 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan VLMs Truly Forget? Benchmarking Training-Free Visual Concept Unlearning
Apr 03, 2026VLMs trained on web-scale data retain sensitive and copyrighted visual concepts that deployment may require removing. Training-based unlearning methods share a structural flaw: fine-tuning on a narrow forget set degrades general capabilities before unlearning begins, making it impossible to attribute subsequent performance drops to the unlearning procedure itself. Training-free approaches sidestep this by suppressing concepts through prompts or system instructions, but no rigorous benchmark exists for evaluating them on visual tasks. We introduce VLM-UnBench, the first benchmark for training-free visual concept unlearning in VLMs. It covers four forgetting levels, 7 source datasets, and 11 concept axes, and pairs a three-level probe taxonomy with five evaluation conditions to separate genuine forgetting from instruction compliance. Across 8 evaluation settings and 13 VLM configurations, realistic unlearning prompts leave forget accuracy near the no-instruction baseline; meaningful reductions appear only under oracle conditions that disclose the target concept to the model. Object and scene concepts are the most resistant to suppression, and stronger instruction-tuned models remain capable despite explicit forget instructions. These results expose a clear gap between prompt-level suppression and true visual concept erasure.
BiRQ: Bi-Level Self-Labeling Random Quantization for Self-Supervised Speech Recognition
Sep 18, 2025Speech is a rich signal, and labeled audio-text pairs are costly, making self-supervised learning essential for scalable representation learning. A core challenge in speech SSL is generating pseudo-labels that are both informative and efficient: strong labels, such as those used in HuBERT, improve downstream performance but rely on external encoders and multi-stage pipelines, while efficient methods like BEST-RQ achieve simplicity at the cost of weaker labels. We propose BiRQ, a bilevel SSL framework that combines the efficiency of BEST-RQ with the refinement benefits of HuBERT-style label enhancement. The key idea is to reuse part of the model itself as a pseudo-label generator: intermediate representations are discretized by a random-projection quantizer to produce enhanced labels, while anchoring labels derived directly from the raw input stabilize training and prevent collapse. Training is formulated as an efficient first-order bilevel optimization problem, solved end-to-end with differentiable Gumbel-softmax selection. This design eliminates the need for external label encoders, reduces memory cost, and enables iterative label refinement in an end-to-end fashion. BiRQ consistently improves over BEST-RQ while maintaining low complexity and computational efficiency. We validate our method on various datasets, including 960-hour LibriSpeech, 150-hour AMI meetings and 5,000-hour YODAS, demonstrating consistent gains over BEST-RQ.
Bilevel Joint Unsupervised and Supervised Training for Automatic Speech Recognition
Dec 11, 2024In this paper, we propose a bilevel joint unsupervised and supervised training (BL-JUST) framework for automatic speech recognition. Compared to the conventional pre-training and fine-tuning strategy which is a disconnected two-stage process, BL-JUST tries to optimize an acoustic model such that it simultaneously minimizes both the unsupervised and supervised loss functions. Because BL-JUST seeks matched local optima of both loss functions, acoustic representations learned by the acoustic model strike a good balance between being generic and task-specific. We solve the BL-JUST problem using penalty-based bilevel gradient descent and evaluate the trained deep neural network acoustic models on various datasets with a variety of architectures and loss functions. We show that BL-JUST can outperform the widely-used pre-training and fine-tuning strategy and some other popular semi-supervised techniques.
