 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGT4SD: Generative Toolkit for Scientific Discovery
Jul 08, 2022
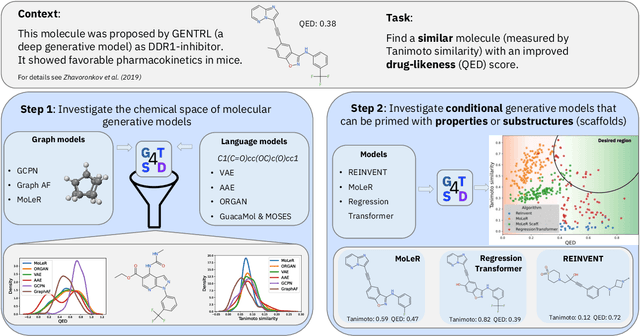
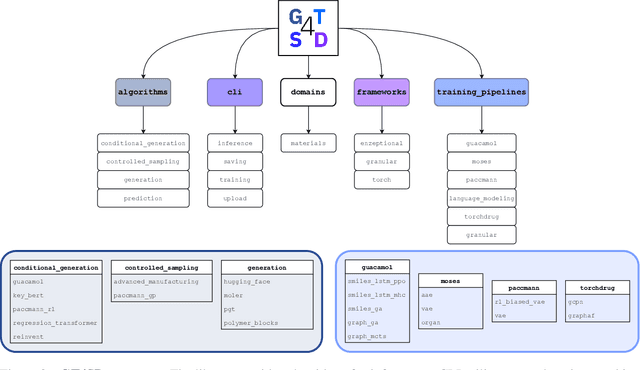
With the growing availability of data within various scientific domains, generative models hold enormous potential to accelerate scientific discovery at every step of the scientific method. Perhaps their most valuable application lies in the speeding up of what has traditionally been the slowest and most challenging step of coming up with a hypothesis. Powerful representations are now being learned from large volumes of data to generate novel hypotheses, which is making a big impact on scientific discovery applications ranging from material design to drug discovery. The GT4SD (https://github.com/GT4SD/gt4sd-core) is an extensible open-source library that enables scientists, developers and researchers to train and use state-of-the-art generative models for hypothesis generation in scientific discovery. GT4SD supports a variety of uses of generative models across material science and drug discovery, including molecule discovery and design based on properties related to target proteins, omic profiles, scaffold distances, binding energies and more.
Covering the News with (AI) Style
Jan 05, 2020



We introduce a multi-modal discriminative and generative frame-work capable of assisting humans in producing visual content re-lated to a given theme, starting from a collection of documents(textual, visual, or both). This framework can be used by edit or to generate images for articles, as well as books or music album covers. Motivated by a request from the The New York Times (NYT) seeking help to use AI to create art for their special section on Artificial Intelligence, we demonstrated the application of our system in producing such image.
