Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Decoding Strategies for Increasing Specificity
Paper and Code
Oct 22, 2021
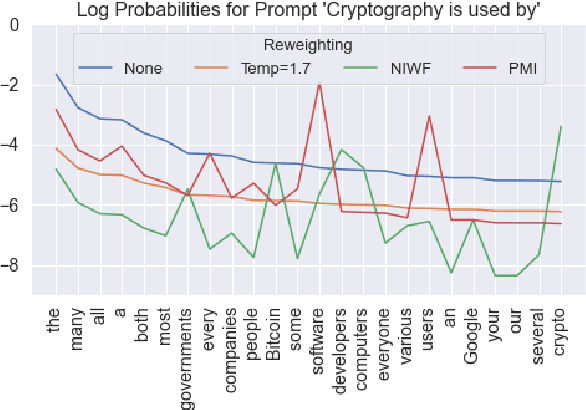

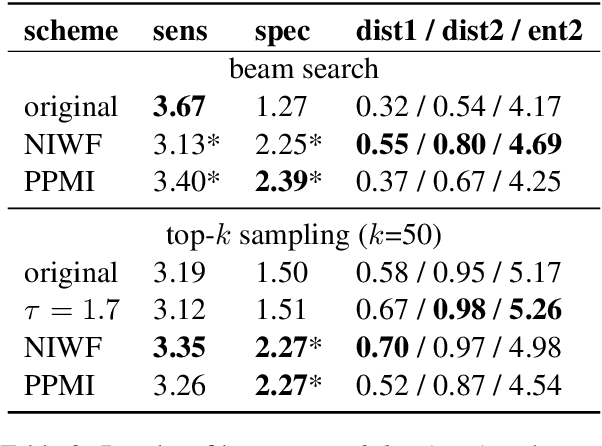
Language models are known to produce vague and generic outputs. We propose two unsupervised decoding strategies based on either word-frequency or point-wise mutual information to increase the specificity of any model that outputs a probability distribution over its vocabulary at generation time. We test the strategies in a prompt completion task; with human evaluations, we find that both strategies increase the specificity of outputs with only modest decreases in sensibility. We also briefly present a summarization use case, where these strategies can produce more specific summaries.
View paper on