 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Granite Embedding Models
Feb 27, 2025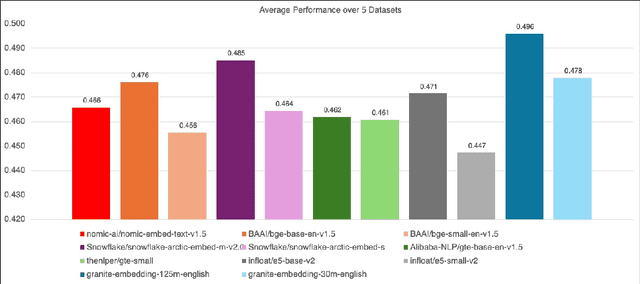



We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
Enterprise Benchmarks for Large Language Model Evaluation
Oct 11, 2024



The advancement of large language models (LLMs) has led to a greater challenge of having a rigorous and systematic evaluation of complex tasks performed, especially in enterprise applications. Therefore, LLMs need to be able to benchmark enterprise datasets for various tasks. This work presents a systematic exploration of benchmarking strategies tailored to LLM evaluation, focusing on the utilization of domain-specific datasets and consisting of a variety of NLP tasks. The proposed evaluation framework encompasses 25 publicly available datasets from diverse enterprise domains like financial services, legal, cyber security, and climate and sustainability. The diverse performance of 13 models across different enterprise tasks highlights the importance of selecting the right model based on the specific requirements of each task. Code and prompts are available on GitHub.
Large Language Model Routing with Benchmark Datasets
Sep 27, 2023
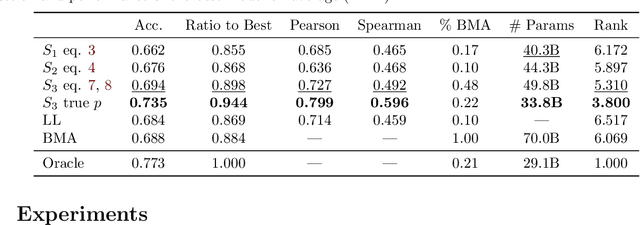
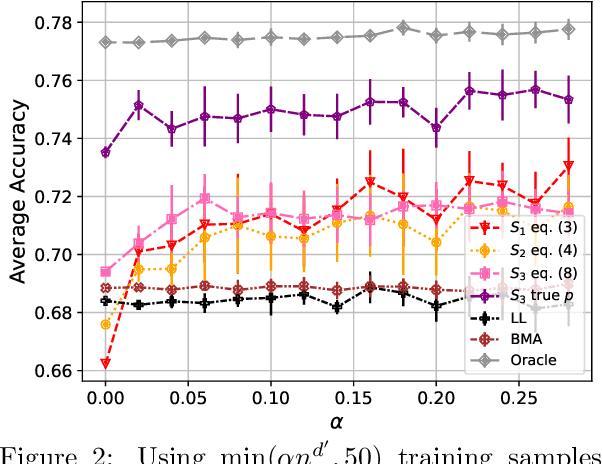
There is a rapidly growing number of open-source Large Language Models (LLMs) and benchmark datasets to compare them. While some models dominate these benchmarks, no single model typically achieves the best accuracy in all tasks and use cases. In this work, we address the challenge of selecting the best LLM out of a collection of models for new tasks. We propose a new formulation for the problem, in which benchmark datasets are repurposed to learn a "router" model for this LLM selection, and we show that this problem can be reduced to a collection of binary classification tasks. We demonstrate the utility and limitations of learning model routers from various benchmark datasets, where we consistently improve performance upon using any single model for all tasks.