 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCueTip: An Interactive and Explainable Physics-aware Pool Assistant
Jan 30, 2025We present an interactive and explainable automated coaching assistant called CueTip for a variant of pool/billiards. CueTip's novelty lies in its combination of three features: a natural-language interface, an ability to perform contextual, physics-aware reasoning, and that its explanations are rooted in a set of predetermined guidelines developed by domain experts. We instrument a physics simulator so that it generates event traces in natural language alongside traditional state traces. Event traces lend themselves to interpretation by language models, which serve as the interface to our assistant. We design and train a neural adaptor that decouples tactical choices made by CueTip from its interactivity and explainability allowing it to be reconfigured to mimic any pool playing agent. Our experiments show that CueTip enables contextual query-based assistance and explanations while maintaining the strength of the agent in terms of win rate (improving it in some situations). The explanations generated by CueTip are physically-aware and grounded in the expert rules and are therefore more reliable.
A Comparison of Self-Play Algorithms Under a Generalized Framework
Jun 08, 2020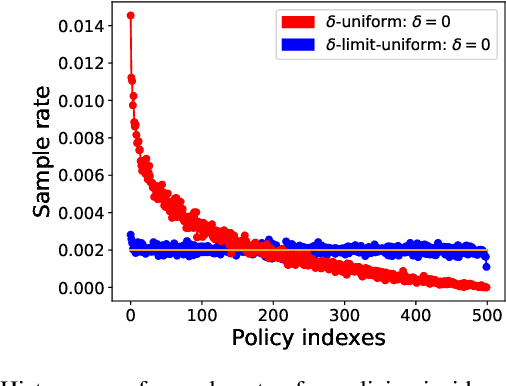
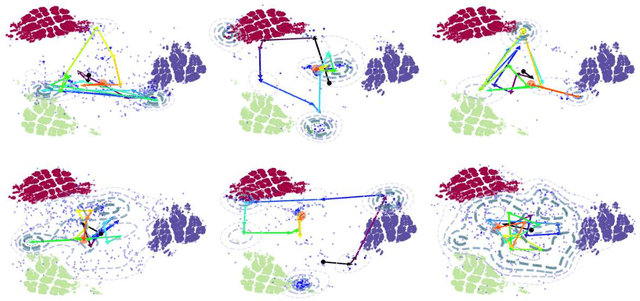
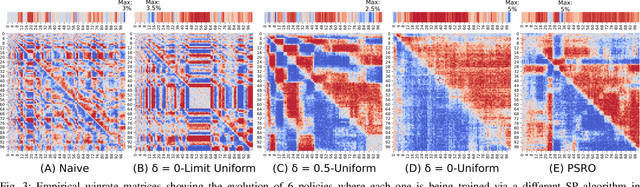
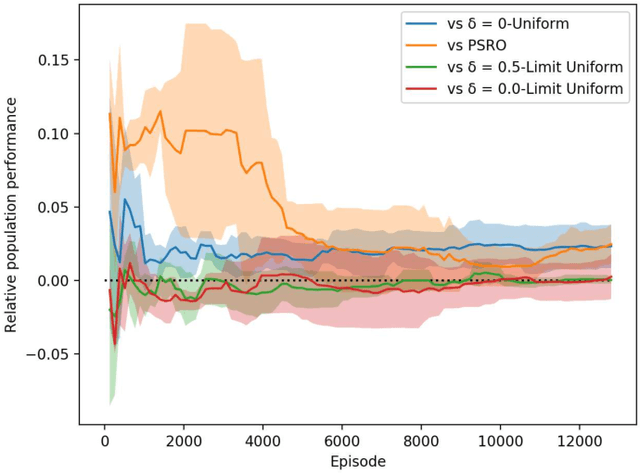
Throughout scientific history, overarching theoretical frameworks have allowed researchers to grow beyond personal intuitions and culturally biased theories. They allow to verify and replicate existing findings, and to link is connected results. The notion of self-play, albeit often cited in multiagent Reinforcement Learning, has never been grounded in a formal model. We present a formalized framework, with clearly defined assumptions, which encapsulates the meaning of self-play as abstracted from various existing self-play algorithms. This framework is framed as an approximation to a theoretical solution concept for multiagent training. On a simple environment, we qualitatively measure how well a subset of the captured self-play methods approximate this solution when paired with the famous PPO algorithm. We also provide insights on interpreting quantitative metrics of performance for self-play training. Our results indicate that, throughout training, various self-play definitions exhibit cyclic policy evolutions.