 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Speculative Decoding for LLM-based ASR with CTC Encoder Drafts
Mar 11, 2026We propose self-speculative decoding for speech-aware LLMs by using the CTC encoder as a draft model to accelerate auto-regressive (AR) inference and improve ASR accuracy. Our three-step procedure works as follows: (1) if the frame entropies of the CTC output distributions are below a threshold, the greedy CTC hypothesis is accepted as final; (2) otherwise, the CTC hypothesis is verified in a single LLM forward pass using a relaxed acceptance criterion based on token likelihoods; (3) if verification fails, AR decoding resumes from the accepted CTC prefix. Experiments on nine corpora and five languages show that this approach can simultaneously accelerate decoding and reduce WER. On the HuggingFace Open ASR benchmark with a 1B parameter LLM and 440M parameter CTC encoder, we achieve a record 5.58% WER and improve the inverse real time factor by a factor of 4.4 with only a 12% relative WER increase over AR search. Code and model weights are publicly available under a permissive license.
NLE: Non-autoregressive LLM-based ASR by Transcript Editing
Mar 09, 2026While autoregressive (AR) LLM-based ASR systems achieve strong accuracy, their sequential decoding limits parallelism and incurs high latency. We propose NLE, a non-autoregressive (NAR) approach that formulates speech recognition as conditional transcript editing, enabling fully parallel prediction. NLE extracts acoustic embeddings and an initial hypothesis from a pretrained speech encoder, then refines the hypothesis using a bidirectional LLM editor trained with a latent alignment objective. An interleaved padding strategy exploits the identity mapping bias of Transformers, allowing the model to focus on corrections rather than full reconstruction. On the Open ASR leaderboard, NLE++ achieves 5.67% average WER with an RTFx (inverse real-time factor) of 1630. In single-utterance scenarios, NLE achieves 27x speedup over the AR baseline, making it suitable for real-time applications.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
A Non-autoregressive Model for Joint STT and TTS
Jan 15, 2025In this paper, we take a step towards jointly modeling automatic speech recognition (STT) and speech synthesis (TTS) in a fully non-autoregressive way. We develop a novel multimodal framework capable of handling the speech and text modalities as input either individually or together. The proposed model can also be trained with unpaired speech or text data owing to its multimodal nature. We further propose an iterative refinement strategy to improve the STT and TTS performance of our model such that the partial hypothesis at the output can be fed back to the input of our model, thus iteratively improving both STT and TTS predictions. We show that our joint model can effectively perform both STT and TTS tasks, outperforming the STT-specific baseline in all tasks and performing competitively with the TTS-specific baseline across a wide range of evaluation metrics.
Bilevel Joint Unsupervised and Supervised Training for Automatic Speech Recognition
Dec 11, 2024In this paper, we propose a bilevel joint unsupervised and supervised training (BL-JUST) framework for automatic speech recognition. Compared to the conventional pre-training and fine-tuning strategy which is a disconnected two-stage process, BL-JUST tries to optimize an acoustic model such that it simultaneously minimizes both the unsupervised and supervised loss functions. Because BL-JUST seeks matched local optima of both loss functions, acoustic representations learned by the acoustic model strike a good balance between being generic and task-specific. We solve the BL-JUST problem using penalty-based bilevel gradient descent and evaluate the trained deep neural network acoustic models on various datasets with a variety of architectures and loss functions. We show that BL-JUST can outperform the widely-used pre-training and fine-tuning strategy and some other popular semi-supervised techniques.
