 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Nov 07, 2024
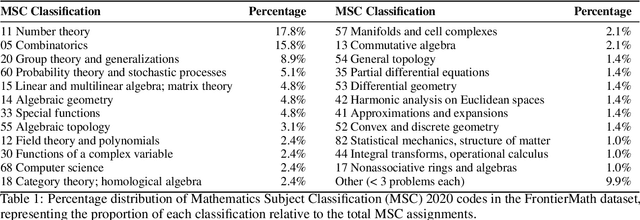
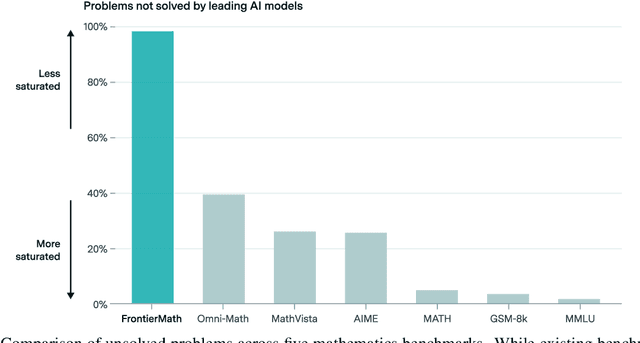
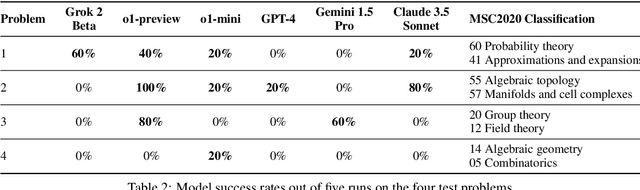
We introduce FrontierMath, a benchmark of hundreds of original, exceptionally challenging mathematics problems crafted and vetted by expert mathematicians. The questions cover most major branches of modern mathematics -- from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days. FrontierMath uses new, unpublished problems and automated verification to reliably evaluate models while minimizing risk of data contamination. Current state-of-the-art AI models solve under 2% of problems, revealing a vast gap between AI capabilities and the prowess of the mathematical community. As AI systems advance toward expert-level mathematical abilities, FrontierMath offers a rigorous testbed that quantifies their progress.
Algorithmic progress in language models
Mar 09, 2024
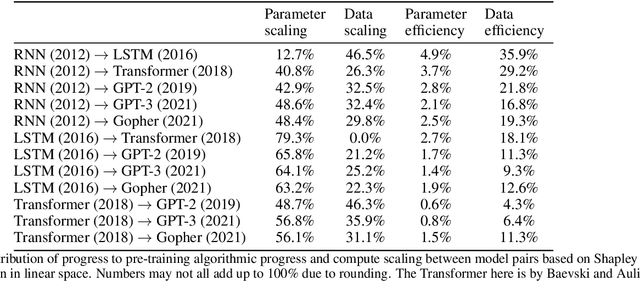

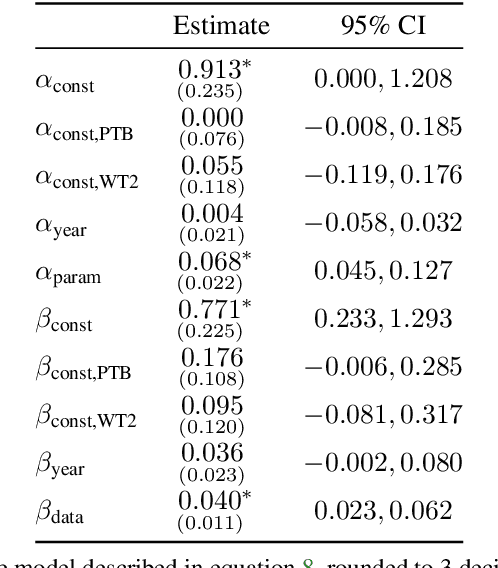
We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law. We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in compute made an even larger contribution to overall performance improvements over this time period. Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from compute and algorithms.
Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks
Jul 28, 2022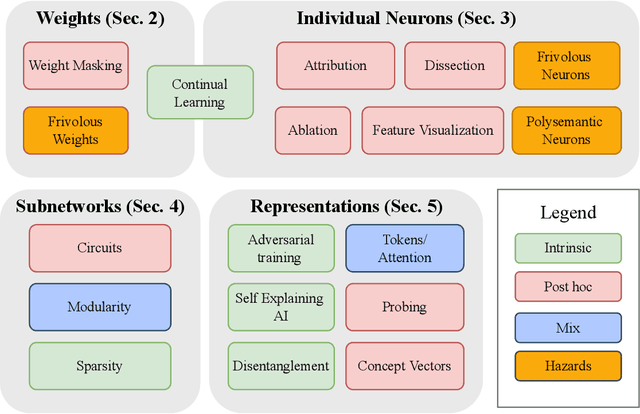
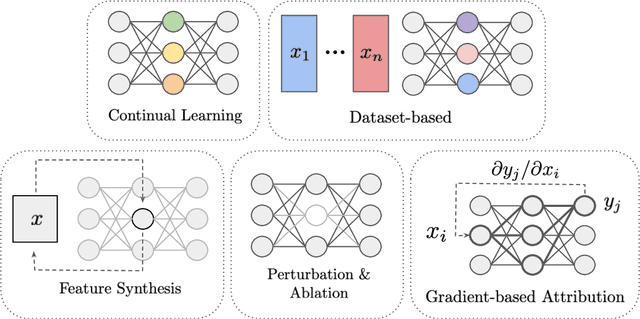
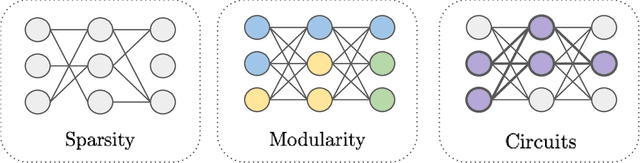

The last decade of machine learning has seen drastic increases in scale and capabilities, and deep neural networks (DNNs) are increasingly being deployed across a wide range of domains. However, the inner workings of DNNs are generally difficult to understand, raising concerns about the safety of using these systems without a rigorous understanding of how they function. In this survey, we review literature on techniques for interpreting the inner components of DNNs, which we call "inner" interpretability methods. Specifically, we review methods for interpreting weights, neurons, subnetworks, and latent representations with a focus on how these techniques relate to the goal of designing safer, more trustworthy AI systems. We also highlight connections between interpretability and work in modularity, adversarial robustness, continual learning, network compression, and studying the human visual system. Finally, we discuss key challenges and argue for future work in interpretability for AI safety that focuses on diagnostics, benchmarking, and robustness.
Machine Learning Model Sizes and the Parameter Gap
Jul 05, 2022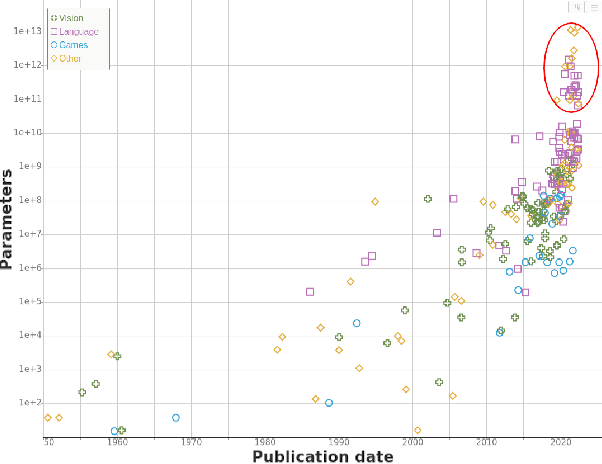
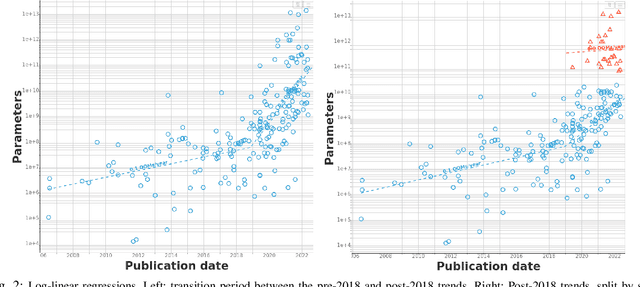
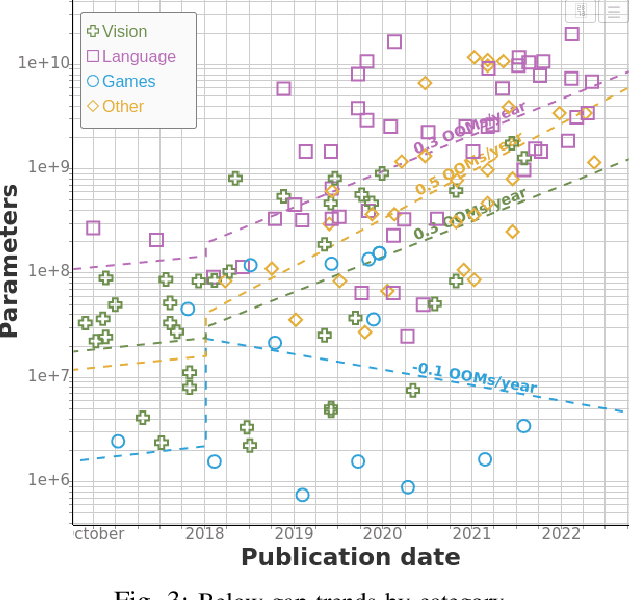
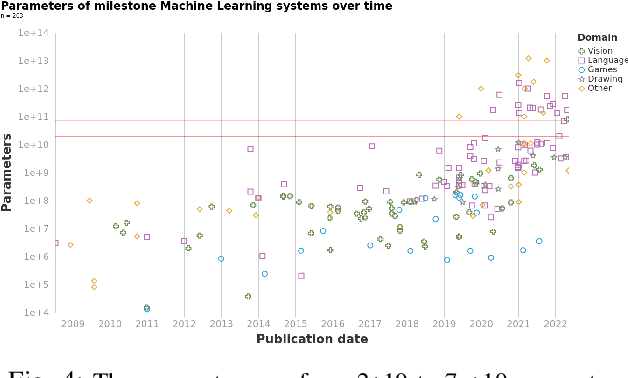
We study trends in model size of notable machine learning systems over time using a curated dataset. From 1950 to 2018, model size in language models increased steadily by seven orders of magnitude. The trend then accelerated, with model size increasing by another five orders of magnitude in just 4 years from 2018 to 2022. Vision models grew at a more constant pace, totaling 7 orders of magnitude of growth between 1950 