 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts
Dec 31, 2024This paper introduces a framework for the automated evaluation of natural language texts. A manually constructed rubric describes how to assess multiple dimensions of interest. To evaluate a text, a large language model (LLM) is prompted with each rubric question and produces a distribution over potential responses. The LLM predictions often fail to agree well with human judges -- indeed, the humans do not fully agree with one another. However, the multiple LLM distributions can be $\textit{combined}$ to $\textit{predict}$ each human judge's annotations on all questions, including a summary question that assesses overall quality or relevance. LLM-Rubric accomplishes this by training a small feed-forward neural network that includes both judge-specific and judge-independent parameters. When evaluating dialogue systems in a human-AI information-seeking task, we find that LLM-Rubric with 9 questions (assessing dimensions such as naturalness, conciseness, and citation quality) predicts human judges' assessment of overall user satisfaction, on a scale of 1--4, with RMS error $< 0.5$, a $2\times$ improvement over the uncalibrated baseline.
* Updated version of 17 June 2024
Do Androids Know They're Only Dreaming of Electric Sheep?
Dec 28, 2023We design probes trained on the internal representations of a transformer language model that are predictive of its hallucinatory behavior on in-context generation tasks. To facilitate this detection, we create a span-annotated dataset of organic and synthetic hallucinations over several tasks. We find that probes trained on the force-decoded states of synthetic hallucinations are generally ecologically invalid in organic hallucination detection. Furthermore, hidden state information about hallucination appears to be task and distribution-dependent. Intrinsic and extrinsic hallucination saliency varies across layers, hidden state types, and tasks; notably, extrinsic hallucinations tend to be more salient in a transformer's internal representations. Outperforming multiple contemporary baselines, we show that probing is a feasible and efficient alternative to language model hallucination evaluation when model states are available.
An analysis of document graph construction methods for AMR summarization
Nov 27, 2021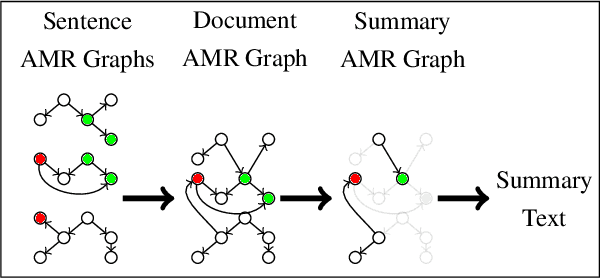
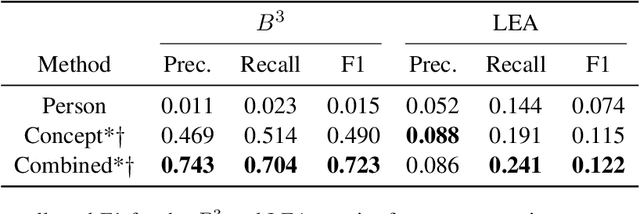
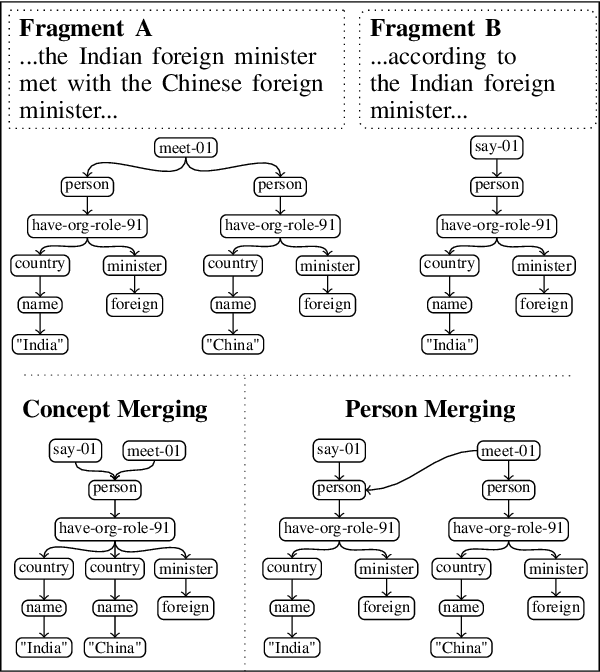
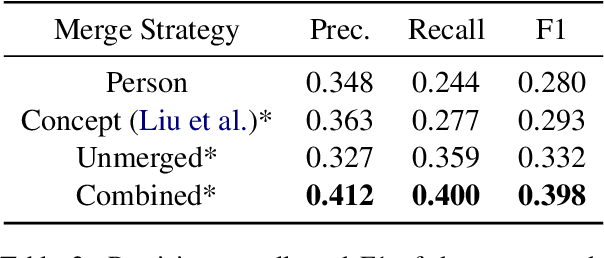
Meaning Representation (AMR) is a graph-based semantic representation for sentences, composed of collections of concepts linked by semantic relations. AMR-based approaches have found success in a variety of applications, but a challenge to using it in tasks that require document-level context is that it only represents individual sentences. Prior work in AMR-based summarization has automatically merged the individual sentence graphs into a document graph, but the method of merging and its effects on summary content selection have not been independently evaluated. In this paper, we present a novel dataset consisting of human-annotated alignments between the nodes of paired documents and summaries which may be used to evaluate (1) merge strategies; and (2) the performance of content selection methods over nodes of a merged or unmerged AMR graph. We apply these two forms of evaluation to prior work as well as a new method for node merging and show that our new method has significantly better performance than prior work.
