies in its combination of three features: a natural-language interface, an ability to perform contextual, physics-aware reasoning, and that its explanations are rooted in a set of predetermined guidelines developed by domain experts. We instrument a physics simulator so that it generates event traces in natural language alongside traditional state traces. Event traces lend themselves to interpretation by language models, which serve as the interface to our assistant. We design and train a neural adaptor that decouples tactical choices made by CueTip from its interactivity and explainability allowing it to be reconfigured to mimic any pool playing agent. Our experiments show that CueTip enables contextual query-based assistance and explanations while maintaining the strength of the agent in terms of win rate (improving it in some situations). The explanations generated by CueTip are physically-aware and grounded in the expert rules and are therefore more reliable.
Enabling Beam Search for Language Model-Based Text-to-Speech Synthesis
Aug 29, 2024



Tokenising continuous speech into sequences of discrete tokens and modelling them with language models (LMs) has led to significant success in text-to-speech (TTS) synthesis. Although these models can generate speech with high quality and naturalness, their synthesised samples can still suffer from artefacts, mispronunciation, word repeating, etc. In this paper, we argue these undesirable properties could partly be caused by the randomness of sampling-based strategies during the autoregressive decoding of LMs. Therefore, we look at maximisation-based decoding approaches and propose Temporal Repetition Aware Diverse Beam Search (TRAD-BS) to find the most probable sequences of the generated speech tokens. Experiments with two state-of-the-art LM-based TTS models demonstrate that our proposed maximisation-based decoding strategy generates speech with fewer mispronunciations and improved speaker consistency.
Intelligibility prediction with a pretrained noise-robust automatic speech recognition model
Oct 20, 2023This paper describes two intelligibility prediction systems derived from a pretrained noise-robust automatic speech recognition (ASR) model for the second Clarity Prediction Challenge (CPC2). One system is intrusive and leverages the hidden representations of the ASR model. The other system is non-intrusive and makes predictions with derived ASR uncertainty. The ASR model is only pretrained with a simulated noisy speech corpus and does not take advantage of the CPC2 data. For that reason, the intelligibility prediction systems are robust to unseen scenarios given the accurate prediction performance on the CPC2 evaluation.
