 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask2Sim : Towards Effective Pre-training and Transfer from Synthetic Data
Nov 30, 2021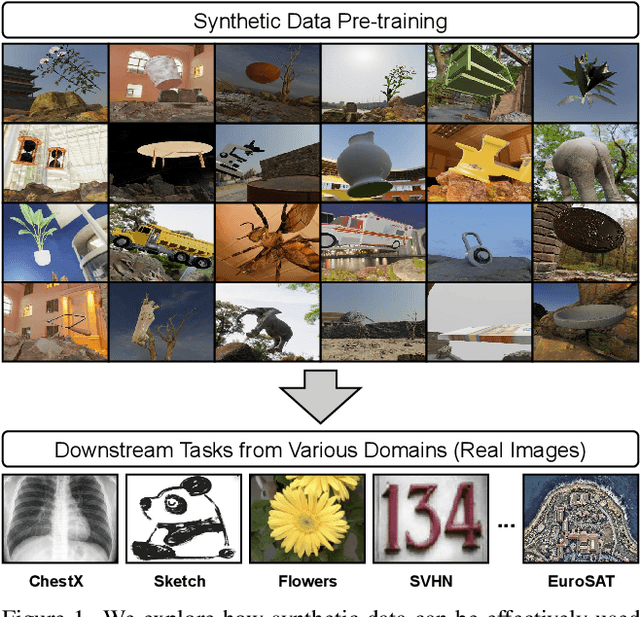
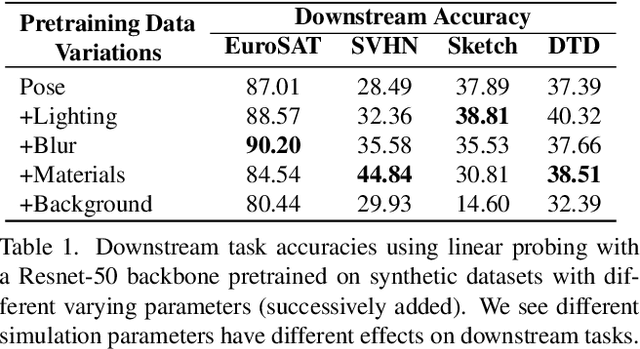
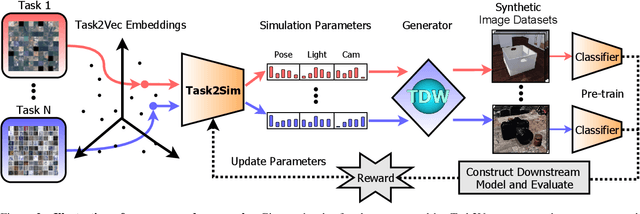
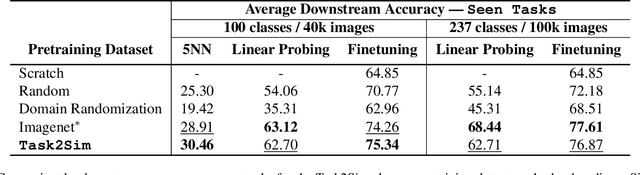
Pre-training models on Imagenet or other massive datasets of real images has led to major advances in computer vision, albeit accompanied with shortcomings related to curation cost, privacy, usage rights, and ethical issues. In this paper, for the first time, we study the transferability of pre-trained models based on synthetic data generated by graphics simulators to downstream tasks from very different domains. In using such synthetic data for pre-training, we find that downstream performance on different tasks are favored by different configurations of simulation parameters (e.g. lighting, object pose, backgrounds, etc.), and that there is no one-size-fits-all solution. It is thus better to tailor synthetic pre-training data to a specific downstream task, for best performance. We introduce Task2Sim, a unified model mapping downstream task representations to optimal simulation parameters to generate synthetic pre-training data for them. Task2Sim learns this mapping by training to find the set of best parameters on a set of "seen" tasks. Once trained, it can then be used to predict best simulation parameters for novel "unseen" tasks in one shot, without requiring additional training. Given a budget in number of images per class, our extensive experiments with 20 diverse downstream tasks show Task2Sim's task-adaptive pre-training data results in significantly better downstream performance than non-adaptively choosing simulation parameters on both seen and unseen tasks. It is even competitive with pre-training on real images from Imagenet.
