 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
MultiTaskDeltaNet: Change Detection-based Image Segmentation for Operando ETEM with Application to Carbon Gasification Kinetics
Jul 22, 2025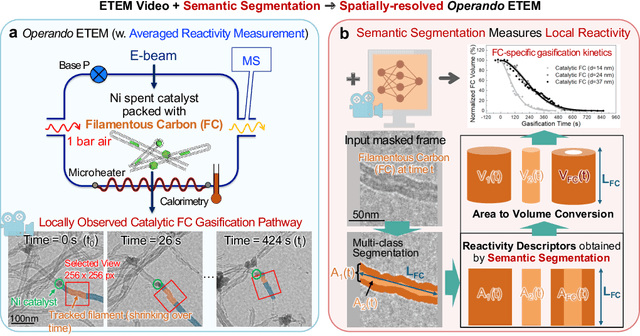
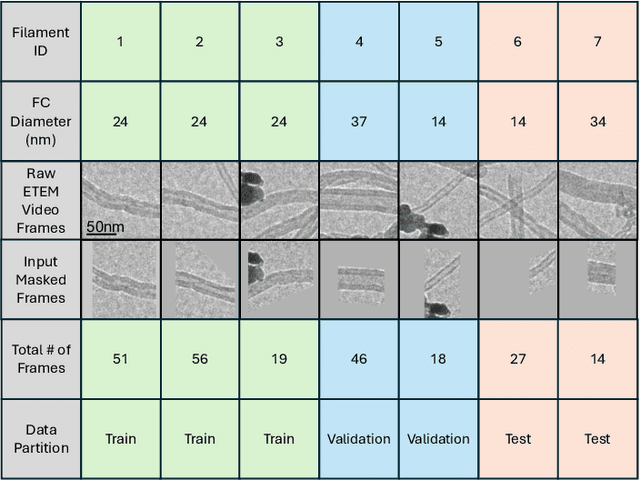

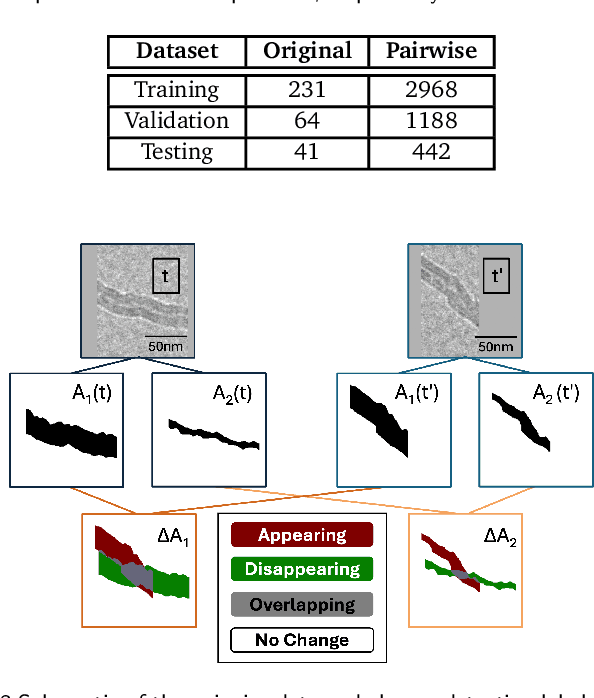
Transforming in-situ transmission electron microscopy (TEM) imaging into a tool for spatially-resolved operando characterization of solid-state reactions requires automated, high-precision semantic segmentation of dynamically evolving features. However, traditional deep learning methods for semantic segmentation often encounter limitations due to the scarcity of labeled data, visually ambiguous features of interest, and small-object scenarios. To tackle these challenges, we introduce MultiTaskDeltaNet (MTDN), a novel deep learning architecture that creatively reconceptualizes the segmentation task as a change detection problem. By implementing a unique Siamese network with a U-Net backbone and using paired images to capture feature changes, MTDN effectively utilizes minimal data to produce high-quality segmentations. Furthermore, MTDN utilizes a multi-task learning strategy to leverage correlations between physical features of interest. In an evaluation using data from in-situ environmental TEM (ETEM) videos of filamentous carbon gasification, MTDN demonstrated a significant advantage over conventional segmentation models, particularly in accurately delineating fine structural features. Notably, MTDN achieved a 10.22% performance improvement over conventional segmentation models in predicting small and visually ambiguous physical features. This work bridges several key gaps between deep learning and practical TEM image analysis, advancing automated characterization of nanomaterials in complex experimental settings.
