 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Nov 07, 2024
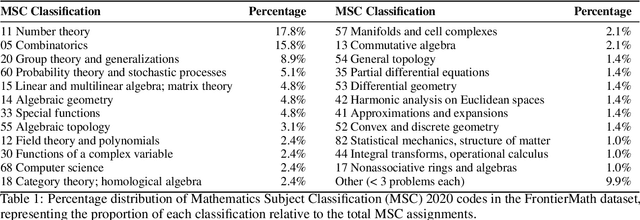
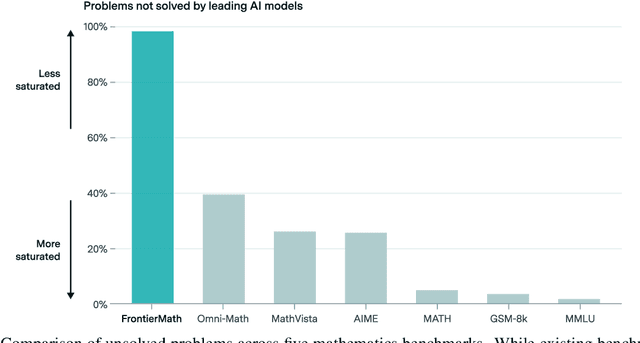
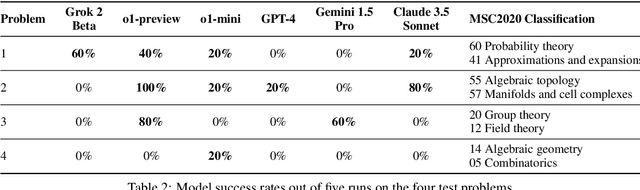
We introduce FrontierMath, a benchmark of hundreds of original, exceptionally challenging mathematics problems crafted and vetted by expert mathematicians. The questions cover most major branches of modern mathematics -- from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days. FrontierMath uses new, unpublished problems and automated verification to reliably evaluate models while minimizing risk of data contamination. Current state-of-the-art AI models solve under 2% of problems, revealing a vast gap between AI capabilities and the prowess of the mathematical community. As AI systems advance toward expert-level mathematical abilities, FrontierMath offers a rigorous testbed that quantifies their progress.
Chinchilla Scaling: A replication attempt
Apr 15, 2024Hoffmann et al. (2022) propose three methods for estimating a compute-optimal scaling law. We attempt to replicate their third estimation procedure, which involves fitting a parametric loss function to a reconstruction of data from their plots. We find that the reported estimates are inconsistent with their first two estimation methods, fail at fitting the extracted data, and report implausibly narrow confidence intervals--intervals this narrow would require over 600,000 experiments, while they likely only ran fewer than 500. In contrast, our rederivation of the scaling law using the third approach yields results that are compatible with the findings from the first two estimation procedures described by Hoffmann et al.
Algorithmic progress in language models
Mar 09, 2024
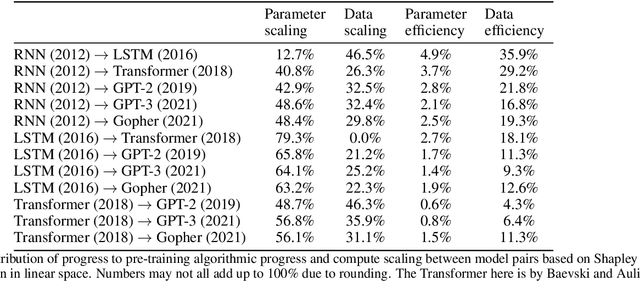

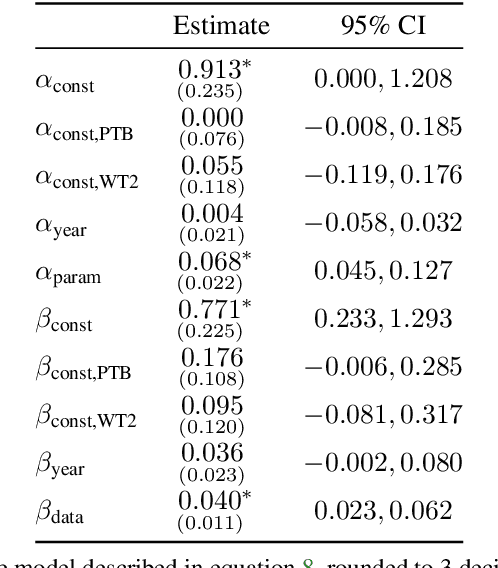
We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law. We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in compute made an even larger contribution to overall performance improvements over this time period. Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from compute and algorithms.
