 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Progress Has There Been in NVIDIA Datacenter GPUs?
Jan 27, 2026Graphics Processing Units (GPUs) are the state-of-the-art architecture for essential tasks, ranging from rendering 2D/3D graphics to accelerating workloads in supercomputing centers and, of course, Artificial Intelligence (AI). As GPUs continue improving to satisfy ever-increasing performance demands, analyzing past and current progress becomes paramount in determining future constraints on scientific research. This is particularly compelling in the AI domain, where rapid technological advancements and fierce global competition have led the United States to recently implement export control regulations limiting international access to advanced AI chips. For this reason, this paper studies technical progress in NVIDIA datacenter GPUs released from the mid-2000s until today. Specifically, we compile a comprehensive dataset of datacenter NVIDIA GPUs comprising several features, ranging from computational performance to release price. Then, we examine trends in main GPU features and estimate progress indicators for per-memory bandwidth, per-dollar, and per-watt increase rates. Our main results identify doubling times of 1.44 and 1.69 years for FP16 and FP32 operations (without accounting for sparsity benefits), while FP64 doubling times range from 2.06 to 3.79 years. Off-chip memory size and bandwidth grew at slower rates than computing performance, doubling every 3.32 to 3.53 years. The release prices of datacenter GPUs have roughly doubled every 5.1 years, while their power consumption has approximately doubled every 16 years. Finally, we quantify the potential implications of current U.S. export control regulations in terms of the potential performance gaps that would result if implementation were assumed to be complete and successful. We find that recently proposed changes to export controls would shrink the potential performance gap from 23.6x to 3.54x.
Mapping AI Risk Mitigations: Evidence Scan and Preliminary AI Risk Mitigation Taxonomy
Dec 12, 2025Organizations and governments that develop, deploy, use, and govern AI must coordinate on effective risk mitigation. However, the landscape of AI risk mitigation frameworks is fragmented, uses inconsistent terminology, and has gaps in coverage. This paper introduces a preliminary AI Risk Mitigation Taxonomy to organize AI risk mitigations and provide a common frame of reference. The Taxonomy was developed through a rapid evidence scan of 13 AI risk mitigation frameworks published between 2023-2025, which were extracted into a living database of 831 AI risk mitigations. The mitigations were iteratively clustered & coded to create the Taxonomy. The preliminary AI Risk Mitigation Taxonomy organizes mitigations into four categories and 23 subcategories: (1) Governance & Oversight: Formal organizational structures and policy frameworks that establish human oversight mechanisms and decision protocols; (2) Technical & Security: Technical, physical, and engineering safeguards that secure AI systems and constrain model behaviors; (3) Operational Process: processes and management frameworks governing AI system deployment, usage, monitoring, incident handling, and validation; and (4) Transparency & Accountability: formal disclosure practices and verification mechanisms that communicate AI system information and enable external scrutiny. The rapid evidence scan and taxonomy construction also revealed several cases where terms like 'risk management' and 'red teaming' are used widely but refer to different responsible actors, actions, and mechanisms of action to reduce risk. This Taxonomy and associated mitigation database, while preliminary, offers a starting point for collation and synthesis of AI risk mitigations. It also offers an accessible, structured way for different actors in the AI ecosystem to discuss and coordinate action to reduce risks from AI.
Meek Models Shall Inherit the Earth
Jul 10, 2025The past decade has seen incredible scaling of AI systems by a few companies, leading to inequality in AI model performance. This paper argues that, contrary to prevailing intuition, the diminishing returns to compute scaling will lead to a convergence of AI model capabilities. In other words, meek models (those with limited computation budget) shall inherit the earth, approaching the performance level of the best models overall. We develop a model illustrating that under a fixed-distribution next-token objective, the marginal capability returns to raw compute shrink substantially. Given current scaling practices, we argue that these diminishing returns are strong enough that even companies that can scale their models exponentially faster than other organizations will eventually have little advantage in capabilities. As part of our argument, we give several reasons that proxies like training loss differences capture important capability measures using evidence from benchmark data and theoretical performance models. In addition, we analyze empirical data on the capability difference of AI models over time. Finally, in light of the increasing ability of meek models, we argue that AI strategy and policy require reexamination, and we outline the areas this shift will affect.