Diversity in Faces
Jan 30, 2019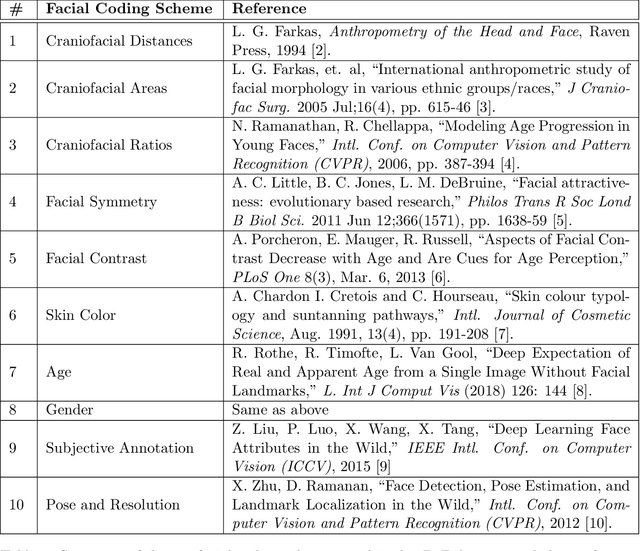
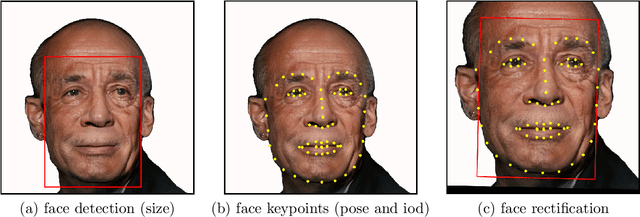
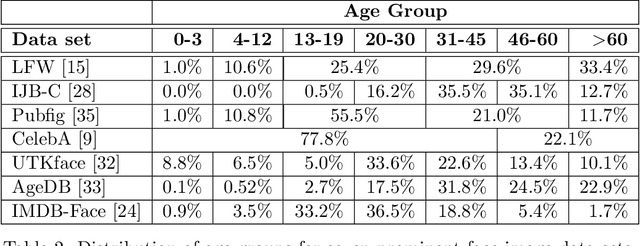
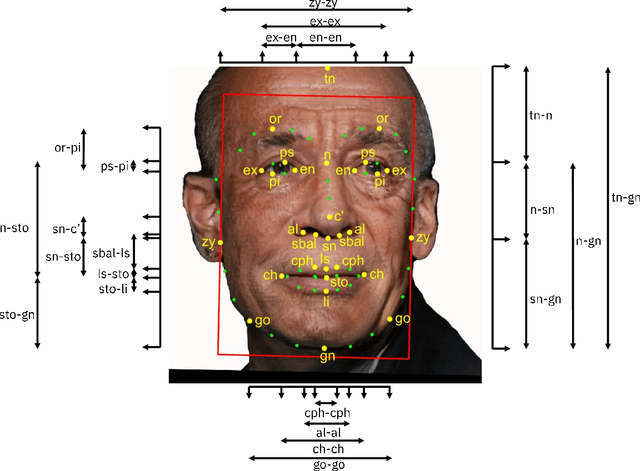
Face recognition is a long standing challenge in the field of Artificial Intelligence (AI). The goal is to create systems that accurately detect, recognize, verify, and understand human faces. There are significant technical hurdles in making these systems accurate, particularly in unconstrained settings due to confounding factors related to pose, resolution, illumination, occlusion, and viewpoint. However, with recent advances in neural networks, face recognition has achieved unprecedented accuracy, largely built on data-driven deep learning methods. While this is encouraging, a critical aspect that is limiting facial recognition accuracy and fairness is inherent facial diversity. Every face is different. Every face reflects something unique about us. Aspects of our heritage - including race, ethnicity, culture, geography - and our individual identify - age, gender, and other visible manifestations of self-expression, are reflected in our faces. We expect face recognition to work equally accurately for every face. Face recognition needs to be fair. As we rely on data-driven methods to create face recognition technology, we need to ensure necessary balance and coverage in training data. However, there are still scientific questions about how to represent and extract pertinent facial features and quantitatively measure facial diversity. Towards this goal, Diversity in Faces (DiF) provides a data set of one million annotated human face images for advancing the study of facial diversity. The annotations are generated using ten well-established facial coding schemes from the scientific literature. The facial coding schemes provide human-interpretable quantitative measures of facial features. We believe that by making the extracted coding schemes available on a large set of faces, we can accelerate research and development towards creating more fair and accurate facial recognition systems.