The Compute Divide in Machine Learning: A Threat to Academic Contribution and Scrutiny?
Jan 08, 2024



There are pronounced differences in the extent to which industrial and academic AI labs use computing resources. We provide a data-driven survey of the role of the compute divide in shaping machine learning research. We show that a compute divide has coincided with a reduced representation of academic-only research teams in compute intensive research topics, especially foundation models. We argue that, academia will likely play a smaller role in advancing the associated techniques, providing critical evaluation and scrutiny, and in the diffusion of such models. Concurrent with this change in research focus, there is a noticeable shift in academic research towards embracing open source, pre-trained models developed within the industry. To address the challenges arising from this trend, especially reduced scrutiny of influential models, we recommend approaches aimed at thoughtfully expanding academic insights. Nationally-sponsored computing infrastructure coupled with open science initiatives could judiciously boost academic compute access, prioritizing research on interpretability, safety and security. Structured access programs and third-party auditing may also allow measured external evaluation of industry systems.
Who is leading in AI? An analysis of industry AI research
Nov 24, 2023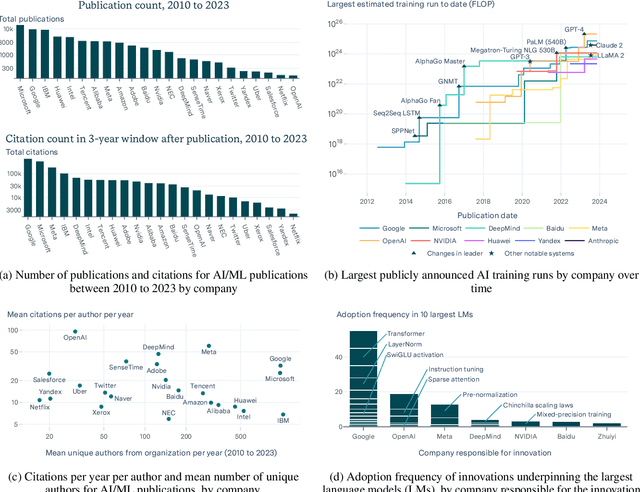
AI research is increasingly industry-driven, making it crucial to understand company contributions to this field. We compare leading AI companies by research publications, citations, size of training runs, and contributions to algorithmic innovations. Our analysis reveals the substantial role played by Google, OpenAI and Meta. We find that these three companies have been responsible for some of the largest training runs, developed a large fraction of the algorithmic innovations that underpin large language models, and led in various metrics of citation impact. In contrast, leading Chinese companies such as Tencent and Baidu had a lower