 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Data-Prep-Kit: getting your data ready for LLM application development
Sep 26, 2024



Data preparation is the first and a very important step towards any Large Language Model (LLM) development. This paper introduces an easy-to-use, extensible, and scale-flexible open-source data preparation toolkit called Data Prep Kit (DPK). DPK is architected and designed to enable users to scale their data preparation to their needs. With DPK they can prepare data on a local machine or effortlessly scale to run on a cluster with thousands of CPU Cores. DPK comes with a highly scalable, yet extensible set of modules that transform natural language and code data. If the user needs additional transforms, they can be easily developed using extensive DPK support for transform creation. These modules can be used independently or pipelined to perform a series of operations. In this paper, we describe DPK architecture and show its performance from a small scale to a very large number of CPUs. The modules from DPK have been used for the preparation of Granite Models [1] [2]. We believe DPK is a valuable contribution to the AI community to easily prepare data to enhance the performance of their LLM models or to fine-tune models with Retrieval-Augmented Generation (RAG).
HASSOD: Hierarchical Adaptive Self-Supervised Object Detection
Feb 05, 2024The human visual perception system demonstrates exceptional capabilities in learning without explicit supervision and understanding the part-to-whole composition of objects. Drawing inspiration from these two abilities, we propose Hierarchical Adaptive Self-Supervised Object Detection (HASSOD), a novel approach that learns to detect objects and understand their compositions without human supervision. HASSOD employs a hierarchical adaptive clustering strategy to group regions into object masks based on self-supervised visual representations, adaptively determining the number of objects per image. Furthermore, HASSOD identifies the hierarchical levels of objects in terms of composition, by analyzing coverage relations between masks and constructing tree structures. This additional self-supervised learning task leads to improved detection performance and enhanced interpretability. Lastly, we abandon the inefficient multi-round self-training process utilized in prior methods and instead adapt the Mean Teacher framework from semi-supervised learning, which leads to a smoother and more efficient training process. Through extensive experiments on prevalent image datasets, we demonstrate the superiority of HASSOD over existing methods, thereby advancing the state of the art in self-supervised object detection. Notably, we improve Mask AR from 20.2 to 22.5 on LVIS, and from 17.0 to 26.0 on SA-1B. Project page: https://HASSOD-NeurIPS23.github.io.