Multimodal RAG-driven Anomaly Detection and Classification in Laser Powder Bed Fusion using Large Language Models
May 20, 2025Additive manufacturing enables the fabrication of complex designs while minimizing waste, but faces challenges related to defects and process anomalies. This study presents a novel multimodal Retrieval-Augmented Generation-based framework that automates anomaly detection across various Additive Manufacturing processes leveraging retrieved information from literature, including images and descriptive text, rather than training datasets. This framework integrates text and image retrieval from scientific literature and multimodal generation models to perform zero-shot anomaly identification, classification, and explanation generation in a Laser Powder Bed Fusion setting. The proposed framework is evaluated on four L-PBF manufacturing datasets from Oak Ridge National Laboratory, featuring various printer makes, models, and materials. This evaluation demonstrates the framework's adaptability and generalizability across diverse images without requiring additional training. Comparative analysis using Qwen2-VL-2B and GPT-4o-mini as MLLM within the proposed framework highlights that GPT-4o-mini outperforms Qwen2-VL-2B and proportional random baseline in manufacturing anomalies classification. Additionally, the evaluation of the RAG system confirms that incorporating retrieval mechanisms improves average accuracy by 12% by reducing the risk of hallucination and providing additional information. The proposed framework can be continuously updated by integrating emerging research, allowing seamless adaptation to the evolving landscape of AM technologies. This scalable, automated, and zero-shot-capable framework streamlines AM anomaly analysis, enhancing efficiency and accuracy.
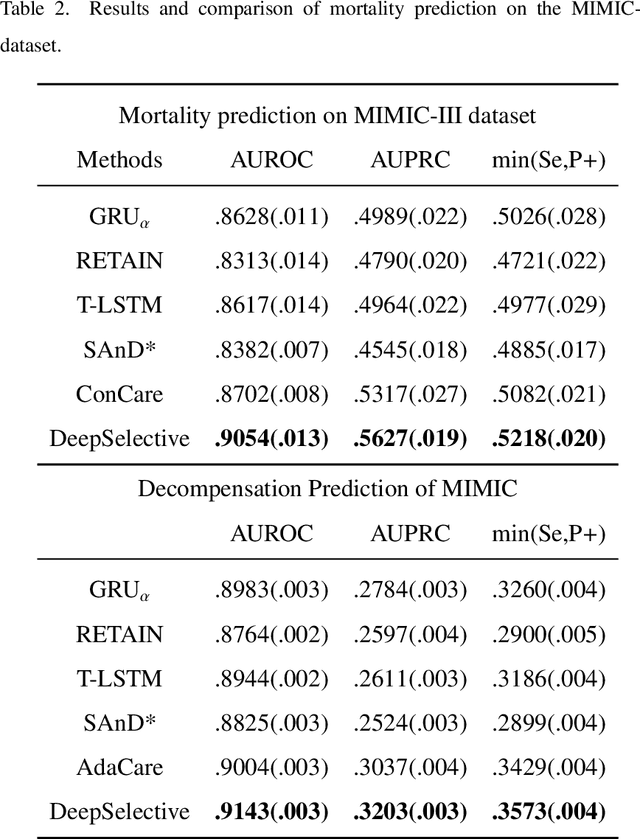
DeepSelective: Feature Gating and Representation Matching for Interpretable Clinical Prediction
Apr 15, 2025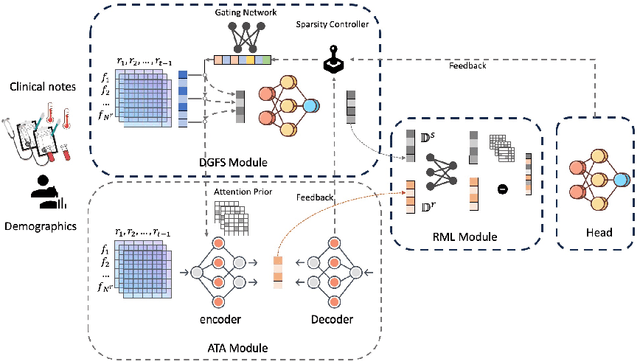

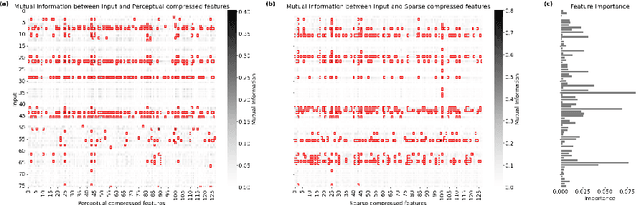
The rapid accumulation of Electronic Health Records (EHRs) has transformed healthcare by providing valuable data that enhance clinical predictions and diagnoses. While conventional machine learning models have proven effective, they often lack robust representation learning and depend heavily on expert-crafted features. Although deep learning offers powerful solutions, it is often criticized for its lack of interpretability. To address these challenges, we propose DeepSelective, a novel end to end deep learning framework for predicting patient prognosis using EHR data, with a strong emphasis on enhancing model interpretability. DeepSelective combines data compression techniques with an innovative feature selection approach, integrating custom-designed modules that work together to improve both accuracy and interpretability. Our experiments demonstrate that DeepSelective not only enhances predictive accuracy but also significantly improves interpretability, making it a valuable tool for clinical decision-making. The source code is freely available at http://www.healthinformaticslab.org/supp/resources.php .