FERERO: A Flexible Framework for Preference-Guided Multi-Objective Learning
Dec 02, 2024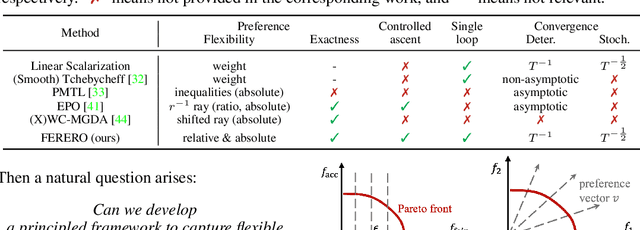
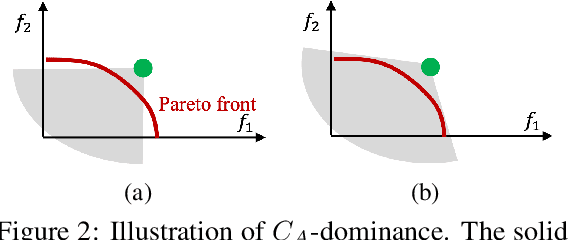
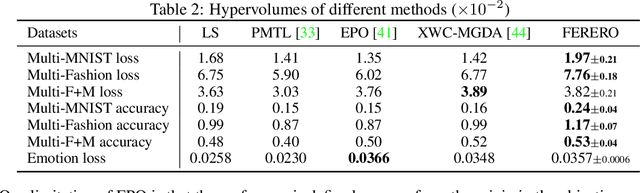

Finding specific preference-guided Pareto solutions that represent different trade-offs among multiple objectives is critical yet challenging in multi-objective problems. Existing methods are restrictive in preference definitions and/or their theoretical guarantees. In this work, we introduce a Flexible framEwork for pREfeRence-guided multi-Objective learning (FERERO) by casting it as a constrained vector optimization problem. Specifically, two types of preferences are incorporated into this formulation -- the relative preference defined by the partial ordering induced by a polyhedral cone, and the absolute preference defined by constraints that are linear functions of the objectives. To solve this problem, convergent algorithms are developed with both single-loop and stochastic variants. Notably, this is the first single-loop primal algorithm for constrained vector optimization to our knowledge. The proposed algorithms adaptively adjust to both constraint and objective values, eliminating the need to solve different subproblems at different stages of constraint satisfaction. Experiments on multiple benchmarks demonstrate the proposed method is very competitive in finding preference-guided optimal solutions. Code is available at https://github.com/lisha-chen/FERERO/.
Three-Way Trade-Off in Multi-Objective Learning: Optimization, Generalization and Conflict-Avoidance
May 31, 2023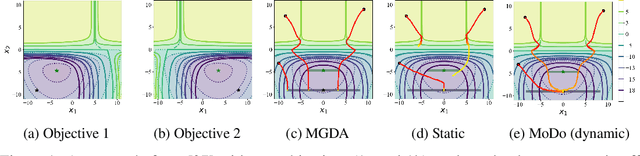
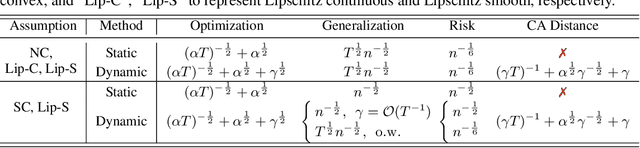
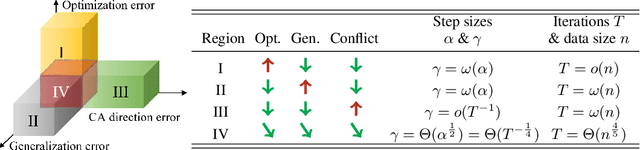

Multi-objective learning (MOL) problems often arise in emerging machine learning problems when there are multiple learning criteria or multiple learning tasks. Recent works have developed various dynamic weighting algorithms for MOL such as MGDA and its variants, where the central idea is to find an update direction that avoids conflicts among objectives. Albeit its appealing intuition, empirical studies show that dynamic weighting methods may not always outperform static ones. To understand this theory-practical gap, we focus on a new stochastic variant of MGDA - the Multi-objective gradient with Double sampling (MoDo) algorithm, and study the generalization performance of the dynamic weighting-based MoDo and its interplay with optimization through the lens of algorithm stability. Perhaps surprisingly, we find that the key rationale behind MGDA -- updating along conflict-avoidant direction - may hinder dynamic weighting algorithms from achieving the optimal ${\cal O}(1/\sqrt{n})$ population risk, where $n$ is the number of training samples. We further demonstrate the variability of dynamic weights on the three-way trade-off among optimization, generalization, and conflict avoidance that is unique in MOL.