Contrastive Mean Teacher for Domain Adaptive Object Detectors
May 04, 2023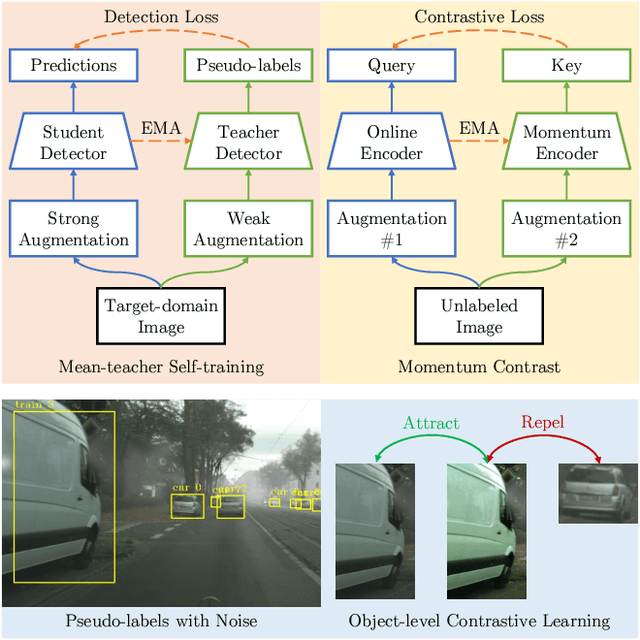
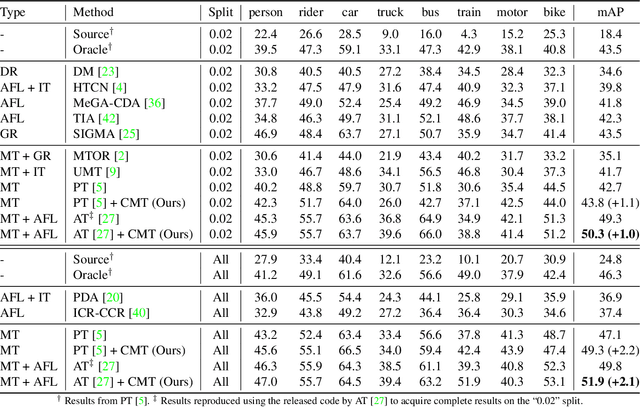
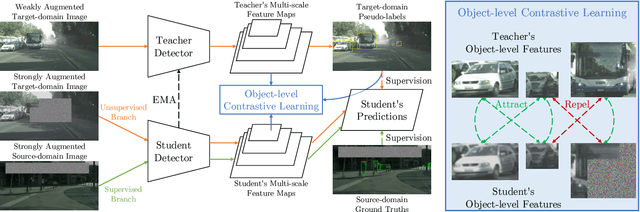
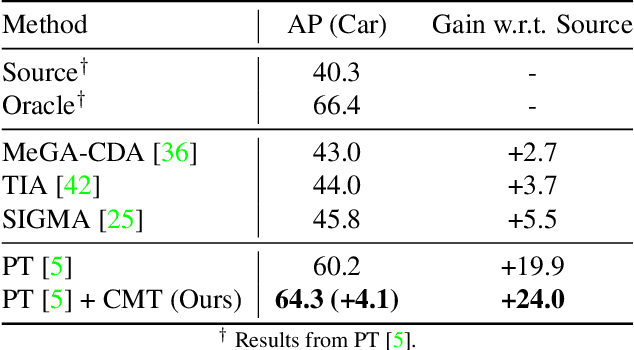
Object detectors often suffer from the domain gap between training (source domain) and real-world applications (target domain). Mean-teacher self-training is a powerful paradigm in unsupervised domain adaptation for object detection, but it struggles with low-quality pseudo-labels. In this work, we identify the intriguing alignment and synergy between mean-teacher self-training and contrastive learning. Motivated by this, we propose Contrastive Mean Teacher (CMT) -- a unified, general-purpose framework with the two paradigms naturally integrated to maximize beneficial learning signals. Instead of using pseudo-labels solely for final predictions, our strategy extracts object-level features using pseudo-labels and optimizes them via contrastive learning, without requiring labels in the target domain. When combined with recent mean-teacher self-training methods, CMT leads to new state-of-the-art target-domain performance: 51.9% mAP on Foggy Cityscapes, outperforming the previously best by 2.1% mAP. Notably, CMT can stabilize performance and provide more significant gains as pseudo-label noise increases.
Gradient-based Uncertainty Attribution for Explainable Bayesian Deep Learning
Apr 10, 2023
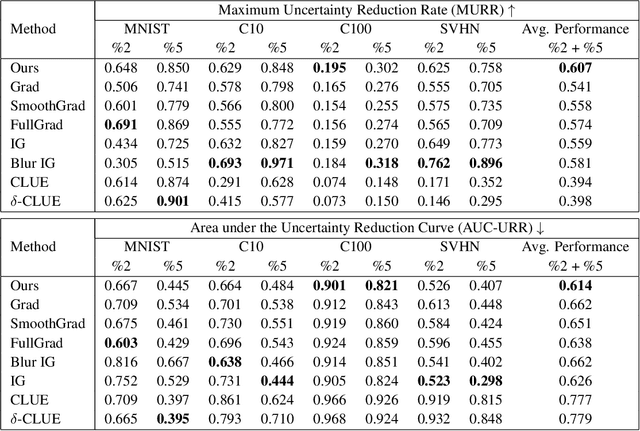


Predictions made by deep learning models are prone to data perturbations, adversarial attacks, and out-of-distribution inputs. To build a trusted AI system, it is therefore critical to accurately quantify the prediction uncertainties. While current efforts focus on improving uncertainty quantification accuracy and efficiency, there is a need to identify uncertainty sources and take actions to mitigate their effects on predictions. Therefore, we propose to develop explainable and actionable Bayesian deep learning methods to not only perform accurate uncertainty quantification but also explain the uncertainties, identify their sources, and propose strategies to mitigate the uncertainty impacts. Specifically, we introduce a gradient-based uncertainty attribution method to identify the most problematic regions of the input that contribute to the prediction uncertainty. Compared to existing methods, the proposed UA-Backprop has competitive accuracy, relaxed assumptions, and high efficiency. Moreover, we propose an uncertainty mitigation strategy that leverages the attribution results as attention to further improve the model performance. Both qualitative and quantitative evaluations are conducted to demonstrate the effectiveness of our proposed methods.
