 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Weakly-Supervised 3D Hand Reconstruction with Knowledge Prior and Uncertainty Guidance
Jul 17, 2024Fully-supervised monocular 3D hand reconstruction is often difficult because capturing the requisite 3D data entails deploying specialized equipment in a controlled environment. We introduce a weakly-supervised method that avoids such requirements by leveraging fundamental principles well-established in the understanding of the human hand's unique structure and functionality. Specifically, we systematically study hand knowledge from different sources, including biomechanics, functional anatomy, and physics. We effectively incorporate these valuable foundational insights into 3D hand reconstruction models through an appropriate set of differentiable training losses. This enables training solely with readily-obtainable 2D hand landmark annotations and eliminates the need for expensive 3D supervision. Moreover, we explicitly model the uncertainty that is inherent in image observations. We enhance the training process by exploiting a simple yet effective Negative Log Likelihood (NLL) loss that incorporates uncertainty into the loss function. Through extensive experiments, we demonstrate that our method significantly outperforms state-of-the-art weakly-supervised methods. For example, our method achieves nearly a 21\% performance improvement on the widely adopted FreiHAND dataset.
Epistemic Uncertainty Quantification For Pre-trained Neural Network
Apr 15, 2024Epistemic uncertainty quantification (UQ) identifies where models lack knowledge. Traditional UQ methods, often based on Bayesian neural networks, are not suitable for pre-trained non-Bayesian models. Our study addresses quantifying epistemic uncertainty for any pre-trained model, which does not need the original training data or model modifications and can ensure broad applicability regardless of network architectures or training techniques. Specifically, we propose a gradient-based approach to assess epistemic uncertainty, analyzing the gradients of outputs relative to model parameters, and thereby indicating necessary model adjustments to accurately represent the inputs. We first explore theoretical guarantees of gradient-based methods for epistemic UQ, questioning the view that this uncertainty is only calculable through differences between multiple models. We further improve gradient-driven UQ by using class-specific weights for integrating gradients and emphasizing distinct contributions from neural network layers. Additionally, we enhance UQ accuracy by combining gradient and perturbation methods to refine the gradients. We evaluate our approach on out-of-distribution detection, uncertainty calibration, and active learning, demonstrating its superiority over current state-of-the-art UQ methods for pre-trained models.
PhysPT: Physics-aware Pretrained Transformer for Estimating Human Dynamics from Monocular Videos
Apr 05, 2024While current methods have shown promising progress on estimating 3D human motion from monocular videos, their motion estimates are often physically unrealistic because they mainly consider kinematics. In this paper, we introduce Physics-aware Pretrained Transformer (PhysPT), which improves kinematics-based motion estimates and infers motion forces. PhysPT exploits a Transformer encoder-decoder backbone to effectively learn human dynamics in a self-supervised manner. Moreover, it incorporates physics principles governing human motion. Specifically, we build a physics-based body representation and contact force model. We leverage them to impose novel physics-inspired training losses (i.e., force loss, contact loss, and Euler-Lagrange loss), enabling PhysPT to capture physical properties of the human body and the forces it experiences. Experiments demonstrate that, once trained, PhysPT can be directly applied to kinematics-based estimates to significantly enhance their physical plausibility and generate favourable motion forces. Furthermore, we show that these physically meaningful quantities translate into improved accuracy of an important downstream task: human action recognition.
Causal Discovery under Identifiable Heteroscedastic Noise Model
Dec 20, 2023Capturing the underlying structural causal relations represented by Directed Acyclic Graphs (DAGs) has been a fundamental task in various AI disciplines. Causal DAG learning via the continuous optimization framework has recently achieved promising performance in terms of both accuracy and efficiency. However, most methods make strong assumptions of homoscedastic noise, i.e., exogenous noises have equal variances across variables, observations, or even both. The noises in real data usually violate both assumptions due to the biases introduced by different data collection processes. To address the issue of heteroscedastic noise, we introduce relaxed and implementable sufficient conditions, proving the identifiability of a general class of SEM subject to these conditions. Based on the identifiable general SEM, we propose a novel formulation for DAG learning that accounts for the variation in noise variance across variables and observations. We then propose an effective two-phase iterative DAG learning algorithm to address the increasing optimization difficulties and to learn a causal DAG from data with heteroscedastic variable noise under varying variance. We show significant empirical gains of the proposed approaches over state-of-the-art methods on both synthetic data and real data.