Lightweight Decoding Strategies for Increasing Specificity
Oct 22, 2021
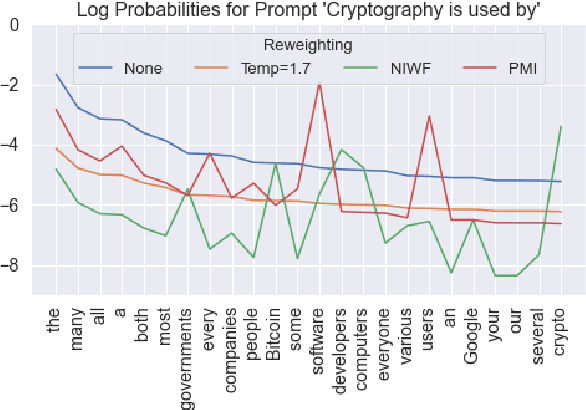

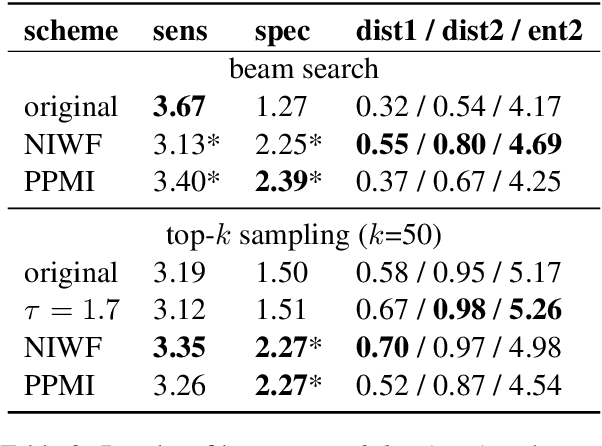
Language models are known to produce vague and generic outputs. We propose two unsupervised decoding strategies based on either word-frequency or point-wise mutual information to increase the specificity of any model that outputs a probability distribution over its vocabulary at generation time. We test the strategies in a prompt completion task; with human evaluations, we find that both strategies increase the specificity of outputs with only modest decreases in sensibility. We also briefly present a summarization use case, where these strategies can produce more specific summaries.