AVLnet: Learning Audio-Visual Language Representations from Instructional Videos
Jun 16, 2020


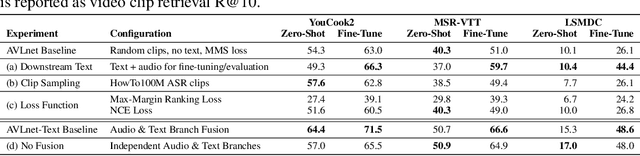
Current methods for learning visually grounded language from videos often rely on time-consuming and expensive data collection, such as human annotated textual summaries or machine generated automatic speech recognition transcripts. In this work, we introduce Audio-Video Language Network (AVLnet), a self-supervised network that learns a shared audio-visual embedding space directly from raw video inputs. We circumvent the need for annotation and instead learn audio-visual language representations directly from randomly segmented video clips and their raw audio waveforms. We train AVLnet on publicly available instructional videos and evaluate our model on video clip and language retrieval tasks on three video datasets. Our proposed model outperforms several state-of-the-art text-video baselines by up to 11.8% in a video clip retrieval task, despite operating on the raw audio instead of manually annotated text captions. Further, we show AVLnet is capable of integrating textual information, increasing its modularity and improving performance by up to 20.3% on the video clip retrieval task. Finally, we perform analysis of AVLnet's learned representations, showing our model has learned to relate visual objects with salient words and natural sounds.
Affective Computing for Large-Scale Heterogeneous Multimedia Data: A Survey
Oct 03, 2019

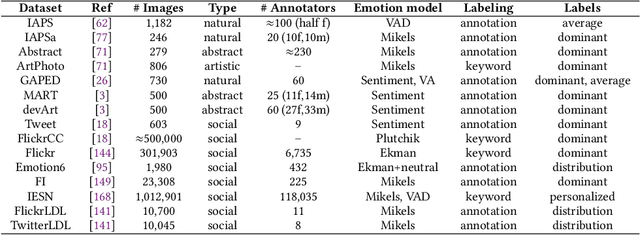

The wide popularity of digital photography and social networks has generated a rapidly growing volume of multimedia data (i.e., image, music, and video), resulting in a great demand for managing, retrieving, and understanding these data. Affective computing (AC) of these data can help to understand human behaviors and enable wide applications. In this article, we survey the state-of-the-art AC technologies comprehensively for large-scale heterogeneous multimedia data. We begin this survey by introducing the typical emotion representation models from psychology that are widely employed in AC. We briefly describe the available datasets for evaluating AC algorithms. We then summarize and compare the representative methods on AC of different multimedia types, i.e., images, music, videos, and multimodal data, with the focus on both handcrafted features-based methods and deep learning methods. Finally, we discuss some challenges and future directions for multimedia affective computing.