How Problematic Writer-AI Interactions (Rather than Problematic AI) Hinder Writers' Idea Generation
Mar 14, 2025



Writing about a subject enriches writers' understanding of that subject. This cognitive benefit of writing -- known as constructive learning -- is essential to how students learn in various disciplines. However, does this benefit persist when students write with generative AI writing assistants? Prior research suggests the answer varies based on the type of AI, e.g., auto-complete systems tend to hinder ideation, while assistants that pose Socratic questions facilitate it. This paper adds an additional perspective. Through a case study, we demonstrate that the impact of genAI on students' idea development depends not only on the AI but also on the students and, crucially, their interactions in between. Students who proactively explored ideas gained new ideas from writing, regardless of whether they used auto-complete or Socratic AI assistants. Those who engaged in prolonged, mindless copyediting developed few ideas even with a Socratic AI. These findings suggest opportunities in designing AI writing assistants, not merely by creating more thought-provoking AI, but also by fostering more thought-provoking writer-AI interactions.
Cross-platform Prediction of Depression Treatment Outcome Using Location Sensory Data on Smartphones
Mar 10, 2025Currently, depression treatment relies on closely monitoring patients response to treatment and adjusting the treatment as needed. Using self-reported or physician-administrated questionnaires to monitor treatment response is, however, burdensome, costly and suffers from recall bias. In this paper, we explore using location sensory data collected passively on smartphones to predict treatment outcome. To address heterogeneous data collection on Android and iOS phones, the two predominant smartphone platforms, we explore using domain adaptation techniques to map their data to a common feature space, and then use the data jointly to train machine learning models. Our results show that this domain adaptation approach can lead to significantly better prediction than that with no domain adaptation. In addition, our results show that using location features and baseline self-reported questionnaire score can lead to F1 score up to 0.67, comparable to that obtained using periodic self-reported questionnaires, indicating that using location data is a promising direction for predicting depression treatment outcome.
Enhancing Expressive Voice Conversion with Discrete Pitch-Conditioned Flow Matching Model
Feb 08, 2025



This paper introduces PFlow-VC, a conditional flow matching voice conversion model that leverages fine-grained discrete pitch tokens and target speaker prompt information for expressive voice conversion (VC). Previous VC works primarily focus on speaker conversion, with further exploration needed in enhancing expressiveness (such as prosody and emotion) for timbre conversion. Unlike previous methods, we adopt a simple and efficient approach to enhance the style expressiveness of voice conversion models. Specifically, we pretrain a self-supervised pitch VQVAE model to discretize speaker-irrelevant pitch information and leverage a masked pitch-conditioned flow matching model for Mel-spectrogram synthesis, which provides in-context pitch modeling capabilities for the speaker conversion model, effectively improving the voice style transfer capacity. Additionally, we improve timbre similarity by combining global timbre embeddings with time-varying timbre tokens. Experiments on unseen LibriTTS test-clean and emotional speech dataset ESD show the superiority of the PFlow-VC model in both timbre conversion and style transfer. Audio samples are available on the demo page https://speechai-demo.github.io/PFlow-VC/.