A New Benchmark for Evaluation of Cross-Domain Few-Shot Learning
Dec 16, 2019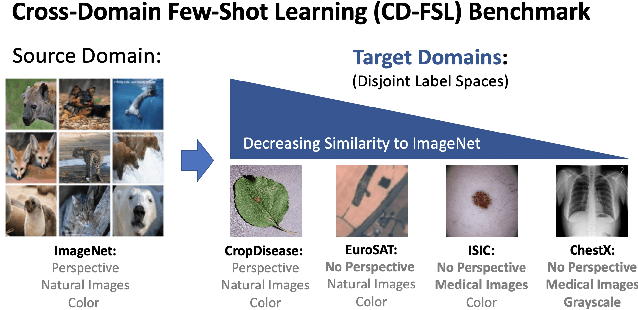
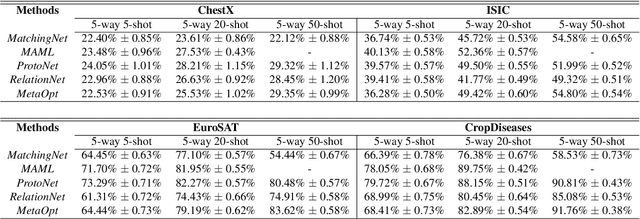
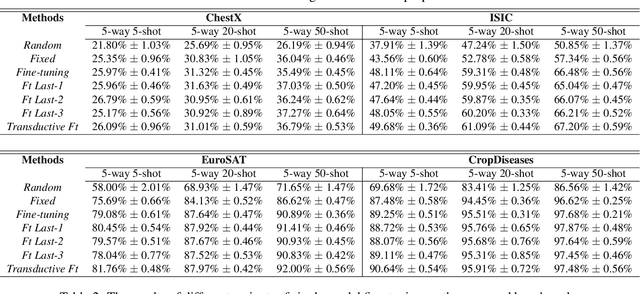
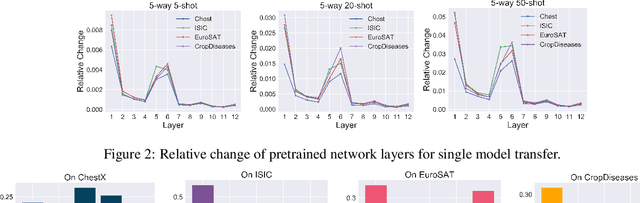
Recent progress on few-shot learning has largely re-lied on annotated data for meta-learning, sampled from the same domain as the novel classes. However, in many applications, collecting data for meta-learning is infeasible or impossible. This leads to the cross-domain few-shot learn-ing problem, where a large domain shift exists between base and novel classes. Although some preliminary investigation of the few-shot methods under domain shift exists, a standard benchmark for cross-domain few-shot learning is not yet established. In this paper, we propose the cross-domain few-shot learning (CD-FSL) benchmark, consist-ing of images from diverse domains with varying similarity to ImageNet, ranging from crop disease images, satellite images, and medical images. Extensive experiments on the proposed benchmark are performed to compare an array of state-of-art meta-learning and transfer learning approaches, including various forms of single model fine-tuning and ensemble learning. The results demonstrate that current meta-learning methods underperform in relation to simple fine-tuning by 12.8% average accuracy. Accuracy of all methods tend to correlate with dataset similarity toImageNet. In addition, the relative performance gain with increasing number of shots is greater with transfer methods compared to meta-learning. Finally, we demonstrate that transferring from multiple pretrained models achieves best performance, with accuracy improvements of 14.9% and 1.9% versus the best of meta-learning and single model fine-tuning approaches, respectively. In summary, the proposed benchmark serves as a challenging platform to guide future research on cross-domain few-shot learning due to its spectrum of diversity and coverage
Diversity in Faces
Jan 30, 2019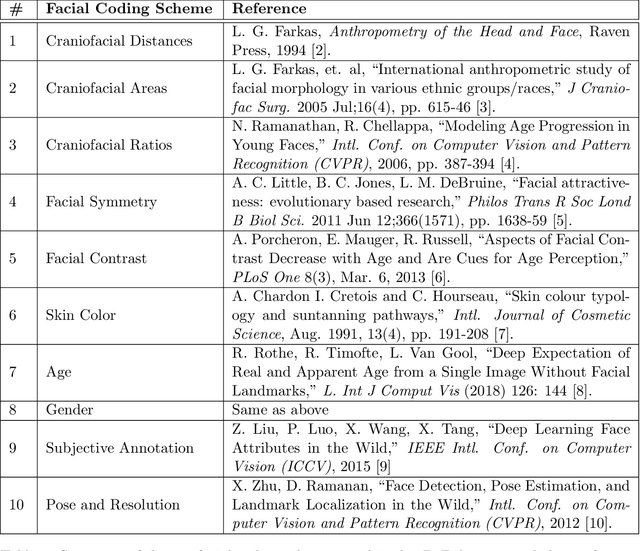