Exploring the limits of decoder-only models trained on public speech recognition corpora
Jan 31, 2024



The emergence of industrial-scale speech recognition (ASR) models such as Whisper and USM, trained on 1M hours of weakly labelled and 12M hours of audio only proprietary data respectively, has led to a stronger need for large scale public ASR corpora and competitive open source pipelines. Unlike the said models, large language models are typically based on Transformer decoders, and it remains unclear if decoder-only models trained on public data alone can deliver competitive performance. In this work, we investigate factors such as choice of training datasets and modeling components necessary for obtaining the best performance using public English ASR corpora alone. Our Decoder-Only Transformer for ASR (DOTA) model comprehensively outperforms the encoder-decoder open source replication of Whisper (OWSM) on nearly all English ASR benchmarks and outperforms Whisper large-v3 on 7 out of 15 test sets. We release our codebase and model checkpoints under permissive license.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 24, 2023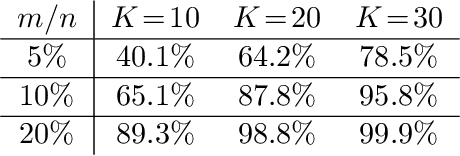
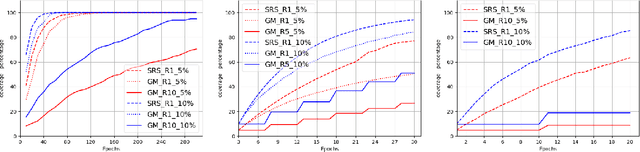
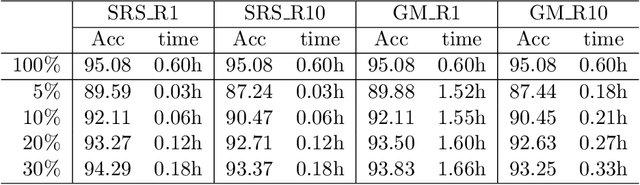
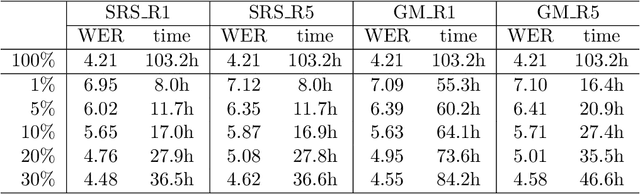
Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Semi-Autoregressive Streaming ASR With Label Context
Sep 19, 2023Non-autoregressive (NAR) modeling has gained significant interest in speech processing since these models achieve dramatically lower inference time than autoregressive (AR) models while also achieving good transcription accuracy. Since NAR automatic speech recognition (ASR) models must wait for the completion of the entire utterance before processing, some works explore streaming NAR models based on blockwise attention for low-latency applications. However, streaming NAR models significantly lag in accuracy compared to streaming AR and non-streaming NAR models. To address this, we propose a streaming "semi-autoregressive" ASR model that incorporates the labels emitted in previous blocks as additional context using a Language Model (LM) subnetwork. We also introduce a novel greedy decoding algorithm that addresses insertion and deletion errors near block boundaries while not significantly increasing the inference time. Experiments show that our method outperforms the existing streaming NAR model by 19% relative on Tedlium2, 16%/8% on Librispeech-100 clean/other test sets, and 19%/8% on the Switchboard(SWB) / Callhome(CH) test sets. It also reduced the accuracy gap with streaming AR and non-streaming NAR models while achieving 2.5x lower latency. We also demonstrate that our approach can effectively utilize external text data to pre-train the LM subnetwork to further improve streaming ASR accuracy.
Multiple Representation Transfer from Large Language Models to End-to-End ASR Systems
Sep 07, 2023



Transferring the knowledge of large language models (LLMs) is a promising technique to incorporate linguistic knowledge into end-to-end automatic speech recognition (ASR) systems. However, existing works only transfer a single representation of LLM (e.g. the last layer of pretrained BERT), while the representation of a text is inherently non-unique and can be obtained variously from different layers, contexts and models. In this work, we explore a wide range of techniques to obtain and transfer multiple representations of LLMs into a transducer-based ASR system. While being conceptually simple, we show that transferring multiple representations of LLMs can be an effective alternative to transferring only a single representation.
Diagonal State Space Augmented Transformers for Speech Recognition
Feb 27, 2023We improve on the popular conformer architecture by replacing the depthwise temporal convolutions with diagonal state space (DSS) models. DSS is a recently introduced variant of linear RNNs obtained by discretizing a linear dynamical system with a diagonal state transition matrix. DSS layers project the input sequence onto a space of orthogonal polynomials where the choice of basis functions, metric and support is controlled by the eigenvalues of the transition matrix. We compare neural transducers with either conformer or our proposed DSS-augmented transformer (DSSformer) encoders on three public corpora: Switchboard English conversational telephone speech 300 hours, Switchboard+Fisher 2000 hours, and a spoken archive of holocaust survivor testimonials called MALACH 176 hours. On Switchboard 300/2000 hours, we reach a single model performance of 8.9%/6.7% WER on the combined test set of the Hub5 2000 evaluation, respectively, and on MALACH we improve the WER by 7% relative over the previous best published result. In addition, we present empirical evidence suggesting that DSS layers learn damped Fourier basis functions where the attenuation coefficients are layer specific whereas the frequency coefficients converge to almost identical linearly-spaced values across all layers.