Stepback: Enhanced Disentanglement for Voice Conversion via Multi-Task Learning
Jan 26, 2025Voice conversion (VC) modifies voice characteristics while preserving linguistic content. This paper presents the Stepback network, a novel model for converting speaker identity using non-parallel data. Unlike traditional VC methods that rely on parallel data, our approach leverages deep learning techniques to enhance disentanglement completion and linguistic content preservation. The Stepback network incorporates a dual flow of different domain data inputs and uses constraints with self-destructive amendments to optimize the content encoder. Extensive experiments show that our model significantly improves VC performance, reducing training costs while achieving high-quality voice conversion. The Stepback network's design offers a promising solution for advanced voice conversion tasks.
Assessing and Learning Alignment of Unimodal Vision and Language Models
Dec 05, 2024



How well are unimodal vision and language models aligned? Although prior work have approached answering this question, their assessment methods do not directly translate to how these models are used in practical vision-language tasks. In this paper, we propose a direct assessment method, inspired by linear probing, to assess vision-language alignment. We identify that the degree of alignment of the SSL vision models depends on their SSL training objective, and we find that the clustering quality of SSL representations has a stronger impact on alignment performance than their linear separability. Next, we introduce Swift Alignment of Image and Language (SAIL), a efficient transfer learning framework that aligns pretrained unimodal vision and language models for downstream vision-language tasks. Since SAIL leverages the strengths of pretrained unimodal models, it requires significantly fewer (6%) paired image-text data for the multimodal alignment compared to models like CLIP which are trained from scratch. SAIL training only requires a single A100 GPU, 5 hours of training and can accommodate a batch size up to 32,768. SAIL achieves 73.4% zero-shot accuracy on ImageNet (vs. CLIP's 72.7%) and excels in zero-shot retrieval, complex reasoning, and semantic segmentation. Additionally, SAIL improves the language-compatibility of vision encoders that in turn enhance the performance of multimodal large language models. The entire codebase and model weights are open-source: https://lezhang7.github.io/sail.github.io/
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024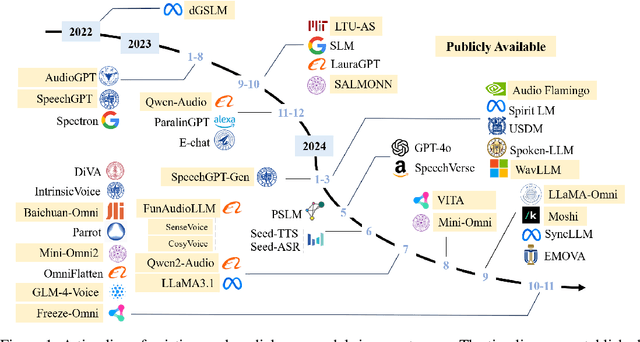

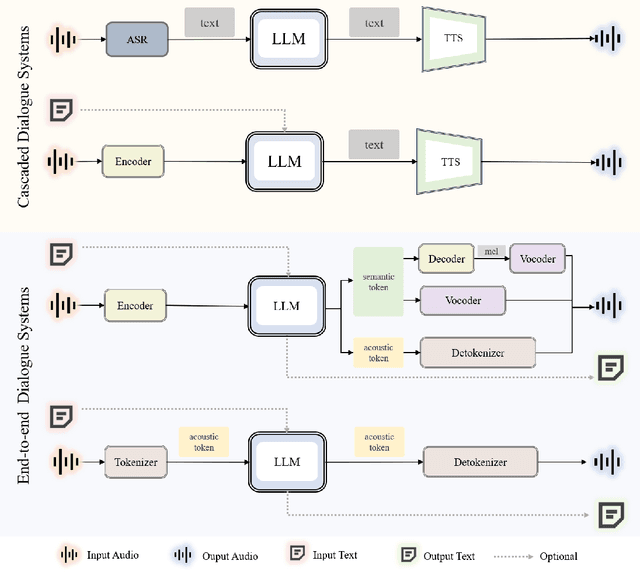
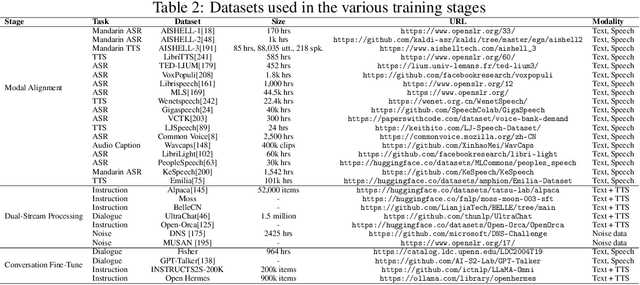
Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.