Body Knowledge and Uncertainty Modeling for Monocular 3D Human Body Reconstruction
Aug 01, 2023While 3D body reconstruction methods have made remarkable progress recently, it remains difficult to acquire the sufficiently accurate and numerous 3D supervisions required for training. In this paper, we propose \textbf{KNOWN}, a framework that effectively utilizes body \textbf{KNOW}ledge and u\textbf{N}certainty modeling to compensate for insufficient 3D supervisions. KNOWN exploits a comprehensive set of generic body constraints derived from well-established body knowledge. These generic constraints precisely and explicitly characterize the reconstruction plausibility and enable 3D reconstruction models to be trained without any 3D data. Moreover, existing methods typically use images from multiple datasets during training, which can result in data noise (\textit{e.g.}, inconsistent joint annotation) and data imbalance (\textit{e.g.}, minority images representing unusual poses or captured from challenging camera views). KNOWN solves these problems through a novel probabilistic framework that models both aleatoric and epistemic uncertainty. Aleatoric uncertainty is encoded in a robust Negative Log-Likelihood (NLL) training loss, while epistemic uncertainty is used to guide model refinement. Experiments demonstrate that KNOWN's body reconstruction outperforms prior weakly-supervised approaches, particularly on the challenging minority images.
Gradient-based Uncertainty Attribution for Explainable Bayesian Deep Learning
Apr 10, 2023Predictions made by deep learning models are prone to data perturbations, adversarial attacks, and out-of-distribution inputs. To build a trusted AI system, it is therefore critical to accurately quantify the prediction uncertainties. While current efforts focus on improving uncertainty quantification accuracy and efficiency, there is a need to identify uncertainty sources and take actions to mitigate their effects on predictions. Therefore, we propose to develop explainable and actionable Bayesian deep learning methods to not only perform accurate uncertainty quantification but also explain the uncertainties, identify their sources, and propose strategies to mitigate the uncertainty impacts. Specifically, we introduce a gradient-based uncertainty attribution method to identify the most problematic regions of the input that contribute to the prediction uncertainty. Compared to existing methods, the proposed UA-Backprop has competitive accuracy, relaxed assumptions, and high efficiency. Moreover, we propose an uncertainty mitigation strategy that leverages the attribution results as attention to further improve the model performance. Both qualitative and quantitative evaluations are conducted to demonstrate the effectiveness of our proposed methods.
Knowledge-augmented Deep Learning and Its Applications: A Survey
Nov 30, 2022Deep learning models, though having achieved great success in many different fields over the past years, are usually data hungry, fail to perform well on unseen samples, and lack of interpretability. Various prior knowledge often exists in the target domain and their use can alleviate the deficiencies with deep learning. To better mimic the behavior of human brains, different advanced methods have been proposed to identify domain knowledge and integrate it into deep models for data-efficient, generalizable, and interpretable deep learning, which we refer to as knowledge-augmented deep learning (KADL). In this survey, we define the concept of KADL, and introduce its three major tasks, i.e., knowledge identification, knowledge representation, and knowledge integration. Different from existing surveys that are focused on a specific type of knowledge, we provide a broad and complete taxonomy of domain knowledge and its representations. Based on our taxonomy, we provide a systematic review of existing techniques, different from existing works that survey integration approaches agnostic to taxonomy of knowledge. This survey subsumes existing works and offers a bird's-eye view of research in the general area of knowledge-augmented deep learning. The thorough and critical reviews of numerous papers help not only understand current progresses but also identify future directions for the research on knowledge-augmented deep learning.
Probabilistic Debiasing of Scene Graphs
Nov 11, 2022The quality of scene graphs generated by the state-of-the-art (SOTA) models is compromised due to the long-tail nature of the relationships and their parent object pairs. Training of the scene graphs is dominated by the majority relationships of the majority pairs and, therefore, the object-conditional distributions of relationship in the minority pairs are not preserved after the training is converged. Consequently, the biased model performs well on more frequent relationships in the marginal distribution of relationships such as `on' and `wearing', and performs poorly on the less frequent relationships such as `eating' or `hanging from'. In this work, we propose virtual evidence incorporated within-triplet Bayesian Network (BN) to preserve the object-conditional distribution of the relationship label and to eradicate the bias created by the marginal probability of the relationships. The insufficient number of relationships in the minority classes poses a significant problem in learning the within-triplet Bayesian network. We address this insufficiency by embedding-based augmentation of triplets where we borrow samples of the minority triplet classes from its neighborhood triplets in the semantic space. We perform experiments on two different datasets and achieve a significant improvement in the mean recall of the relationships. We also achieve better balance between recall and mean recall performance compared to the SOTA de-biasing techniques of scene graph models.
