 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity Management for Agentic AI: The new frontier of authorization, authentication, and security for an AI agent world
Oct 29, 2025The rapid rise of AI agents presents urgent challenges in authentication, authorization, and identity management. Current agent-centric protocols (like MCP) highlight the demand for clarified best practices in authentication and authorization. Looking ahead, ambitions for highly autonomous agents raise complex long-term questions regarding scalable access control, agent-centric identities, AI workload differentiation, and delegated authority. This OpenID Foundation whitepaper is for stakeholders at the intersection of AI agents and access management. It outlines the resources already available for securing today's agents and presents a strategic agenda to address the foundational authentication, authorization, and identity problems pivotal for tomorrow's widespread autonomous systems.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Authenticated Delegation and Authorized AI Agents
Jan 16, 2025



The rapid deployment of autonomous AI agents creates urgent challenges around authorization, accountability, and access control in digital spaces. New standards are needed to know whom AI agents act on behalf of and guide their use appropriately, protecting online spaces while unlocking the value of task delegation to autonomous agents. We introduce a novel framework for authenticated, authorized, and auditable delegation of authority to AI agents, where human users can securely delegate and restrict the permissions and scope of agents while maintaining clear chains of accountability. This framework builds on existing identification and access management protocols, extending OAuth 2.0 and OpenID Connect with agent-specific credentials and metadata, maintaining compatibility with established authentication and web infrastructure. Further, we propose a framework for translating flexible, natural language permissions into auditable access control configurations, enabling robust scoping of AI agent capabilities across diverse interaction modalities. Taken together, this practical approach facilitates immediate deployment of AI agents while addressing key security and accountability concerns, working toward ensuring agentic AI systems perform only appropriate actions and providing a tool for digital service providers to enable AI agent interactions without risking harm from scalable interaction.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


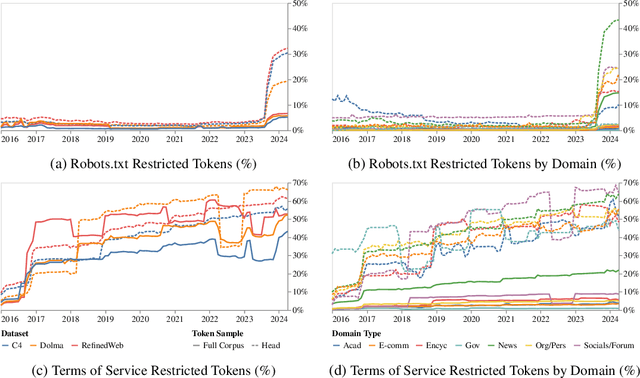
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
Data Authenticity, Consent, & Provenance for AI are all broken: what will it take to fix them?
Apr 19, 2024

New capabilities in foundation models are owed in large part to massive, widely-sourced, and under-documented training data collections. Existing practices in data collection have led to challenges in documenting data transparency, tracing authenticity, verifying consent, privacy, representation, bias, copyright infringement, and the overall development of ethical and trustworthy foundation models. In response, regulation is emphasizing the need for training data transparency to understand foundation models' limitations. Based on a large-scale analysis of the foundation model training data landscape and existing solutions, we identify the missing infrastructure to facilitate responsible foundation model development practices. We examine the current shortcomings of common tools for tracing data authenticity, consent, and documentation, and outline how policymakers, developers, and data creators can facilitate responsible foundation model development by adopting universal data provenance standards.
Verifiable evaluations of machine learning models using zkSNARKs
Feb 05, 2024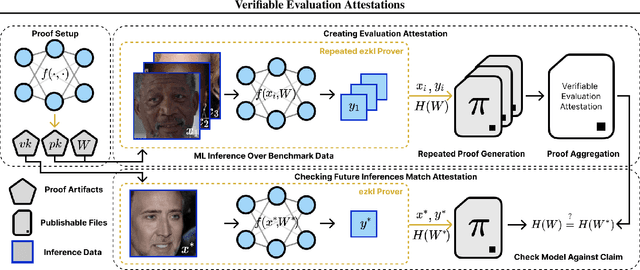

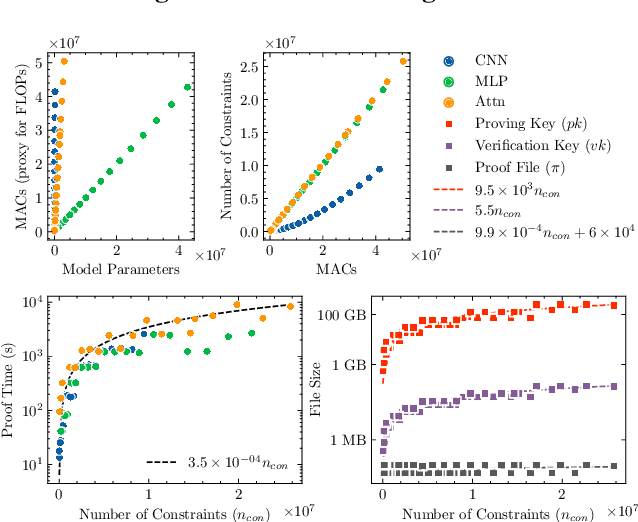
In a world of increasing closed-source commercial machine learning models, model evaluations from developers must be taken at face value. These benchmark results, whether over task accuracy, bias evaluations, or safety checks, are traditionally impossible to verify by a model end-user without the costly or impossible process of re-performing the benchmark on black-box model outputs. This work presents a method of verifiable model evaluation using model inference through zkSNARKs. The resulting zero-knowledge computational proofs of model outputs over datasets can be packaged into verifiable evaluation attestations showing that models with fixed private weights achieve stated performance or fairness metrics over public inputs. These verifiable attestations can be performed on any standard neural network model with varying compute requirements. For the first time, we demonstrate this across a sample of real-world models and highlight key challenges and design solutions. This presents a new transparency paradigm in the verifiable evaluation of private models.
Don't forget private retrieval: distributed private similarity search for large language models
Nov 21, 2023While the flexible capabilities of large language models (LLMs) allow them to answer a range of queries based on existing learned knowledge, information retrieval to augment generation is an important tool to allow LLMs to answer questions on information not included in pre-training data. Such private information is increasingly being generated in a wide array of distributed contexts by organizations and individuals. Performing such information retrieval using neural embeddings of queries and documents always leaked information about queries and database content unless both were stored locally. We present Private Retrieval Augmented Generation (PRAG), an approach that uses multi-party computation (MPC) to securely transmit queries to a distributed set of servers containing a privately constructed database to return top-k and approximate top-k documents. This is a first-of-its-kind approach to dense information retrieval that ensures no server observes a client's query or can see the database content. The approach introduces a novel MPC friendly protocol for inverted file approximate search (IVF) that allows for fast document search over distributed and private data in sublinear communication complexity. This work presents new avenues through which data for use in LLMs can be accessed and used without needing to centralize or forgo privacy.