Cross-language Sentence Selection via Data Augmentation and Rationale Training
Jun 04, 2021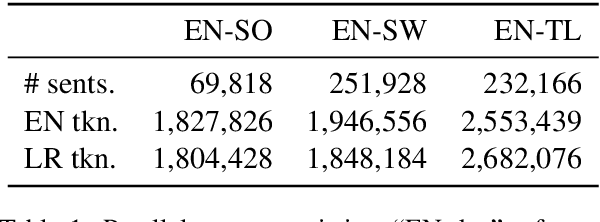
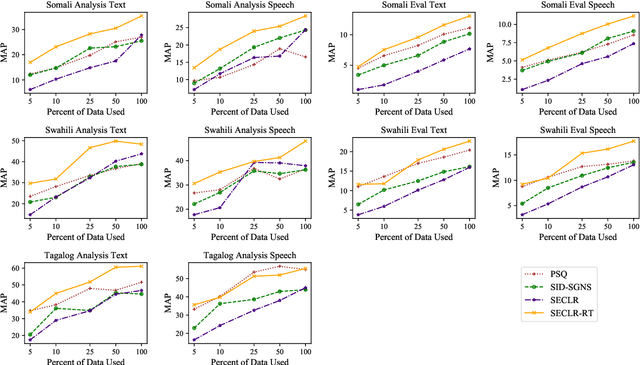
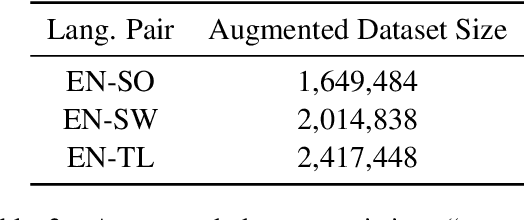
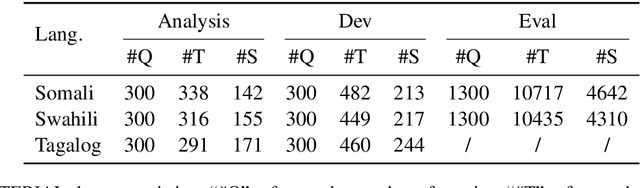
This paper proposes an approach to cross-language sentence selection in a low-resource setting. It uses data augmentation and negative sampling techniques on noisy parallel sentence data to directly learn a cross-lingual embedding-based query relevance model. Results show that this approach performs as well as or better than multiple state-of-the-art machine translation + monolingual retrieval systems trained on the same parallel data. Moreover, when a rationale training secondary objective is applied to encourage the model to match word alignment hints from a phrase-based statistical machine translation model, consistent improvements are seen across three language pairs (English-Somali, English-Swahili and English-Tagalog) over a variety of state-of-the-art baselines.
Segmenting Subtitles for Correcting ASR Segmentation Errors
Apr 16, 2021
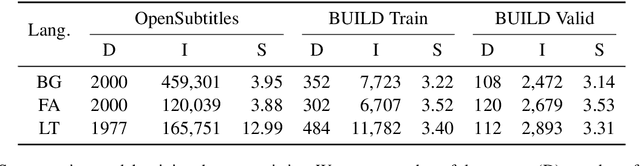

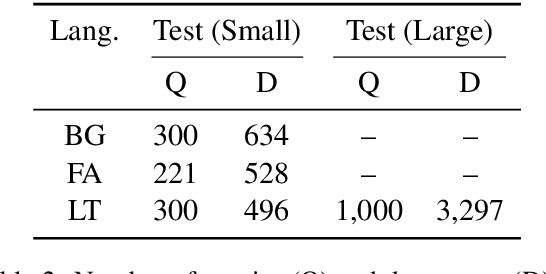
Typical ASR systems segment the input audio into utterances using purely acoustic information, which may not resemble the sentence-like units that are expected by conventional machine translation (MT) systems for Spoken Language Translation. In this work, we propose a model for correcting the acoustic segmentation of ASR models for low-resource languages to improve performance on downstream tasks. We propose the use of subtitles as a proxy dataset for correcting ASR acoustic segmentation, creating synthetic acoustic utterances by modeling common error modes. We train a neural tagging model for correcting ASR acoustic segmentation and show that it improves downstream performance on MT and audio-document cross-language information retrieval (CLIR).
Subtitles to Segmentation: Improving Low-Resource Speech-to-Text Translation Pipelines
Oct 19, 2020

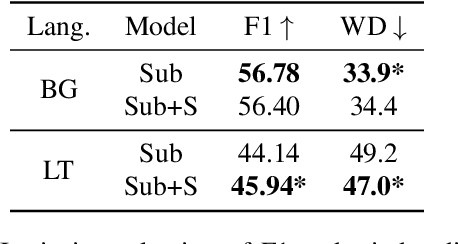

In this work, we focus on improving ASR output segmentation in the context of low-resource language speech-to-text translation. ASR output segmentation is crucial, as ASR systems segment the input audio using purely acoustic information and are not guaranteed to output sentence-like segments. Since most MT systems expect sentences as input, feeding in longer unsegmented passages can lead to sub-optimal performance. We explore the feasibility of using datasets of subtitles from TV shows and movies to train better ASR segmentation models. We further incorporate part-of-speech (POS) tag and dependency label information (derived from the unsegmented ASR outputs) into our segmentation model. We show that this noisy syntactic information can improve model accuracy. We evaluate our models intrinsically on segmentation quality and extrinsically on downstream MT performance, as well as downstream tasks including cross-lingual information retrieval (CLIR) tasks and human relevance assessments. Our model shows improved performance on downstream tasks for Lithuanian and Bulgarian.
