 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI capabilities can be significantly improved without expensive retraining
Dec 12, 2023



State-of-the-art AI systems can be significantly improved without expensive retraining via "post-training enhancements"-techniques applied after initial training like fine-tuning the system to use a web browser. We review recent post-training enhancements, categorizing them into five types: tool-use, prompting methods, scaffolding, solution selection, and data generation. Different enhancements improve performance on different tasks, making it hard to compare their significance. So we translate improvements from different enhancements into a common currency, the compute-equivalent gain: how much additional training compute would be needed to improve performance by the same amount as the enhancement. Our non-experimental work shows that post-training enhancements have significant benefits: most surveyed enhancements improve benchmark performance by more than a 5x increase in training compute, some by more than 20x. Post-training enhancements are relatively cheap to develop: fine-tuning costs are typically <1% of the original training cost. Governing the development of capable post-training enhancements may be challenging because frontier models could be enhanced by a wide range of actors.
Machine Learning Model Sizes and the Parameter Gap
Jul 05, 2022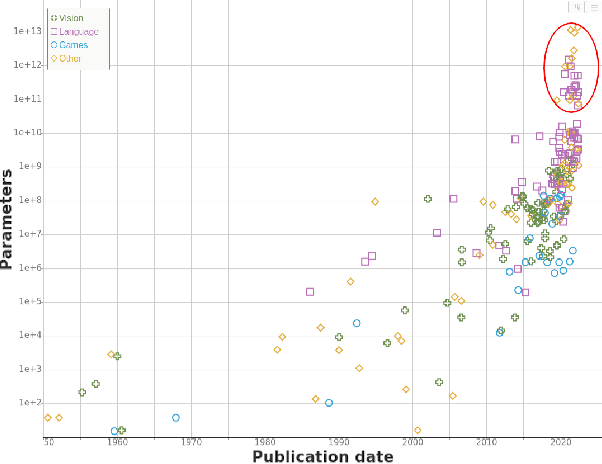
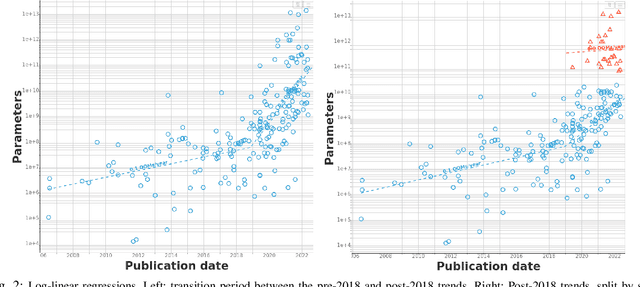
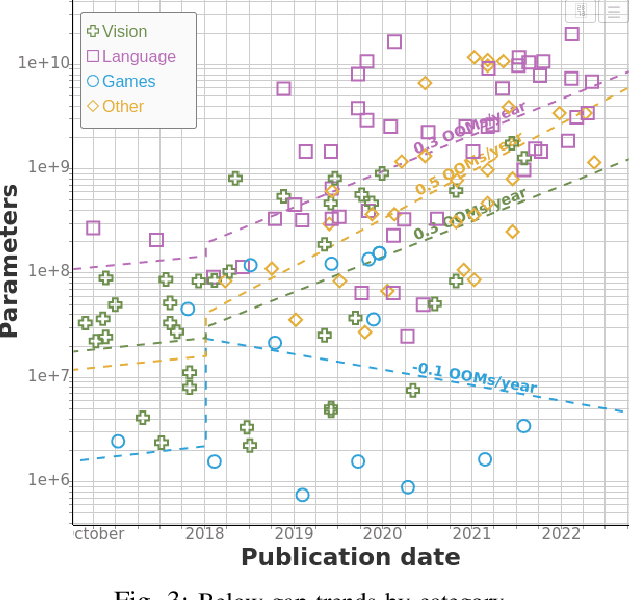
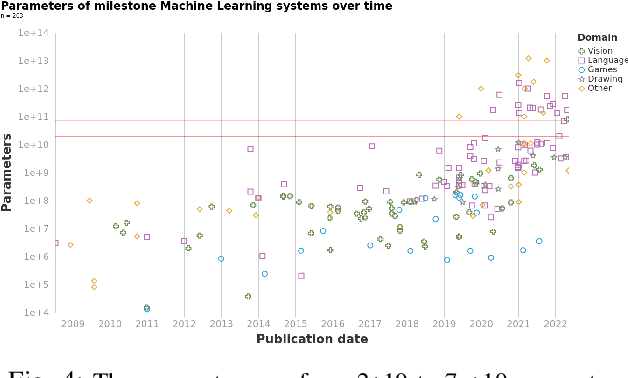
We study trends in model size of notable machine learning systems over time using a curated dataset. From 1950 to 2018, model size in language models increased steadily by seven orders of magnitude. The trend then accelerated, with model size increasing by another five orders of magnitude in just 4 years from 2018 to 2022. Vision models grew at a more constant pace, totaling 