and 2022. We also identify that, since 2020, there have been many language models below 20B parameters, many models above 70B parameters, but a scarcity of models in the 20-70B parameter range. We refer to that scarcity as the parameter gap. We provide some stylized facts about the parameter gap and propose a few hypotheses to explain it. The explanations we favor are: (a) increasing model size beyond 20B parameters requires adopting different parallelism techniques, which makes mid-sized models less cost-effective, (b) GPT-3 was one order of magnitude larger than previous language models, and researchers afterwards primarily experimented with bigger models to outperform it. While these dynamics likely exist, and we believe they play some role in generating the gap, we don't have high confidence that there are no other, more important dynamics at play.
Compute Trends Across Three Eras of Machine Learning
Mar 09, 2022
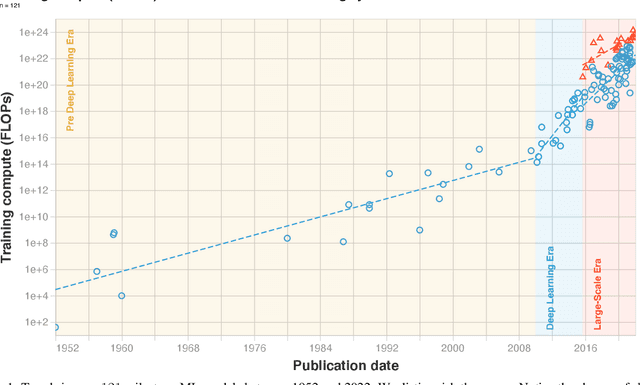
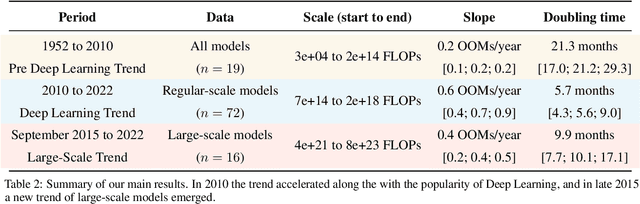
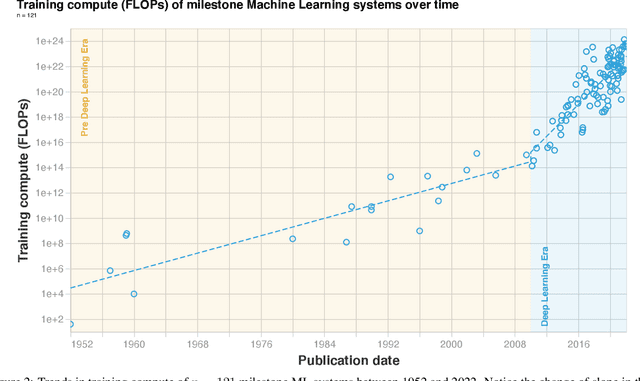
Compute, data, and algorithmic advances are the three fundamental factors that guide the progress of modern Machine Learning (ML). In this paper we study trends in the most readily quantified factor - compute. We show that before 2010 training compute grew in line with Moore's law, doubling roughly every 20 months. Since the advent of Deep Learning in the early 2010s, the scaling of training compute has accelerated, doubling approximately every 6 months. In late 2015, a new trend emerged as firms developed large-scale ML models with 10 to 100-fold larger requirements in training compute. Based on these observations we split the history of compute in ML into three eras: the Pre Deep Learning Era, the Deep Learning Era and the Large-Scale Era. Overall, our work highlights the fast-growing compute requirements for training advanced ML systems.