Incorporating Terminology Constraints in Automatic Post-Editing
Oct 19, 2020

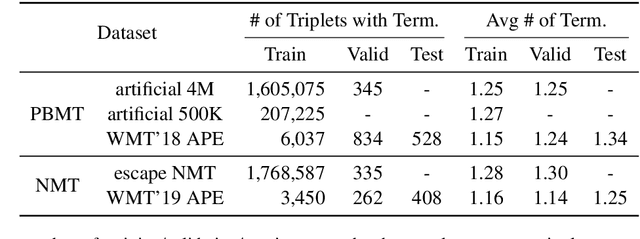
Users of machine translation (MT) may want to ensure the use of specific lexical terminologies. While there exist techniques for incorporating terminology constraints during inference for MT, current APE approaches cannot ensure that they will appear in the final translation. In this paper, we present both autoregressive and non-autoregressive models for lexically constrained APE, demonstrating that our approach enables preservation of 95% of the terminologies and also improves translation quality on English-German benchmarks. Even when applied to lexically constrained MT output, our approach is able to improve preservation of the terminologies. However, we show that our models do not learn to copy constraints systematically and suggest a simple data augmentation technique that leads to improved performance and robustness.
Low-Level Linguistic Controls for Style Transfer and Content Preservation
Nov 08, 2019
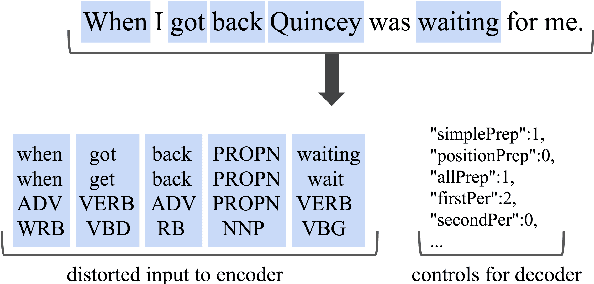
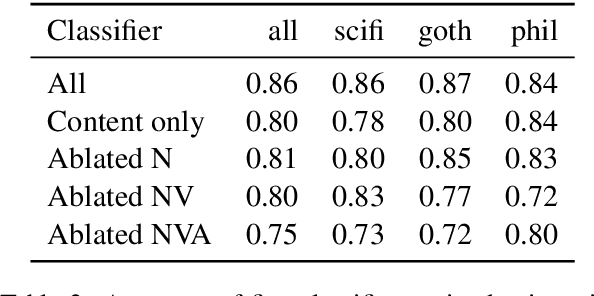
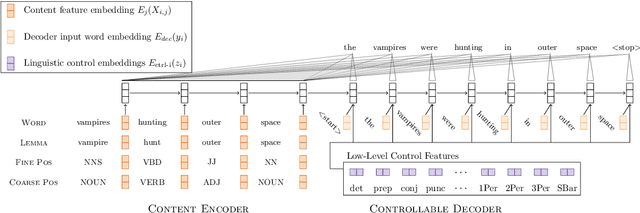
Despite the success of style transfer in image processing, it has seen limited progress in natural language generation. Part of the problem is that content is not as easily decoupled from style in the text domain. Curiously, in the field of stylometry, content does not figure prominently in practical methods of discriminating stylistic elements, such as authorship and genre. Rather, syntax and function words are the most salient features. Drawing on this work, we model style as a suite of low-level linguistic controls, such as frequency of pronouns, prepositions, and subordinate clause constructions. We train a neural encoder-decoder model to reconstruct reference sentences given only content words and the setting of the controls. We perform style transfer by keeping the content words fixed while adjusting the controls to be indicative of another style. In experiments, we show that the model reliably responds to the linguistic controls and perform both automatic and manual evaluations on style transfer. We find we can fool a style classifier 84% of the time, and that our model produces highly diverse and stylistically distinctive outputs. This work introduces a formal, extendable model of style that can add control to any neural text generation system.
A Good Sample is Hard to Find: Noise Injection Sampling and Self-Training for Neural Language Generation Models
Nov 08, 2019



Deep neural networks (DNN) are quickly becoming the de facto standard modeling method for many natural language generation (NLG) tasks. In order for such models to truly be useful, they must be capable of correctly generating utterances for novel meaning representations (MRs) at test time. In practice, even sophisticated DNNs with various forms of semantic control frequently fail to generate utterances faithful to the input MR. In this paper, we propose an architecture agnostic self-training method to sample novel MR/text utterance pairs to augment the original training data. Remarkably, after training on the augmented data, even simple encoder-decoder models with greedy decoding are capable of generating semantically correct utterances that are as good as state-of-the-art outputs in both automatic and human evaluations of quality.