Energy-Based Models For Speech Synthesis
Oct 19, 2023



Recently there has been a lot of interest in non-autoregressive (non-AR) models for speech synthesis, such as FastSpeech 2 and diffusion models. Unlike AR models, these models do not have autoregressive dependencies among outputs which makes inference efficient. This paper expands the range of available non-AR models with another member called energy-based models (EBMs). The paper describes how noise contrastive estimation, which relies on the comparison between positive and negative samples, can be used to train EBMs. It proposes a number of strategies for generating effective negative samples, including using high-performing AR models. It also describes how sampling from EBMs can be performed using Langevin Markov Chain Monte-Carlo (MCMC). The use of Langevin MCMC enables to draw connections between EBMs and currently popular diffusion models. Experiments on LJSpeech dataset show that the proposed approach offers improvements over Tacotron 2.
Unsupervised Uncertainty Measures of Automatic Speech Recognition for Non-intrusive Speech Intelligibility Prediction
Apr 08, 2022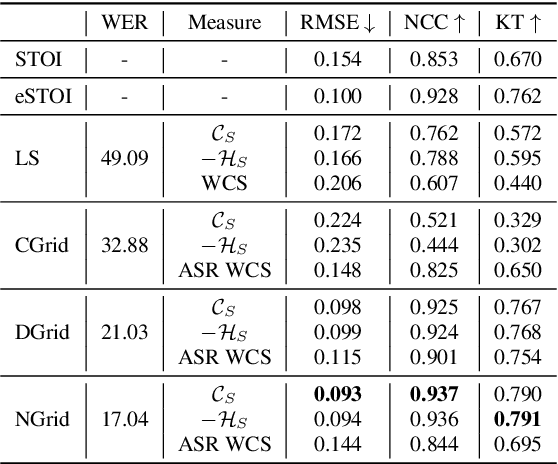
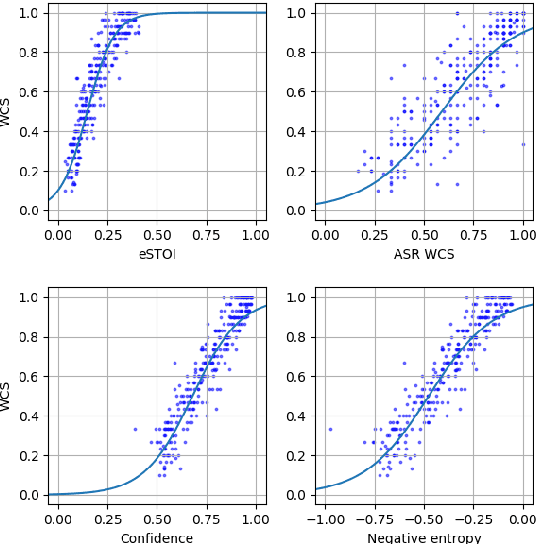
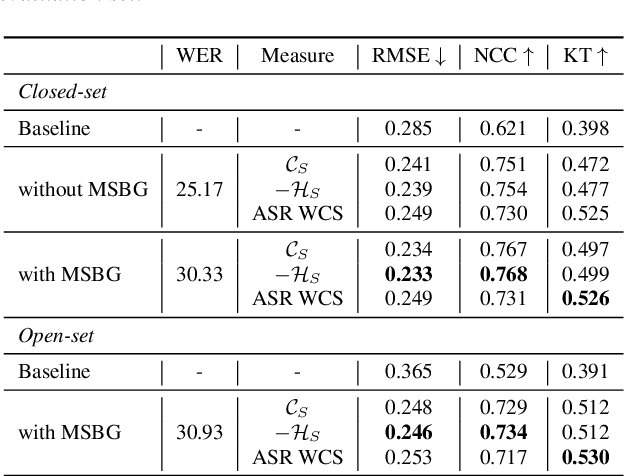
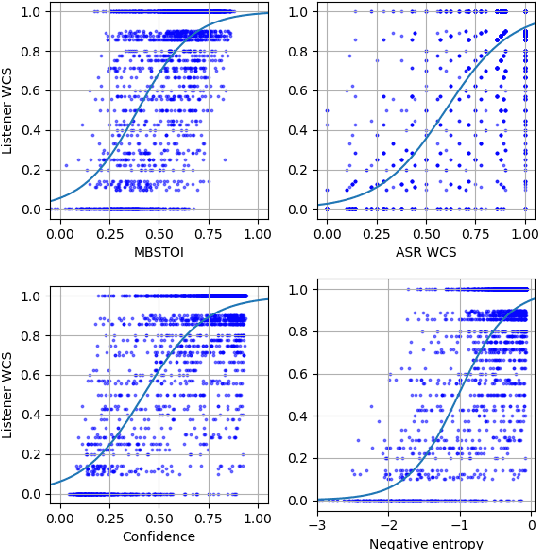
Non-intrusive intelligibility prediction is important for its application in realistic scenarios, where a clean reference signal is difficult to access. The construction of many non-intrusive predictors require either ground truth intelligibility labels or clean reference signals for supervised learning. In this work, we leverage an unsupervised uncertainty estimation method for predicting speech intelligibility, which does not require intelligibility labels or reference signals to train the predictor. Our experiments demonstrate that the uncertainty from state-of-the-art end-to-end automatic speech recognition (ASR) models is highly correlated with speech intelligibility. The proposed method is evaluated on two databases and the results show that the unsupervised uncertainty measures of ASR models are more correlated with speech intelligibility from listening results than the predictions made by widely used intrusive methods.