impact on many of these metrics compared to US counterparts. We observe many industry labs are pursuing large training runs, and that training runs from relative newcomers -- such as OpenAI and Anthropic -- have matched or surpassed those of long-standing incumbents such as Google. The data reveals a diverse ecosystem of companies steering AI progress, though US labs such as Google, OpenAI and Meta lead across critical metrics.
Algorithmic progress in computer vision
Dec 16, 2022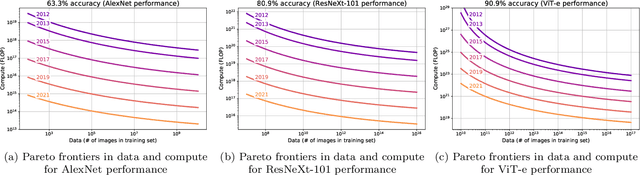
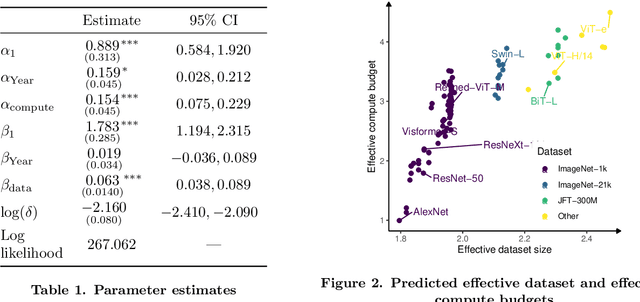
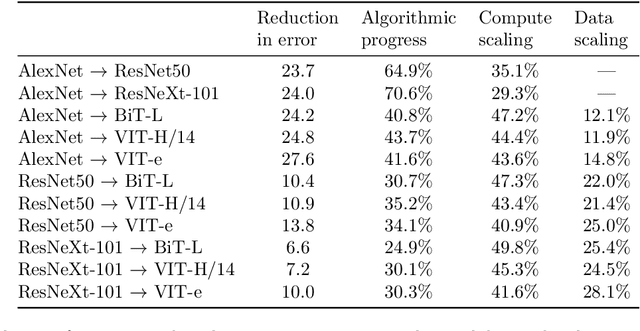
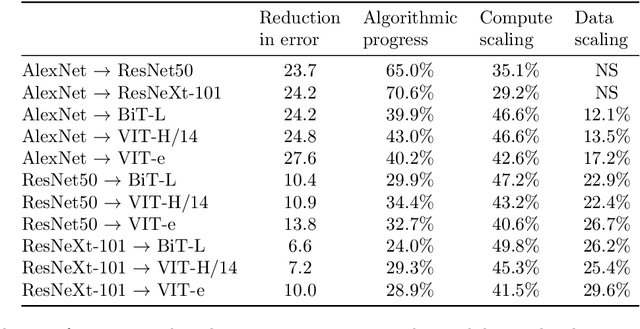
We investigate algorithmic progress in image classification on ImageNet, perhaps the most well-known test bed for computer vision. We estimate a model, informed by work on neural scaling laws, and infer a decomposition of progress into the scaling of compute, data, and algorithms. Using Shapley values to attribute performance improvements, we find that algorithmic improvements have been roughly as important as the scaling of compute for progress computer vision. Our estimates indicate that algorithmic innovations mostly take the form of compute-augmenting algorithmic advances (which enable researchers to get better performance from less compute), not data-augmenting algorithmic advances. We find that compute-augmenting algorithmic advances are made at a pace more than twice as fast as the rate usually associated with Moore's law. In particular, we estimate that compute-augmenting innovations halve compute requirements every nine months (95\% confidence interval: 4 to 25 months).
Machine Learning Model Sizes and the Parameter Gap
Jul 05, 2022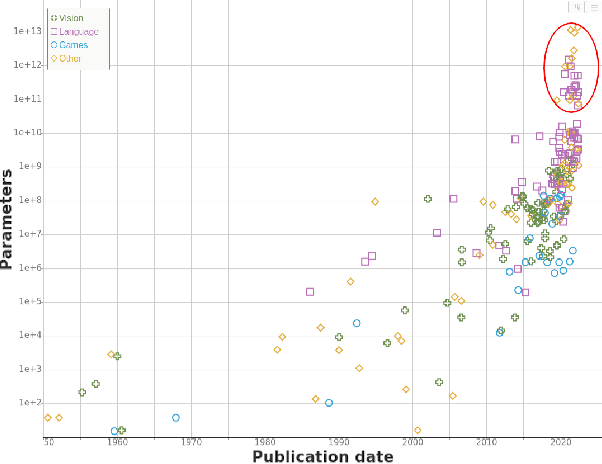
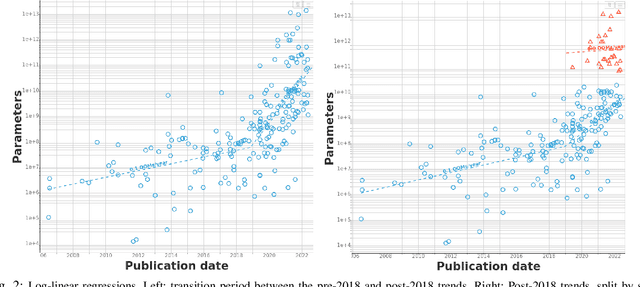
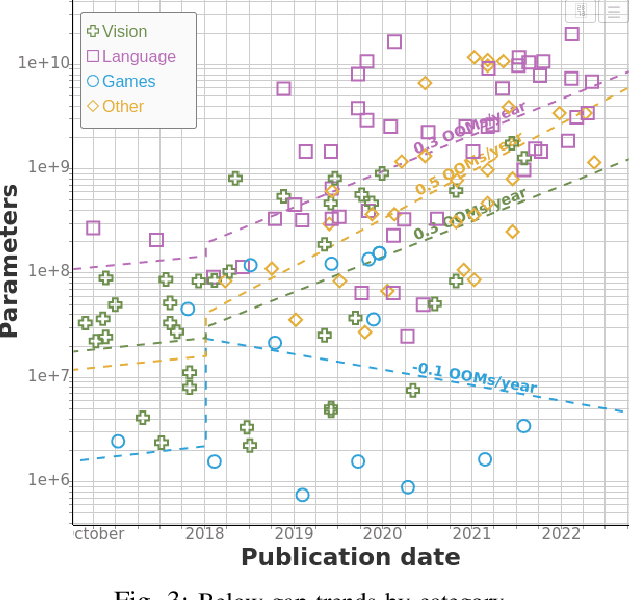
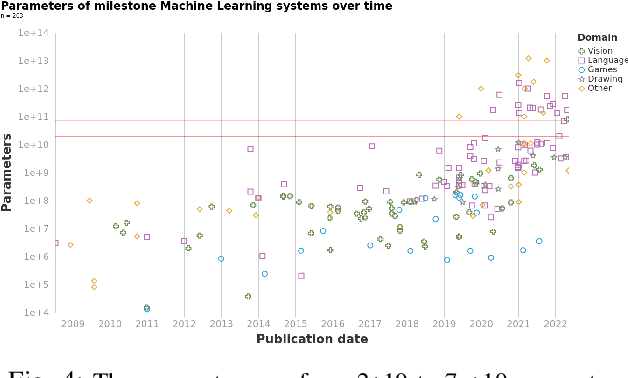
