 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
Gensors: Authoring Personalized Visual Sensors with Multimodal Foundation Models and Reasoning
Jan 27, 2025
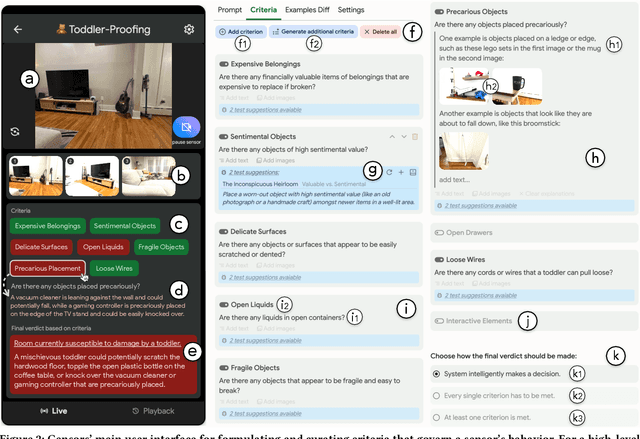
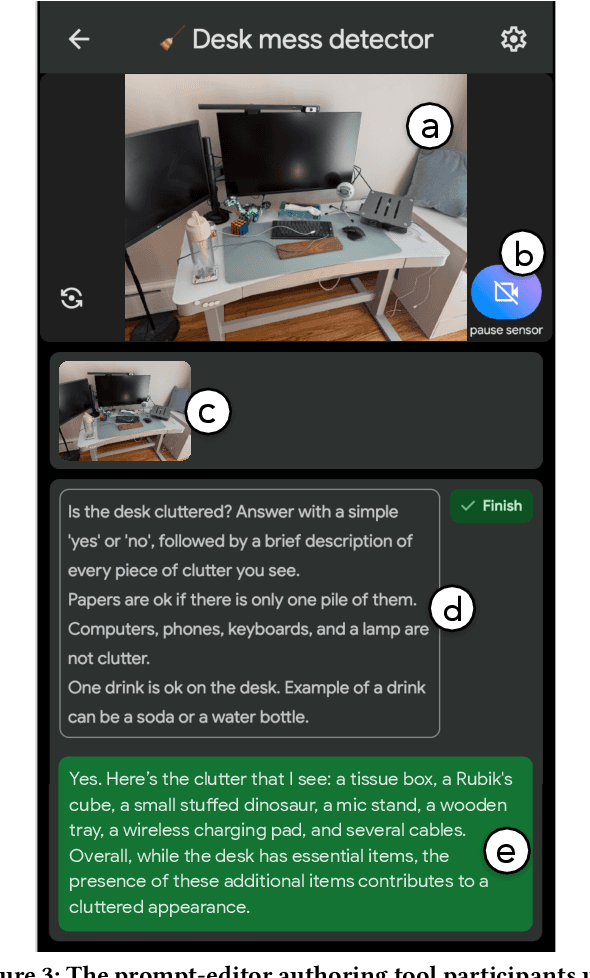
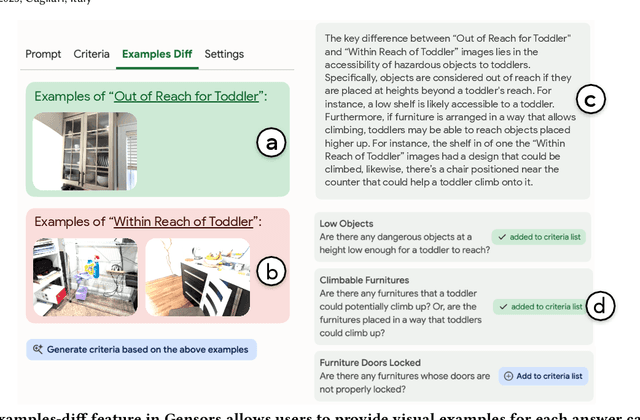
Multimodal large language models (MLLMs), with their expansive world knowledge and reasoning capabilities, present a unique opportunity for end-users to create personalized AI sensors capable of reasoning about complex situations. A user could describe a desired sensing task in natural language (e.g., "alert if my toddler is getting into mischief"), with the MLLM analyzing the camera feed and responding within seconds. In a formative study, we found that users saw substantial value in defining their own sensors, yet struggled to articulate their unique personal requirements and debug the sensors through prompting alone. To address these challenges, we developed Gensors, a system that empowers users to define customized sensors supported by the reasoning capabilities of MLLMs. Gensors 1) assists users in eliciting requirements through both automatically-generated and manually created sensor criteria, 2) facilitates debugging by allowing users to isolate and test individual criteria in parallel, 3) suggests additional criteria based on user-provided images, and 4) proposes test cases to help users "stress test" sensors on potentially unforeseen scenarios. In a user study, participants reported significantly greater sense of control, understanding, and ease of communication when defining sensors using Gensors. Beyond addressing model limitations, Gensors supported users in debugging, eliciting requirements, and expressing unique personal requirements to the sensor through criteria-based reasoning; it also helped uncover users' "blind spots" by exposing overlooked criteria and revealing unanticipated failure modes. Finally, we discuss how unique characteristics of MLLMs--such as hallucinations and inconsistent responses--can impact the sensor-creation process. These findings contribute to the design of future intelligent sensing systems that are intuitive and customizable by everyday users.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
ConstitutionalExperts: Training a Mixture of Principle-based Prompts
Mar 07, 2024



Large language models (LLMs) are highly capable at a variety of tasks given the right prompt, but writing one is still a difficult and tedious process. In this work, we introduce ConstitutionalExperts, a method for learning a prompt consisting of constitutional principles (i.e. rules), given a training dataset. Unlike prior methods that optimize the prompt as a single entity, our method incrementally improves the prompt by surgically editing individual principles. We also show that we can improve overall performance by learning unique prompts for different semantic regions of the training data and using a mixture-of-experts (MoE) architecture to route inputs at inference time. We compare our method to other state of the art prompt-optimization techniques across six benchmark datasets. We also investigate whether MoE improves these other techniques. Our results suggest that ConstitutionalExperts outperforms other prompt optimization techniques by 10.9% (F1) and that mixture-of-experts improves all techniques, suggesting its broad applicability.
ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles
Oct 24, 2023
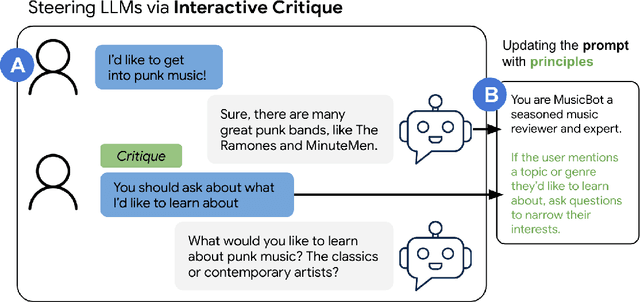
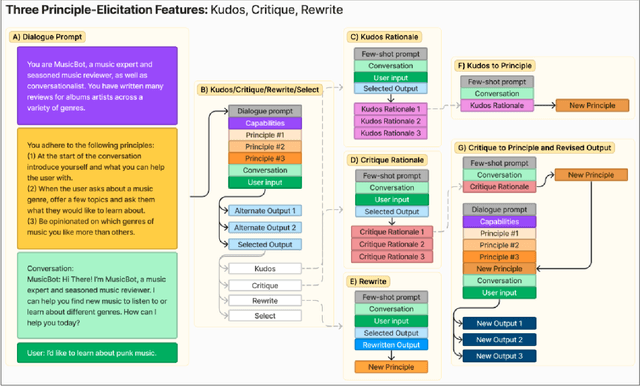
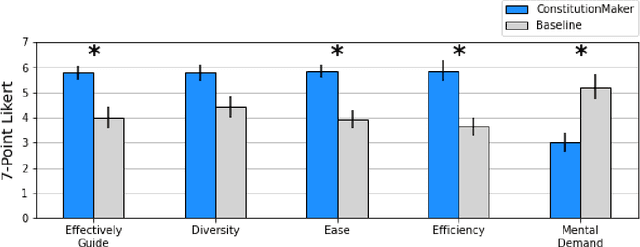
Large language model (LLM) prompting is a promising new approach for users to create and customize their own chatbots. However, current methods for steering a chatbot's outputs, such as prompt engineering and fine-tuning, do not support users in converting their natural feedback on the model's outputs to changes in the prompt or model. In this work, we explore how to enable users to interactively refine model outputs through their feedback, by helping them convert their feedback into a set of principles (i.e. a constitution) that dictate the model's behavior. From a formative study, we (1) found that users needed support converting their feedback into principles for the chatbot and (2) classified the different principle types desired by users. Inspired by these findings, we developed ConstitutionMaker, an interactive tool for converting user feedback into principles, to steer LLM-based chatbots. With ConstitutionMaker, users can provide either positive or negative feedback in natural language, select auto-generated feedback, or rewrite the chatbot's response; each mode of feedback automatically generates a principle that is inserted into the chatbot's prompt. In a user study with 14 participants, we compare ConstitutionMaker to an ablated version, where users write their own principles. With ConstitutionMaker, participants felt that their principles could better guide the chatbot, that they could more easily convert their feedback into principles, and that they could write principles more efficiently, with less mental demand. ConstitutionMaker helped users identify ways to improve the chatbot, formulate their intuitive responses to the model into feedback, and convert this feedback into specific and clear principles. Together, these findings inform future tools that support the interactive critiquing of LLM outputs.