Exploiting Hidden Representations from a DNN-based Speech Recogniser for Speech Intelligibility Prediction in Hearing-impaired Listeners
Apr 08, 2022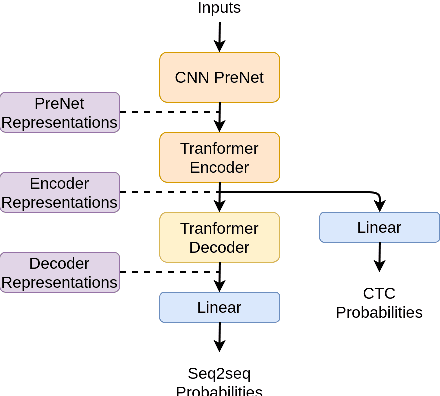
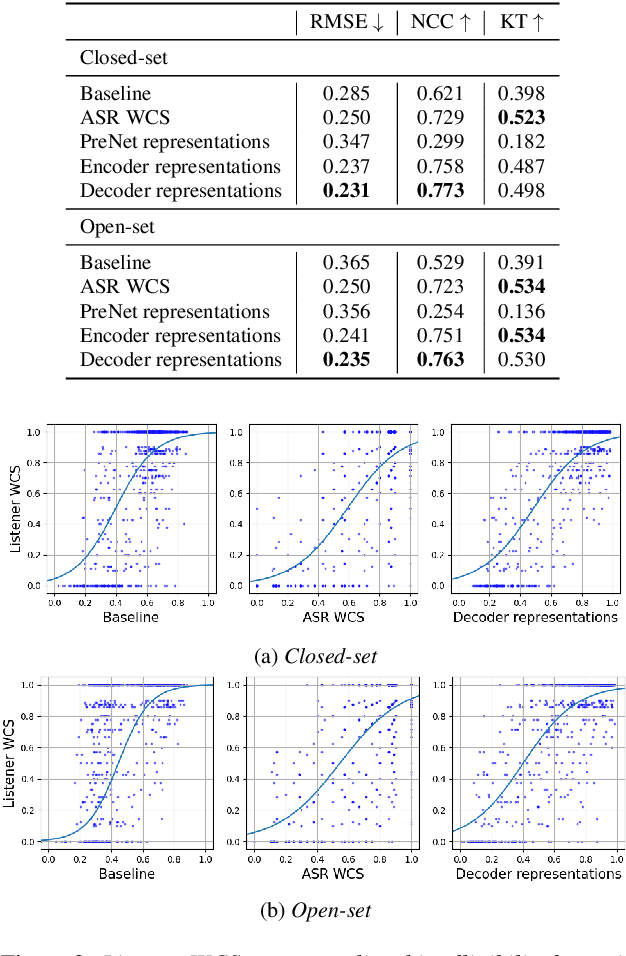
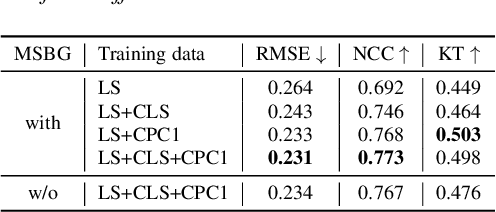
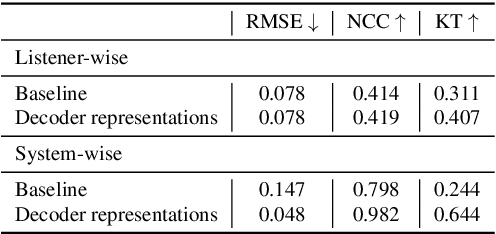
An accurate objective speech intelligibility prediction algorithms is of great interest for many applications such as speech enhancement for hearing aids. Most algorithms measures the signal-to-noise ratios or correlations between the acoustic features of clean reference signals and degraded signals. However, these hand-picked acoustic features are usually not explicitly correlated with recognition. Meanwhile, deep neural network (DNN) based automatic speech recogniser (ASR) is approaching human performance in some speech recognition tasks. This work leverages the hidden representations from DNN-based ASR as features for speech intelligibility prediction in hearing-impaired listeners. The experiments based on a hearing aid intelligibility database show that the proposed method could make better prediction than a widely used short-time objective intelligibility (STOI) based binaural measure.
Auditory-Based Data Augmentation for End-to-End Automatic Speech Recognition
Apr 08, 2022

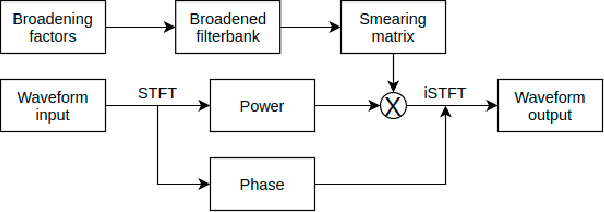
End-to-end models have achieved significant improvement on automatic speech recognition. One common method to improve performance of these models is expanding the data-space through data augmentation. Meanwhile, human auditory inspired front-ends have also demonstrated improvement for automatic speech recognisers. In this work, a well-verified auditory-based model, which can simulate various hearing abilities, is investigated for the purpose of data augmentation for end-to-end speech recognition. By introducing the auditory model into the data augmentation process, end-to-end systems are encouraged to ignore variation from the signal that cannot be heard and thereby focus on robust features for speech recognition. Two mechanisms in the auditory model, spectral smearing and loudness recruitment, are studied on the LibriSpeech dataset with a transformer-based end-to-end model. The results show that the proposed augmentation methods can bring statistically significant improvement on the performance of the state-of-the-art SpecAugment.