Neural Scaling Laws for Embodied AI
May 22, 2024Scaling laws have driven remarkable progress across machine learning domains like language modeling and computer vision. However, the exploration of scaling laws in embodied AI and robotics has been limited, despite the rapidly increasing usage of machine learning in this field. This paper presents the first study to quantify scaling laws for Robot Foundation Models (RFMs) and the use of LLMs in robotics tasks. Through a meta-analysis spanning 198 research papers, we analyze how key factors like compute, model size, and training data quantity impact model performance across various robotic tasks. Our findings confirm that scaling laws apply to both RFMs and LLMs in robotics, with performance consistently improving as resources increase. The power law coefficients for RFMs closely match those of LLMs in robotics, resembling those found in computer vision and outperforming those for LLMs in the language domain. We also note that these coefficients vary with task complexity, with familiar tasks scaling more efficiently than unfamiliar ones, emphasizing the need for large and diverse datasets. Furthermore, we highlight the absence of standardized benchmarks in embodied AI. Most studies indicate diminishing returns, suggesting that significant resources are necessary to achieve high performance, posing challenges due to data and computational limitations. Finally, as models scale, we observe the emergence of new capabilities, particularly related to data and model size.
Algorithmic progress in language models
Mar 09, 2024
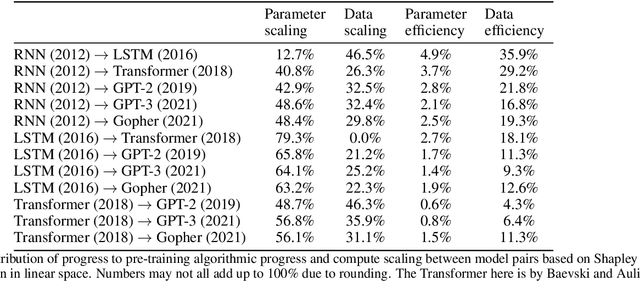

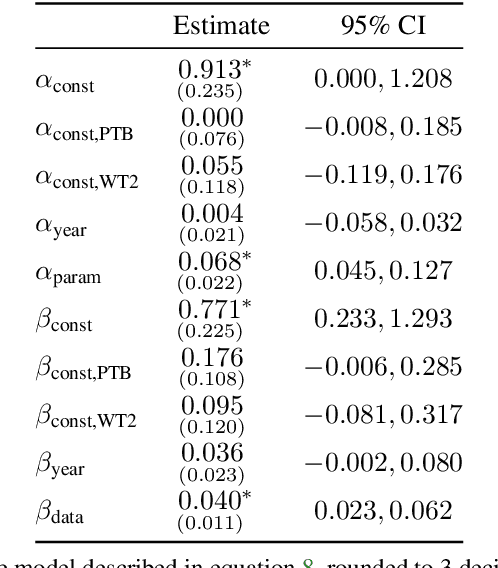
We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law. We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in compute made an even larger contribution to overall performance improvements over this time period. Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from compute and algorithms.
The Compute Divide in Machine Learning: A Threat to Academic Contribution and Scrutiny?
Jan 08, 2024There are pronounced differences in the extent to which industrial and academic AI labs use computing resources. We provide a data-driven survey of the role of the compute divide in shaping machine learning research. We show that a compute divide has coincided with a reduced representation of academic-only research teams in compute intensive research topics, especially foundation models. We argue that, academia will likely play a smaller role in advancing the associated techniques, providing critical evaluation and scrutiny, and in the diffusion of such models. Concurrent with this change in research focus, there is a noticeable shift in academic research towards embracing open source, pre-trained models developed within the industry. To address the challenges arising from this trend, especially reduced scrutiny of influential models, we recommend approaches aimed at thoughtfully expanding academic insights. Nationally-sponsored computing infrastructure coupled with open science initiatives could judiciously boost academic compute access, prioritizing research on interpretability, safety and security. Structured access programs and third-party auditing may also allow measured external evaluation of industry systems.