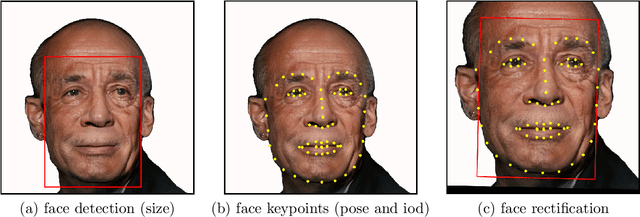
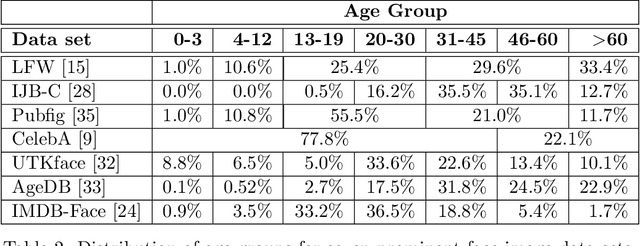
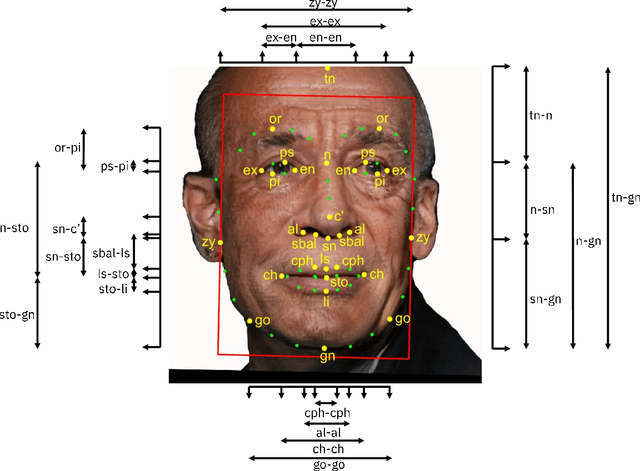
Face recognition is a long standing challenge in the field of Artificial Intelligence (AI). The goal is to create systems that accurately detect, recognize, verify, and understand human faces. There are significant technical hurdles in making these systems accurate, particularly in unconstrained settings due to confounding factors related to pose, resolution, illumination, occlusion, and viewpoint. However, with recent advances in neural networks, face recognition has achieved unprecedented accuracy, largely built on data-driven deep learning methods. While this is encouraging, a critical aspect that is limiting facial recognition accuracy and fairness is inherent facial diversity. Every face is different. Every face reflects something unique about us. Aspects of our heritage - including race, ethnicity, culture, geography - and our individual identify - age, gender, and other visible manifestations of self-expression, are reflected in our faces. We expect face recognition to work equally accurately for every face. Face recognition needs to be fair. As we rely on data-driven methods to create face recognition technology, we need to ensure necessary balance and coverage in training data. However, there are still scientific questions about how to represent and extract pertinent facial features and quantitatively measure facial diversity. Towards this goal, Diversity in Faces (DiF) provides a data set of one million annotated human face images for advancing the study of facial diversity. The annotations are generated using ten well-established facial coding schemes from the scientific literature. The facial coding schemes provide human-interpretable quantitative measures of facial features. We believe that by making the extracted coding schemes available on a large set of faces, we can accelerate research and development towards creating more fair and accurate facial recognition systems.