Learning with Limited Samples -- Meta-Learning and Applications to Communication Systems
Oct 03, 2022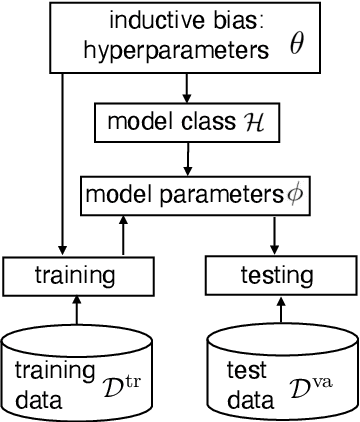
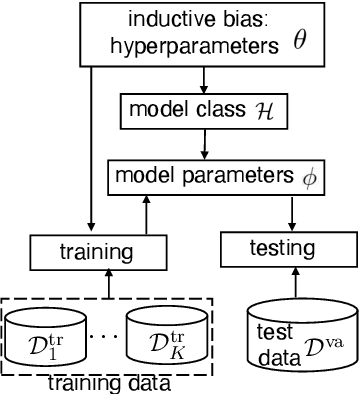
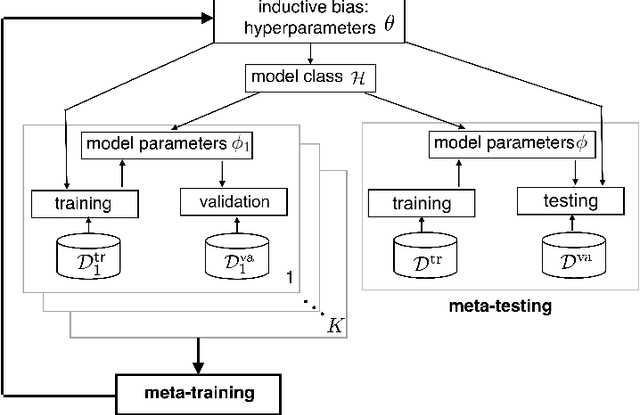
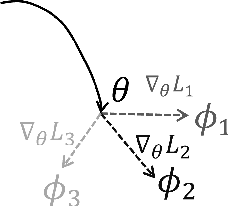
Deep learning has achieved remarkable success in many machine learning tasks such as image classification, speech recognition, and game playing. However, these breakthroughs are often difficult to translate into real-world engineering systems because deep learning models require a massive number of training samples, which are costly to obtain in practice. To address labeled data scarcity, few-shot meta-learning optimizes learning algorithms that can efficiently adapt to new tasks quickly. While meta-learning is gaining significant interest in the machine learning literature, its working principles and theoretic fundamentals are not as well understood in the engineering community. This review monograph provides an introduction to meta-learning by covering principles, algorithms, theory, and engineering applications. After introducing meta-learning in comparison with conventional and joint learning, we describe the main meta-learning algorithms, as well as a general bilevel optimization framework for the definition of meta-learning techniques. Then, we summarize known results on the generalization capabilities of meta-learning from a statistical learning viewpoint. Applications to communication systems, including decoding and power allocation, are discussed next, followed by an introduction to aspects related to the integration of meta-learning with emerging computing technologies, namely neuromorphic and quantum computing. The monograph is concluded with an overview of open research challenges.
Understanding Benign Overfitting in Nested Meta Learning
Jun 27, 2022



Meta learning has demonstrated tremendous success in few-shot learning with limited supervised data. In those settings, the meta model is usually overparameterized. While the conventional statistical learning theory suggests that overparameterized models tend to overfit, empirical evidence reveals that overparameterized meta learning methods still work well -- a phenomenon often called ``benign overfitting.'' To understand this phenomenon, we focus on the meta learning settings with a challenging nested structure that we term the nested meta learning, and analyze its generalization performance under an overparameterized meta learning model. While our analysis uses the relatively tractable linear models, our theory contributes to understanding the delicate interplay among data heterogeneity, model adaptation and benign overfitting in nested meta learning tasks. We corroborate our theoretical claims through numerical simulations.