Locally-Consistent Deformable Convolution Networks for Fine-Grained Action Detection
Nov 22, 2018
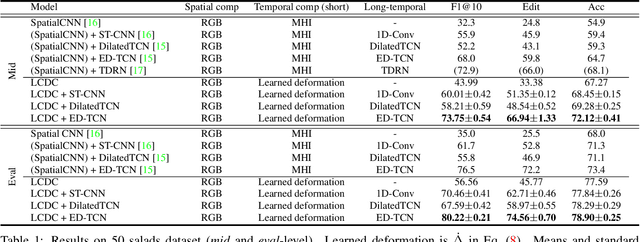
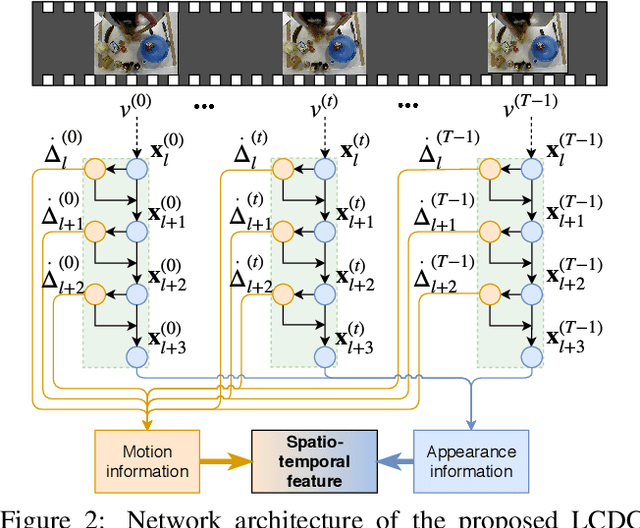
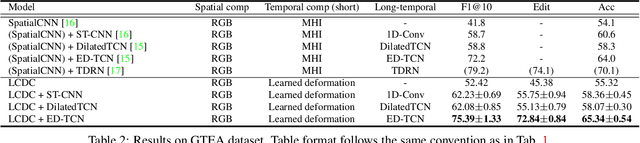
Fine-grained action detection is an important task with numerous applications in robotics, human-computer interaction, and video surveillance. Several existing methods use the popular two-stream approach, which learns the spatial and temporal information independently from one another. Additionally, the temporal stream of the model usually relies on extracted optical flow from the video stream. In this work, we propose a deep learning model to jointly learn both spatial and temporal information without the necessity of optical flow. We also propose a novel convolution, namely locally-consistent deformable convolution, which enforces a local coherency constraint on the receptive fields. The model produces short-term spatio-temporal features, which can be flexibly used in conjunction with other long-temporal modeling networks. The proposed features used in conjunction with a major state-of-the-art long-temporal model ED-TCN outperforms the original ED-TCN implementation on two fine-grained action datasets: 50 Salads and GTEA, by up to 10.0% and 4.3%, and also outperforms the recent state-of-the-art TDRN, by up to 5.9% and 2.6%.
Automatic Curation of Golf Highlights using Multimodal Excitement Features
Jul 22, 2017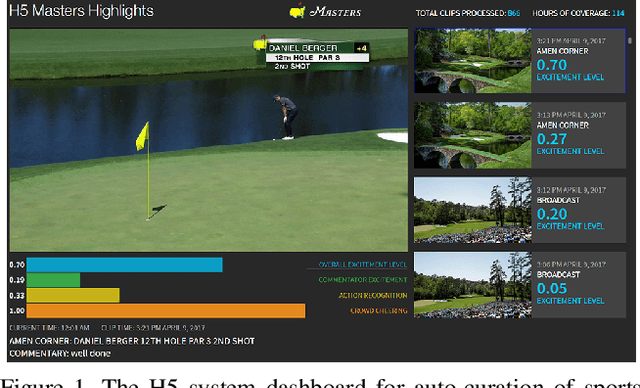

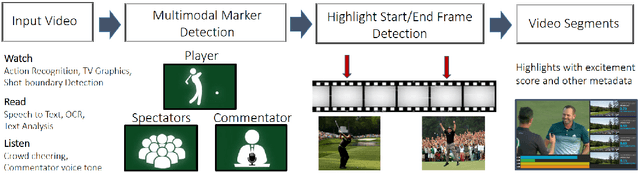
The production of sports highlight packages summarizing a game's most exciting moments is an essential task for broadcast media. Yet, it requires labor-intensive video editing. We propose a novel approach for auto-curating sports highlights, and use it to create a real-world system for the editorial aid of golf highlight reels. Our method fuses information from the players' reactions (action recognition such as high-fives and fist pumps), spectators (crowd cheering), and commentator (tone of the voice and word analysis) to determine the most interesting moments of a game. We accurately identify the start and end frames of key shot highlights with additional metadata, such as the player's name and the hole number, allowing personalized content summarization and retrieval. In addition, we introduce new techniques for learning our classifiers with reduced manual training data annotation by exploiting the correlation of different modalities. Our work has been demonstrated at a major golf tournament, successfully extracting highlights from live video streams over four consecutive days.