Collaborative Human-AI (CHAI): Evidence-Based Interpretable Melanoma Classification in Dermoscopic Images
Aug 01, 2018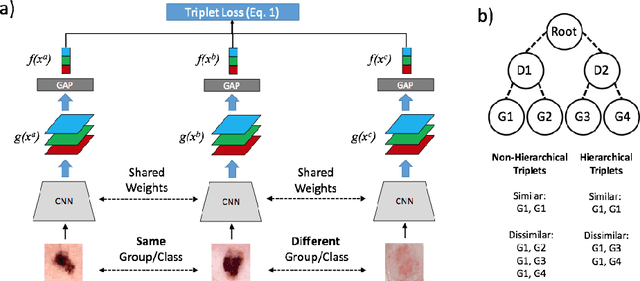
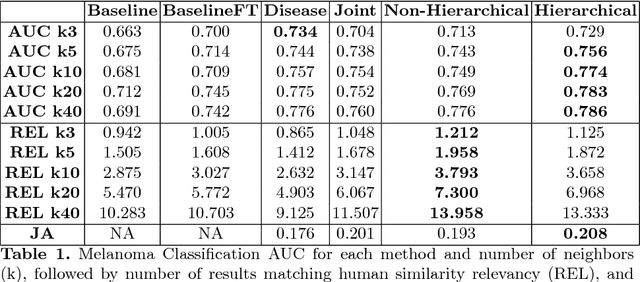
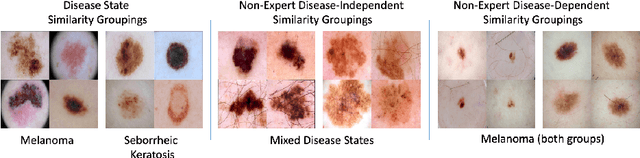
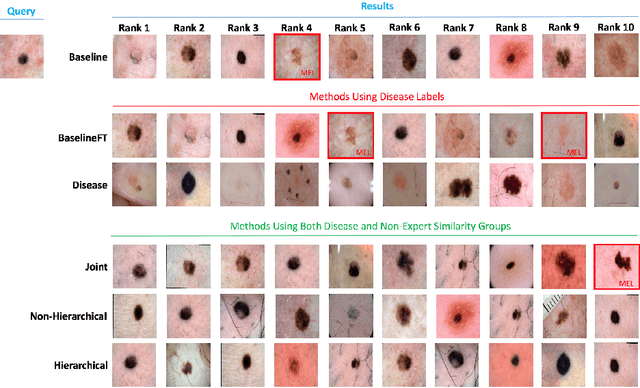
Automated dermoscopic image analysis has witnessed rapid growth in diagnostic performance. Yet adoption faces resistance, in part, because no evidence is provided to support decisions. In this work, an approach for evidence-based classification is presented. A feature embedding is learned with CNNs, triplet-loss, and global average pooling, and used to classify via kNN search. Evidence is provided as both the discovered neighbors, as well as localized image regions most relevant to measuring distance between query and neighbors. To ensure that results are relevant in terms of both label accuracy and human visual similarity for any skill level, a novel hierarchical triplet logic is implemented to jointly learn an embedding according to disease labels and non-expert similarity. Results are improved over baselines trained on disease labels alone, as well as standard multiclass loss. Quantitative relevance of results, according to non-expert similarity, as well as localized image regions, are also significantly improved.
Automatic Curation of Golf Highlights using Multimodal Excitement Features
Jul 22, 2017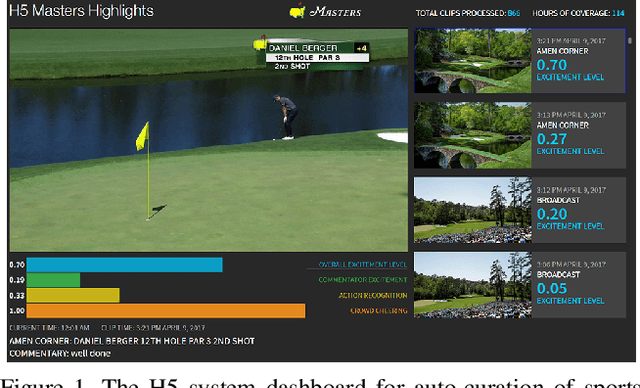

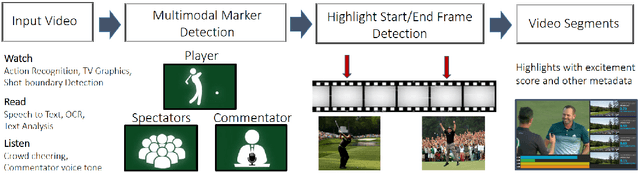
The production of sports highlight packages summarizing a game's most exciting moments is an essential task for broadcast media. Yet, it requires labor-intensive video editing. We propose a novel approach for auto-curating sports highlights, and use it to create a real-world system for the editorial aid of golf highlight reels. Our method fuses information from the players' reactions (action recognition such as high-fives and fist pumps), spectators (crowd cheering), and commentator (tone of the voice and word analysis) to determine the most interesting moments of a game. We accurately identify the start and end frames of key shot highlights with additional metadata, such as the player's name and the hole number, allowing personalized content summarization and retrieval. In addition, we introduce new techniques for learning our classifiers with reduced manual training data annotation by exploiting the correlation of different modalities. Our work has been demonstrated at a major golf tournament, successfully extracting highlights from live video streams over four consecutive days.