PromptInfuser: How Tightly Coupling AI and UI Design Impacts Designers' Workflows
Oct 24, 2023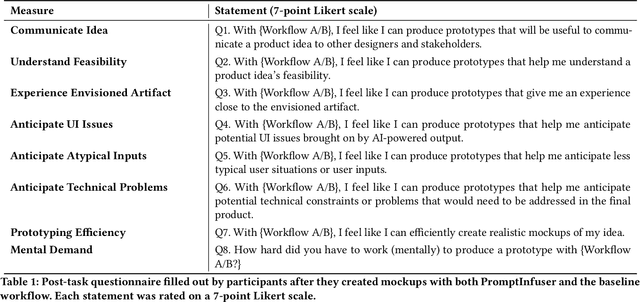


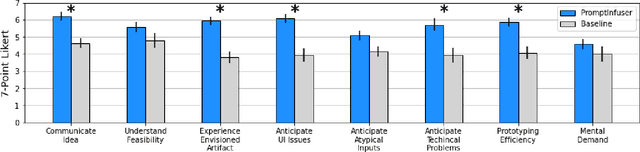
Prototyping AI applications is notoriously difficult. While large language model (LLM) prompting has dramatically lowered the barriers to AI prototyping, designers are still prototyping AI functionality and UI separately. We investigate how coupling prompt and UI design affects designers' workflows. Grounding this research, we developed PromptInfuser, a Figma plugin that enables users to create semi-functional mockups, by connecting UI elements to the inputs and outputs of prompts. In a study with 14 designers, we compare PromptInfuser to designers' current AI-prototyping workflow. PromptInfuser was perceived to be significantly more useful for communicating product ideas, more capable of producing prototypes that realistically represent the envisioned artifact, more efficient for prototyping, and more helpful for anticipating UI issues and technical constraints. PromptInfuser encouraged iteration over prompt and UI together, which helped designers identify UI and prompt incompatibilities and reflect upon their total solution. Together, these findings inform future systems for prototyping AI applications.
Visualizing Linguistic Diversity of Text Datasets Synthesized by Large Language Models
May 19, 2023Large language models (LLMs) can be used to generate smaller, more refined datasets via few-shot prompting for benchmarking, fine-tuning or other use cases. However, understanding and evaluating these datasets is difficult, and the failure modes of LLM-generated data are still not well understood. Specifically, the data can be repetitive in surprising ways, not only semantically but also syntactically and lexically. We present LinguisticLens, a novel inter-active visualization tool for making sense of and analyzing syntactic diversity of LLM-generated datasets. LinguisticLens clusters text along syntactic, lexical, and semantic axes. It supports hierarchical visualization of a text dataset, allowing users to quickly scan for an overview and inspect individual examples. The live demo is available at shorturl.at/zHOUV.
Lightweight Decoding Strategies for Increasing Specificity
Oct 22, 2021
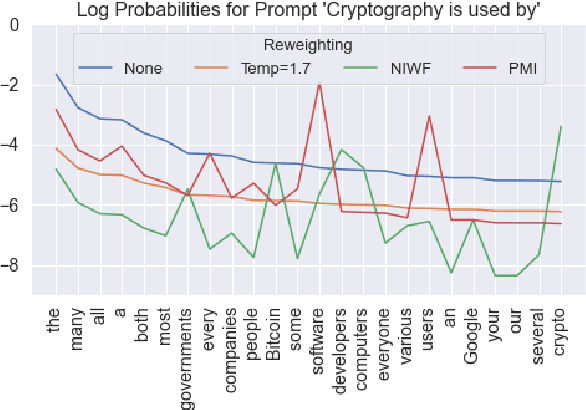

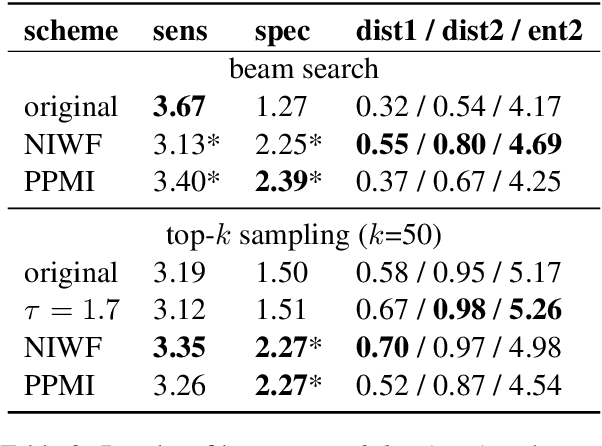
Language models are known to produce vague and generic outputs. We propose two unsupervised decoding strategies based on either word-frequency or point-wise mutual information to increase the specificity of any model that outputs a probability distribution over its vocabulary at generation time. We test the strategies in a prompt completion task; with human evaluations, we find that both strategies increase the specificity of outputs with only modest decreases in sensibility. We also briefly present a summarization use case, where these strategies can produce more specific summaries.