Empirical Bayesian Approaches for Robust Constraint-based Causal Discovery under Insufficient Data
Jun 16, 2022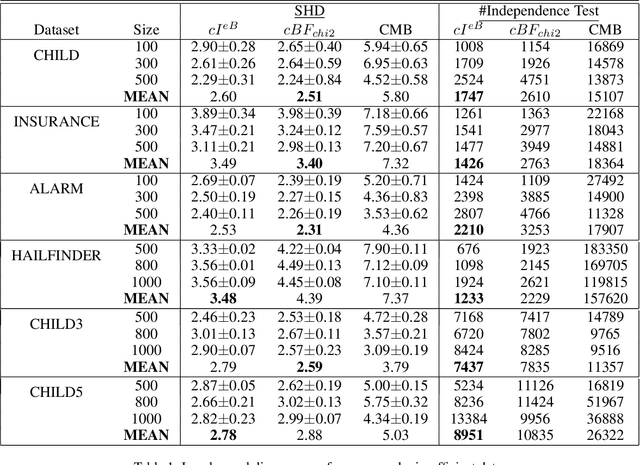
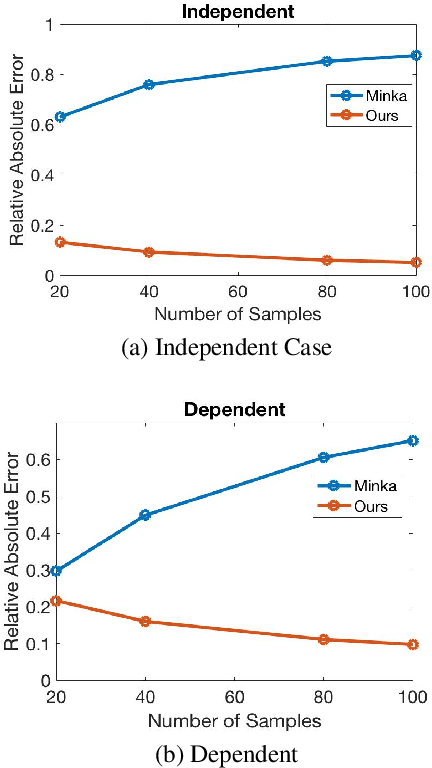
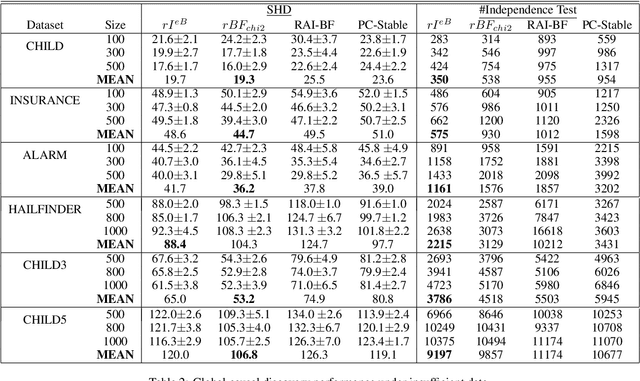
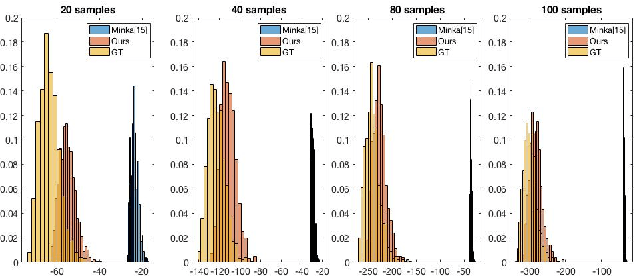
Causal discovery is to learn cause-effect relationships among variables given observational data and is important for many applications. Existing causal discovery methods assume data sufficiency, which may not be the case in many real world datasets. As a result, many existing causal discovery methods can fail under limited data. In this work, we propose Bayesian-augmented frequentist independence tests to improve the performance of constraint-based causal discovery methods under insufficient data: 1) We firstly introduce a Bayesian method to estimate mutual information (MI), based on which we propose a robust MI based independence test; 2) Secondly, we consider the Bayesian estimation of hypothesis likelihood and incorporate it into a well-defined statistical test, resulting in a robust statistical testing based independence test. We apply proposed independence tests to constraint-based causal discovery methods and evaluate the performance on benchmark datasets with insufficient samples. Experiments show significant performance improvement in terms of both accuracy and efficiency over SOTA methods.