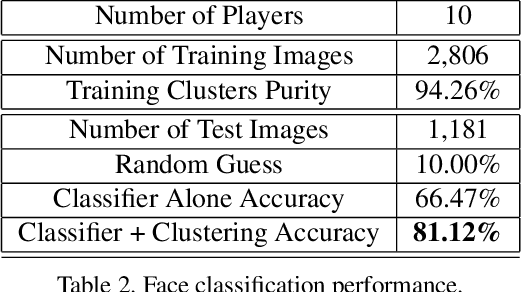
Deep Learning Ensembles for Melanoma Recognition in Dermoscopy Images
Oct 18, 2016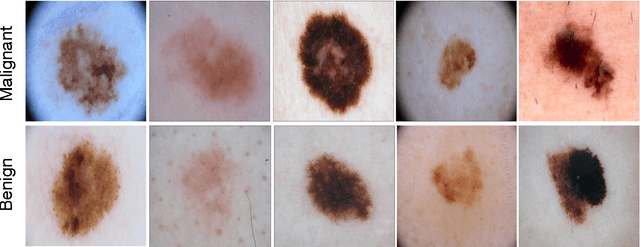

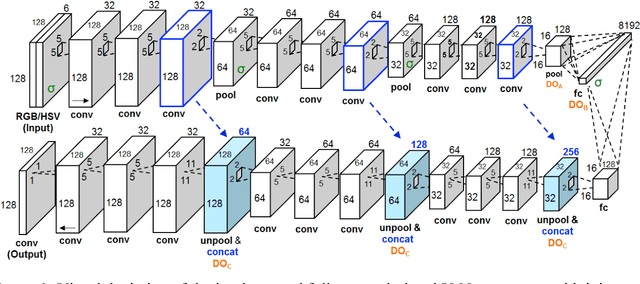
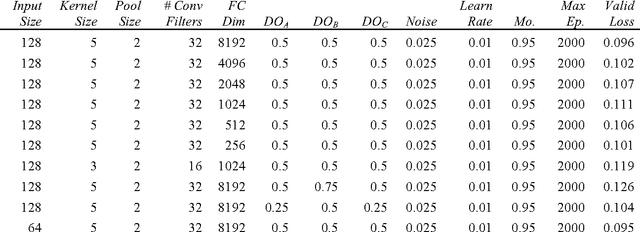
Melanoma is the deadliest form of skin cancer. While curable with early detection, only highly trained specialists are capable of accurately recognizing the disease. As expertise is in limited supply, automated systems capable of identifying disease could save lives, reduce unnecessary biopsies, and reduce costs. Toward this goal, we propose a system that combines recent developments in deep learning with established machine learning approaches, creating ensembles of methods that are capable of segmenting skin lesions, as well as analyzing the detected area and surrounding tissue for melanoma detection. The system is evaluated using the largest publicly available benchmark dataset of dermoscopic images, containing 900 training and 379 testing images. New state-of-the-art performance levels are demonstrated, leading to an improvement in the area under receiver operating characteristic curve of 7.5% (0.843 vs. 0.783), in average precision of 4% (0.649 vs. 0.624), and in specificity measured at the clinically relevant 95% sensitivity operating point 2.9 times higher than the previous state-of-the-art (36.8% specificity compared to 12.5%). Compared to the average of 8 expert dermatologists on a subset of 100 test images, the proposed system produces a higher accuracy (76% vs. 70.5%), and specificity (62% vs. 59%) evaluated at an equivalent sensitivity (82%).