7 orders of magnitude of growth between 1950 and 2022. We also identify that, since 2020, there have been many language models below 20B parameters, many models above 70B parameters, but a scarcity of models in the 20-70B parameter range. We refer to that scarcity as the parameter gap. We provide some stylized facts about the parameter gap and propose a few hypotheses to explain it. The explanations we favor are: (a) increasing model size beyond 20B parameters requires adopting different parallelism techniques, which makes mid-sized models less cost-effective, (b) GPT-3 was one order of magnitude larger than previous language models, and researchers afterwards primarily experimented with bigger models to outperform it. While these dynamics likely exist, and we believe they play some role in generating the gap, we don't have high confidence that there are no other, more important dynamics at play.
Compute Trends Across Three Eras of Machine Learning
Mar 09, 2022
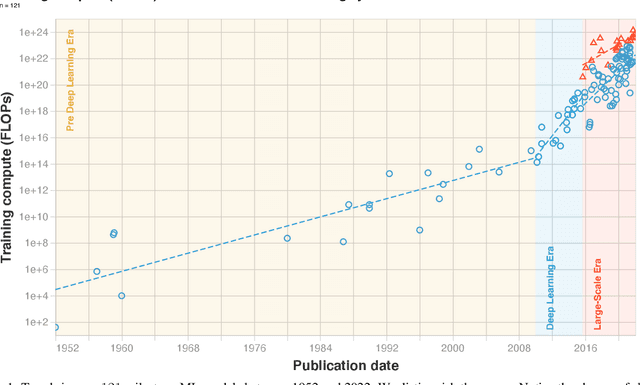
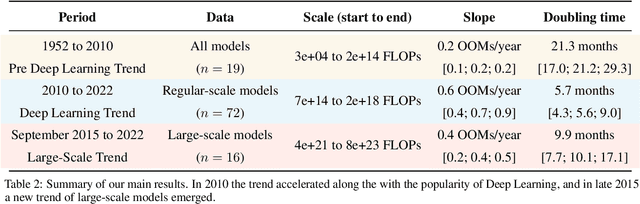
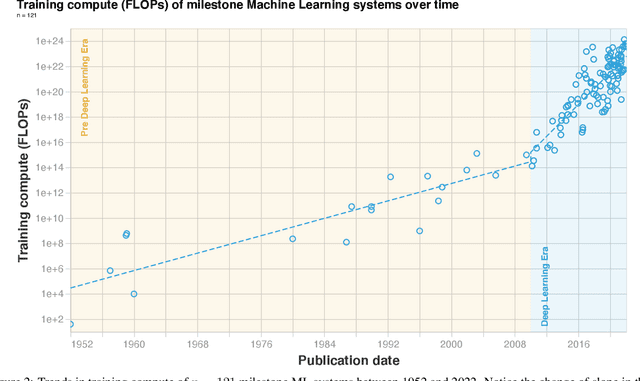
Compute, data, and algorithmic advances are the three fundamental factors that guide the progress of modern Machine Learning (ML). In this paper we study trends in the most readily quantified factor - compute. We show that before 2010 training compute grew in line with Moore's law, doubling roughly every 20 months. Since the advent of Deep Learning in the early 2010s, the scaling of training compute has accelerated, doubling approximately every 6 months. In late 2015, a new trend emerged as firms developed large-scale ML models with 10 to 100-fold larger requirements in training compute. Based on these observations we split the history of compute in ML into three eras: the Pre Deep Learning Era, the Deep Learning Era and the Large-Scale Era. Overall, our work highlights the fast-growing compute requirements for training advanced ML systems.