Large Language Model Routing with Benchmark Datasets
Sep 27, 2023
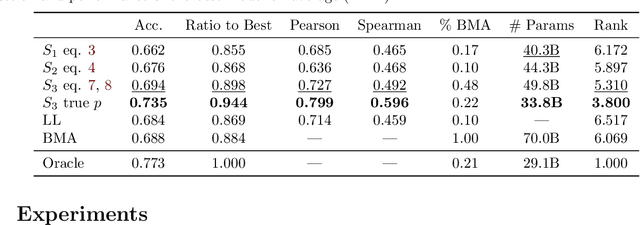
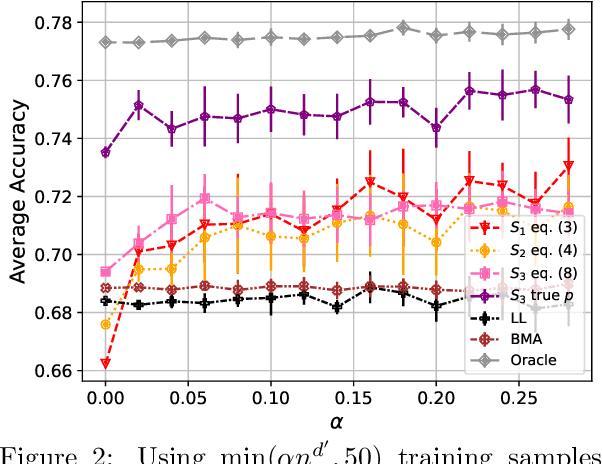
There is a rapidly growing number of open-source Large Language Models (LLMs) and benchmark datasets to compare them. While some models dominate these benchmarks, no single model typically achieves the best accuracy in all tasks and use cases. In this work, we address the challenge of selecting the best LLM out of a collection of models for new tasks. We propose a new formulation for the problem, in which benchmark datasets are repurposed to learn a "router" model for this LLM selection, and we show that this problem can be reduced to a collection of binary classification tasks. We demonstrate the utility and limitations of learning model routers from various benchmark datasets, where we consistently improve performance upon using any single model for all tasks.
The Grand Illusion: The Myth of Software Portability and Implications for ML Progress
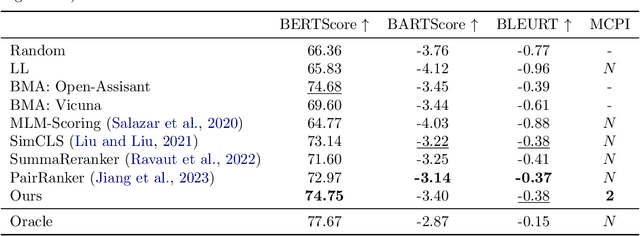
Sep 12, 2023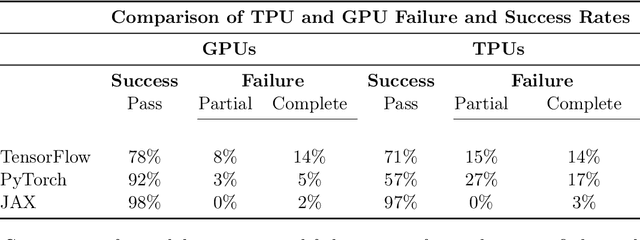
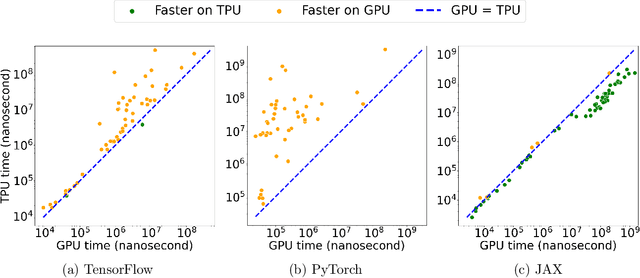
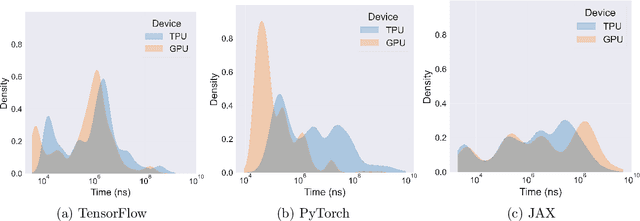
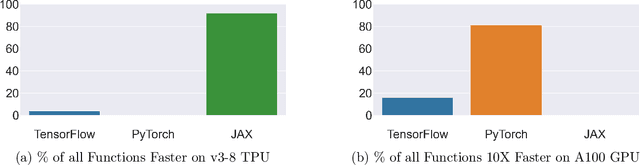
Pushing the boundaries of machine learning often requires exploring different hardware and software combinations. However, the freedom to experiment across different tooling stacks can be at odds with the drive for efficiency, which has produced increasingly specialized AI hardware and incentivized consolidation around a narrow set of ML frameworks. Exploratory research can be restricted if software and hardware are co-evolving, making it even harder to stray away from mainstream ideas that work well with popular tooling stacks. While this friction increasingly impacts the rate of innovation in machine learning, to our knowledge the lack of portability in tooling has not been quantified. In this work, we ask: How portable are popular ML software frameworks? We conduct a large-scale study of the portability of mainstream ML frameworks across different hardware types. Our findings paint an uncomfortable picture -- frameworks can lose more than 40% of their key functions when ported to other hardware. Worse, even when functions are portable, the slowdown in their performance can be extreme and render performance untenable. Collectively, our results reveal how costly straying from a narrow set of hardware-software combinations can be - and suggest that specialization of hardware impedes innovation in machine learning research.