* URL for the IBM Journal of Research and Development: http://www.research.ibm.com/journal/
Oracle performance for visual captioning
Sep 14, 2016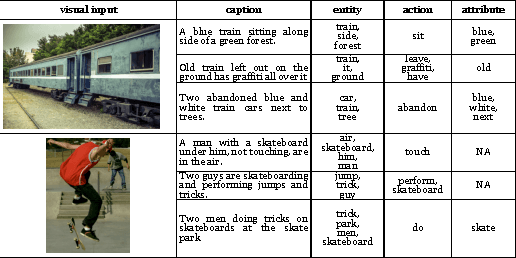
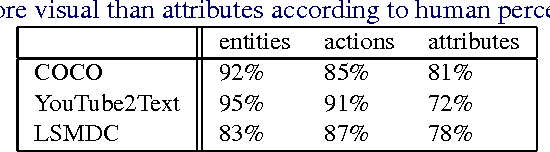
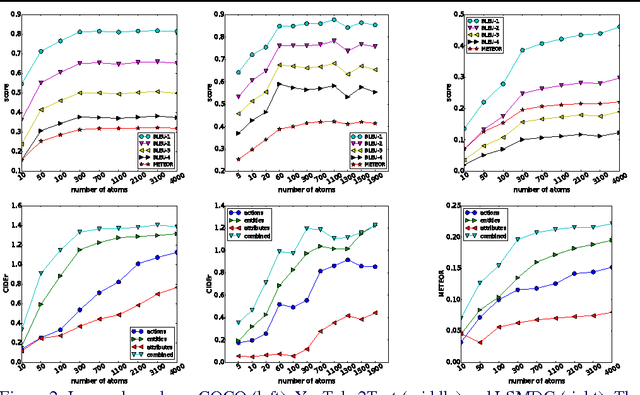
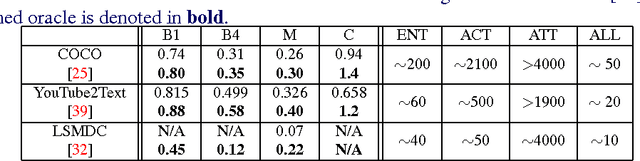
The task of associating images and videos with a natural language description has attracted a great amount of attention recently. Rapid progress has been made in terms of both developing novel algorithms and releasing new datasets. Indeed, the state-of-the-art results on some of the standard datasets have been pushed into the regime where it has become more and more difficult to make significant improvements. Instead of proposing new models, this work investigates the possibility of empirically establishing performance upper bounds on various visual captioning datasets without extra data labelling effort or human evaluation. In particular, it is assumed that visual captioning is decomposed into two steps: from visual inputs to visual concepts, and from visual concepts to natural language descriptions. One would be able to obtain an upper bound when assuming the first step is perfect and only requiring training a conditional language model for the second step. We demonstrate the construction of such bounds on MS-COCO, YouTube2Text and LSMDC (a combination of M-VAD and MPII-MD). Surprisingly, despite of the imperfect process we used for visual concept extraction in the first step and the simplicity of the language model for the second step, we show that current state-of-the-art models fall short when being compared with the learned upper bounds. Furthermore, with such a bound, we quantify several important factors concerning image and video captioning: the number of visual concepts captured by different models, the trade-off between the amount of visual elements captured and their accuracy, and the intrinsic difficulty and blessing of different datasets.