We study trends in model size of notable machine learning systems over time using a curated dataset. From 1950 to 2018, model size in language models increased steadily by seven orders of magnitude. The trend then accelerated, with model size increasing by another five orders of magnitude in just 4 years from 2018 to 2022. Vision models grew at a more constant pace, totaling 7 orders of magnitude of growth between 1950 and 2022. We also identify that, since 2020, there have been many language models below 20B parameters, many models above 70B parameters, but a scarcity of models in the 20-70B parameter range. We refer to that scarcity as the parameter gap. We provide some stylized facts about the parameter gap and propose a few hypotheses to explain it. The explanations we favor are: (a) increasing model size beyond 20B parameters requires adopting different parallelism techniques, which makes mid-sized models less cost-effective, (b) GPT-3 was one order of magnitude larger than previous language models, and researchers afterwards primarily experimented with bigger models to outperform it. While these dynamics likely exist, and we believe they play some role in generating the gap, we don't have high confidence that there are no other, more important dynamics at play.
Compute Trends Across Three Eras of Machine Learning
Mar 09, 2022
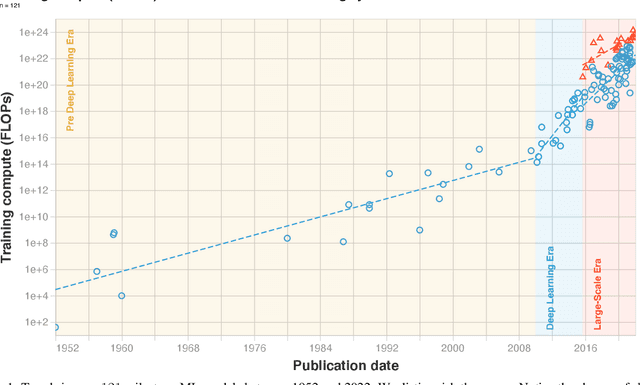
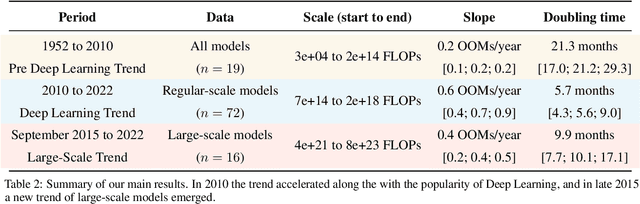
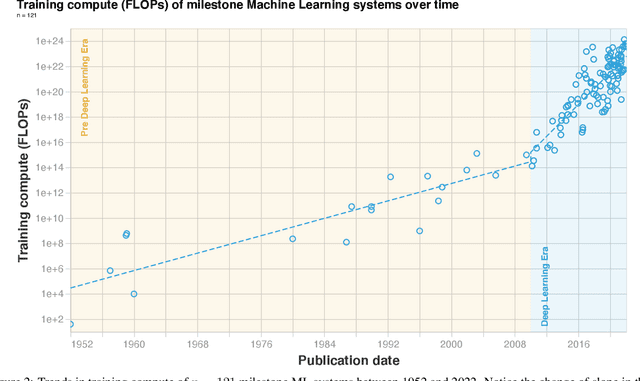
Compute, data, and algorithmic advances are the three fundamental factors that guide the progress of modern Machine Learning (ML). In this paper we study trends in the most readily quantified factor - compute. We show that before 2010 training compute grew in line with Moore's law, doubling roughly every 20 months. Since the advent of Deep Learning in the early 2010s, the scaling of training compute has accelerated, doubling approximately every 6 months. In late 2015, a new trend emerged as firms developed large-scale ML models with 10 to 100-fold larger requirements in training compute. Based on these observations we split the history of compute in ML into three eras: the Pre Deep Learning Era, the Deep Learning Era and the Large-Scale Era. Overall, our work highlights the fast-growing compute requirements for training advanced ML systems.