 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity in Faces
Paper and Code
Jan 30, 2019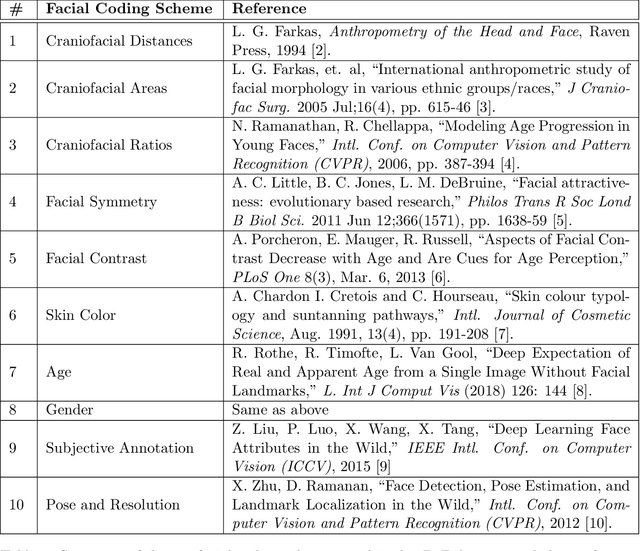
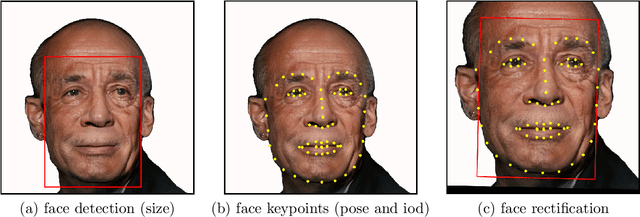
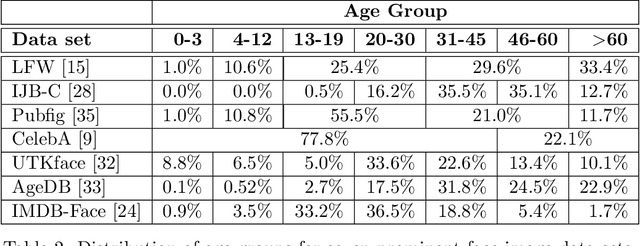
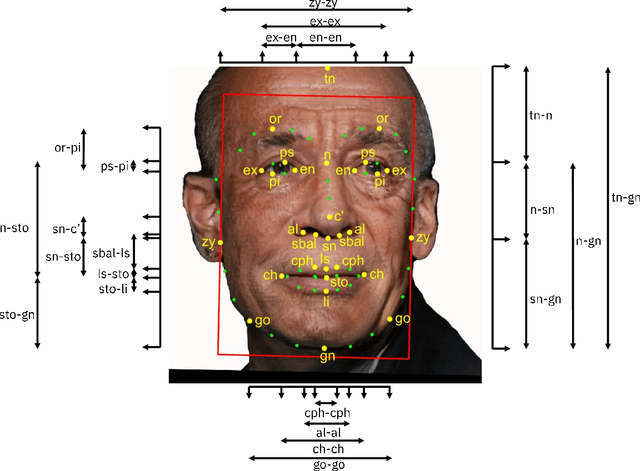
Face recognition is a long standing challenge in the field of Artificial Intelligence (AI). The goal is to create systems that accurately detect, recognize, verify, and understand human faces. There are significant technical hurdles in making these systems accurate, particularly in unconstrained settings due to confounding factors related to pose, resolution, illumination, occlusion, and viewpoint. However, with recent advances in neural networks, face recognition has achieved unprecedented accuracy, largely built on data-driven deep learning methods. While this is encouraging, a critical aspect that is limiting facial recognition accuracy and fairness is inherent facial diversity. Every face is different. Every face reflects something unique about us. Aspects of our heritage - including race, ethnicity, culture, geography - and our individual identify - age, gender, and other visible manifestations of self-expression, are reflected in our faces. We expect face recognition to work equally accurately for every face. Face recognition needs to be fair. As we rely on data-driven methods to create face recognition technology, we need to ensure necessary balance and coverage in training data. However, there are still scientific questions about how to represent and extract pertinent facial features and quantitatively measure facial diversity. Towards this goal, Diversity in Faces (DiF) provides a data set of one million annotated human face images for advancing the study of facial diversity. The annotations are generated using ten well-established facial coding schemes from the scientific literature. The facial coding schemes provide human-interpretable quantitative measures of facial features. We believe that by making the extracted coding schemes available on a large set of faces, we can accelerate research and development towards creating more fair and accurate facial recognition systems.