Optimising Hearing Aid Fittings for Speech in Noise with a Differentiable Hearing Loss Model
Jun 08, 2021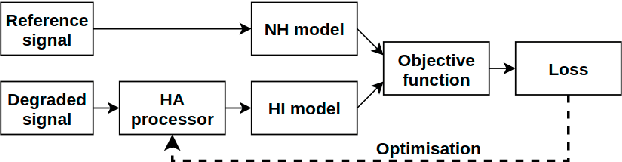
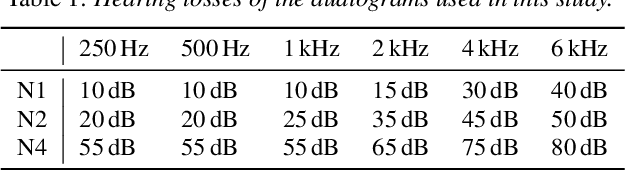
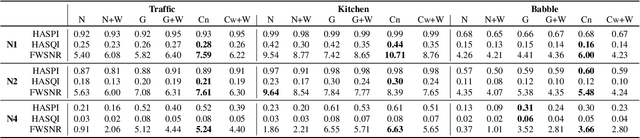
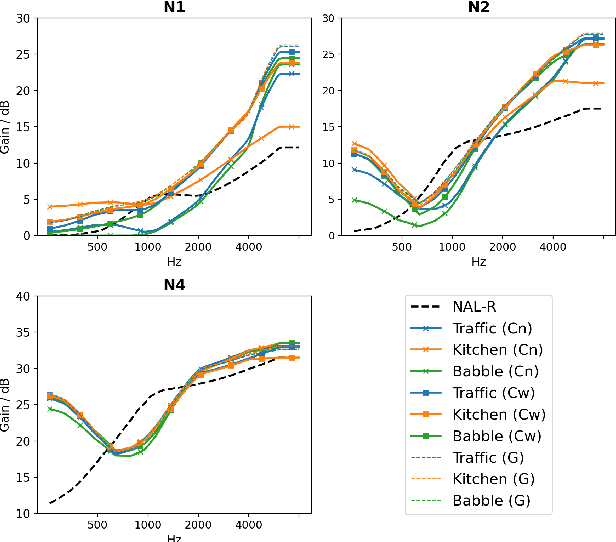
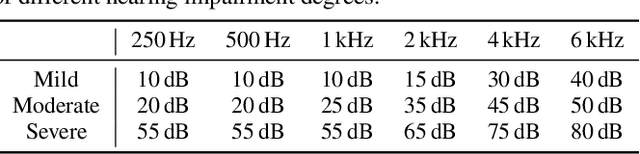
Current hearing aids normally provide amplification based on a general prescriptive fitting, and the benefits provided by the hearing aids vary among different listening environments despite the inclusion of noise suppression feature. Motivated by this fact, this paper proposes a data-driven machine learning technique to develop hearing aid fittings that are customised to speech in different noisy environments. A differentiable hearing loss model is proposed and used to optimise fittings with back-propagation. The customisation is reflected on the data of speech in different noise with also the consideration of noise suppression. The objective evaluation shows the advantages of optimised custom fittings over general prescriptive fittings.
DHASP: Differentiable Hearing Aid Speech Processing
Mar 15, 2021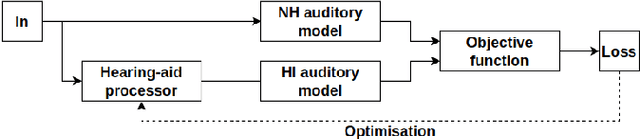

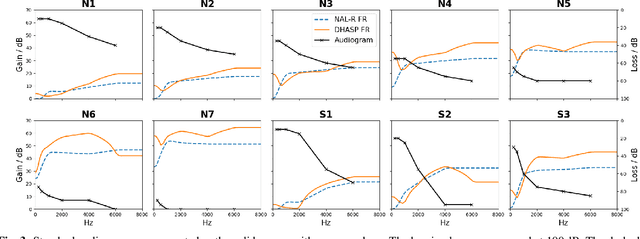
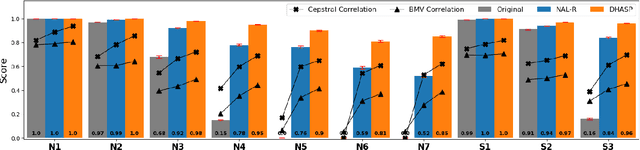
Hearing aids are expected to improve speech intelligibility for listeners with hearing impairment. An appropriate amplification fitting tuned for the listener's hearing disability is critical for good performance. The developments of most prescriptive fittings are based on data collected in subjective listening experiments, which are usually expensive and time-consuming. In this paper, we explore an alternative approach to finding the optimal fitting by introducing a hearing aid speech processing framework, in which the fitting is optimised in an automated way using an intelligibility objective function based on the HASPI physiological auditory model. The framework is fully differentiable, thus can employ the back-propagation algorithm for efficient, data-driven optimisation. Our initial objective experiments show promising results for noise-free speech amplification, where the automatically optimised processors outperform one of the well recognised hearing aid prescriptions.