 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Authenticity, Consent, & Provenance for AI are all broken: what will it take to fix them?
Apr 19, 2024

New capabilities in foundation models are owed in large part to massive, widely-sourced, and under-documented training data collections. Existing practices in data collection have led to challenges in documenting data transparency, tracing authenticity, verifying consent, privacy, representation, bias, copyright infringement, and the overall development of ethical and trustworthy foundation models. In response, regulation is emphasizing the need for training data transparency to understand foundation models' limitations. Based on a large-scale analysis of the foundation model training data landscape and existing solutions, we identify the missing infrastructure to facilitate responsible foundation model development practices. We examine the current shortcomings of common tools for tracing data authenticity, consent, and documentation, and outline how policymakers, developers, and data creators can facilitate responsible foundation model development by adopting universal data provenance standards.
Low-Level Linguistic Controls for Style Transfer and Content Preservation
Nov 08, 2019
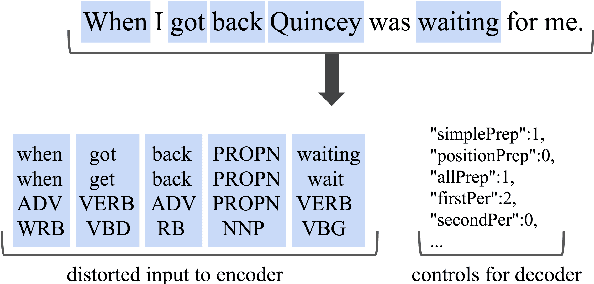
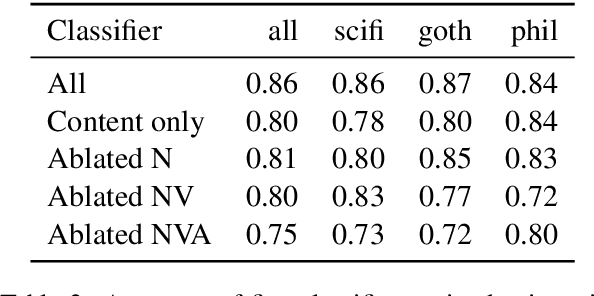
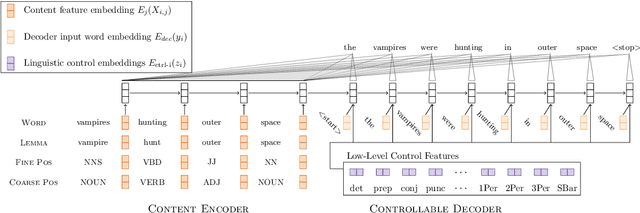
Despite the success of style transfer in image processing, it has seen limited progress in natural language generation. Part of the problem is that content is not as easily decoupled from style in the text domain. Curiously, in the field of stylometry, content does not figure prominently in practical methods of discriminating stylistic elements, such as authorship and genre. Rather, syntax and function words are the most salient features. Drawing on this work, we model style as a suite of low-level linguistic controls, such as frequency of pronouns, prepositions, and subordinate clause constructions. We train a neural encoder-decoder model to reconstruct reference sentences given only content words and the setting of the controls. We perform style transfer by keeping the content words fixed while adjusting the controls to be indicative of another style. In experiments, we show that the model reliably responds to the linguistic controls and perform both automatic and manual evaluations on style transfer. We find we can fool a style classifier 84% of the time, and that our model produces highly diverse and stylistically distinctive outputs. This work introduces a formal, extendable model of style that can add control to any neural text generation system.