Sharp-MAML: Sharpness-Aware Model-Agnostic Meta Learning
Jun 10, 2022



Model-agnostic meta learning (MAML) is currently one of the dominating approaches for few-shot meta-learning. Albeit its effectiveness, the optimization of MAML can be challenging due to the innate bilevel problem structure. Specifically, the loss landscape of MAML is much more complex with possibly more saddle points and local minimizers than its empirical risk minimization counterpart. To address this challenge, we leverage the recently invented sharpness-aware minimization and develop a sharpness-aware MAML approach that we term Sharp-MAML. We empirically demonstrate that Sharp-MAML and its computation-efficient variant can outperform popular existing MAML baselines (e.g., $+12\%$ accuracy on Mini-Imagenet). We complement the empirical study with the convergence rate analysis and the generalization bound of Sharp-MAML. To the best of our knowledge, this is the first empirical and theoretical study on sharpness-aware minimization in the context of bilevel learning. The code is available at https://github.com/mominabbass/Sharp-MAML.
Is Bayesian Model-Agnostic Meta Learning Better than Model-Agnostic Meta Learning, Provably?
Mar 06, 2022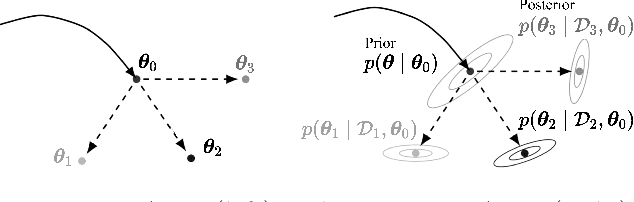



Meta learning aims at learning a model that can quickly adapt to unseen tasks. Widely used meta learning methods include model agnostic meta learning (MAML), implicit MAML, Bayesian MAML. Thanks to its ability of modeling uncertainty, Bayesian MAML often has advantageous empirical performance. However, the theoretical understanding of Bayesian MAML is still limited, especially on questions such as if and when Bayesian MAML has provably better performance than MAML. In this paper, we aim to provide theoretical justifications for Bayesian MAML's advantageous performance by comparing the meta test risks of MAML and Bayesian MAML. In the meta linear regression, under both the distribution agnostic and linear centroid cases, we have established that Bayesian MAML indeed has provably lower meta test risks than MAML. We verify our theoretical results through experiments.
Deep Structured Prediction for Facial Landmark Detection
Oct 18, 2020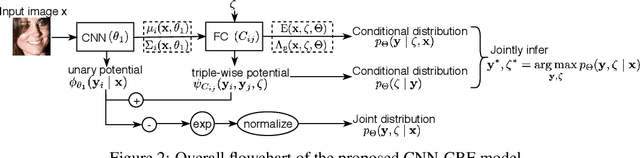


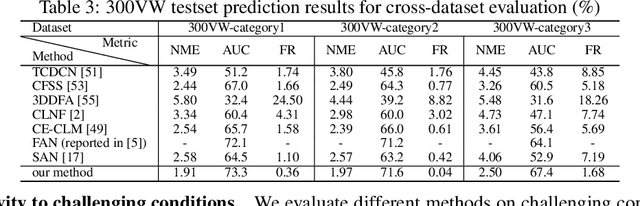
Existing deep learning based facial landmark detection methods have achieved excellent performance. These methods, however, do not explicitly embed the structural dependencies among landmark points. They hence cannot preserve the geometric relationships between landmark points or generalize well to challenging conditions or unseen data. This paper proposes a method for deep structured facial landmark detection based on combining a deep Convolutional Network with a Conditional Random Field. We demonstrate its superior performance to existing state-of-the-art techniques in facial landmark detection, especially a better generalization ability on challenging datasets that include large pose and occlusion.