Locally-Consistent Deformable Convolution Networks for Fine-Grained Action Detection
Nov 22, 2018
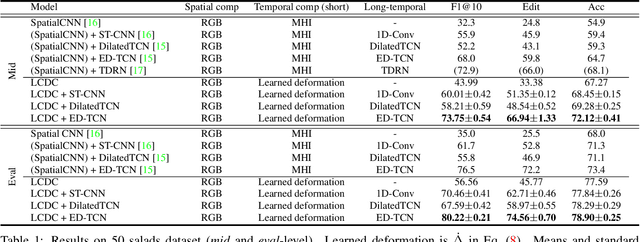
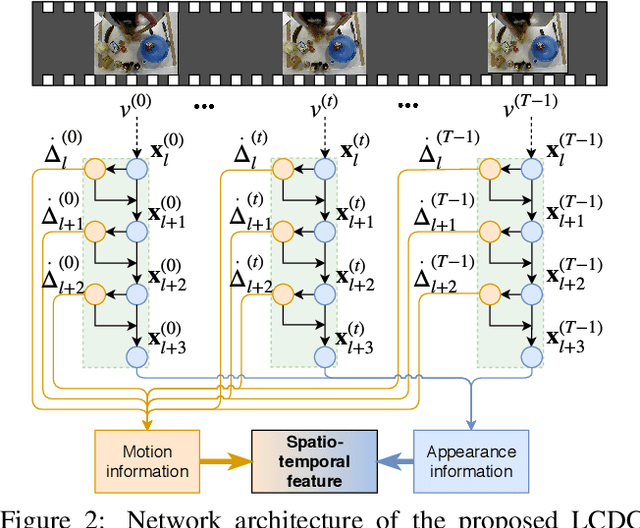
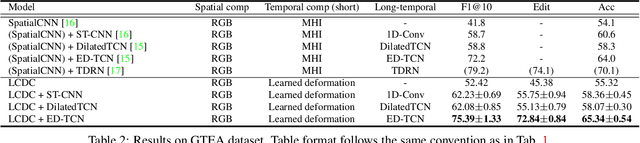
Fine-grained action detection is an important task with numerous applications in robotics, human-computer interaction, and video surveillance. Several existing methods use the popular two-stream approach, which learns the spatial and temporal information independently from one another. Additionally, the temporal stream of the model usually relies on extracted optical flow from the video stream. In this work, we propose a deep learning model to jointly learn both spatial and temporal information without the necessity of optical flow. We also propose a novel convolution, namely locally-consistent deformable convolution, which enforces a local coherency constraint on the receptive fields. The model produces short-term spatio-temporal features, which can be flexibly used in conjunction with other long-temporal modeling networks. The proposed features used in conjunction with a major state-of-the-art long-temporal model ED-TCN outperforms the original ED-TCN implementation on two fine-grained action datasets: 50 Salads and GTEA, by up to 10.0% and 4.3%, and also outperforms the recent state-of-the-art TDRN, by up to 5.9% and 2.6%.
RED-Net: A Recurrent Encoder-Decoder Network for Video-based Face Alignment
Jan 17, 2018
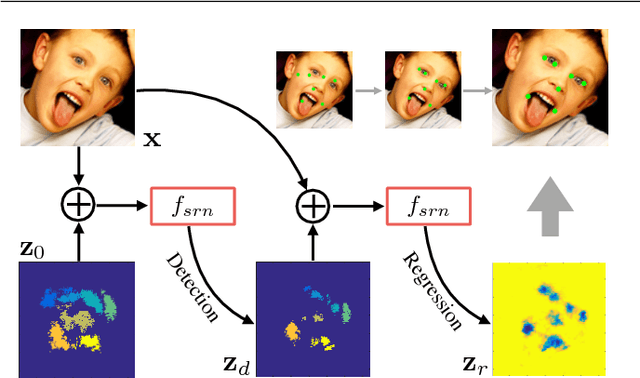
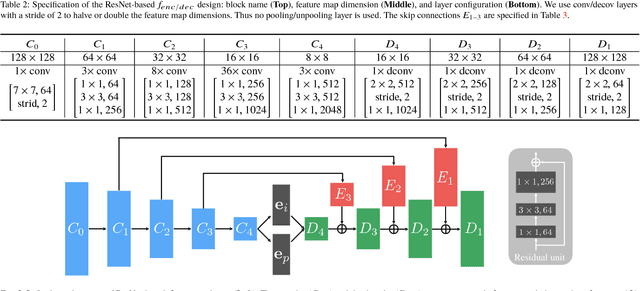
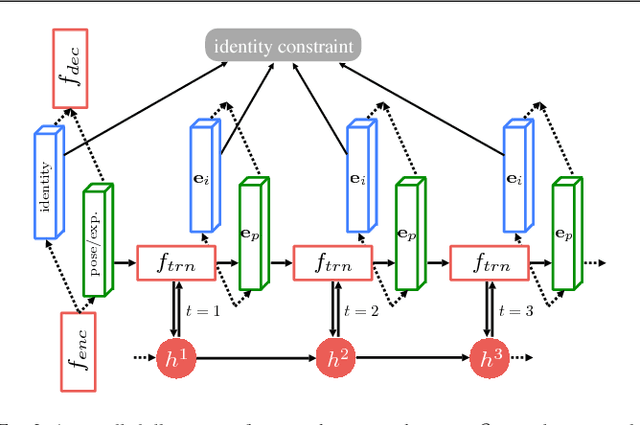
We propose a novel method for real-time face alignment in videos based on a recurrent encoder-decoder network model. Our proposed model predicts 2D facial point heat maps regularized by both detection and regression loss, while uniquely exploiting recurrent learning at both spatial and temporal dimensions. At the spatial level, we add a feedback loop connection between the combined output response map and the input, in order to enable iterative coarse-to-fine face alignment using a single network model, instead of relying on traditional cascaded model ensembles. At the temporal level, we first decouple the features in the bottleneck of the network into temporal-variant factors, such as pose and expression, and temporal-invariant factors, such as identity information. Temporal recurrent learning is then applied to the decoupled temporal-variant features. We show that such feature disentangling yields better generalization and significantly more accurate results at test time. We perform a comprehensive experimental analysis, showing the importance of each component of our proposed model, as well as superior results over the state of the art and several variations of our method in standard datasets.
Automatic Curation of Golf Highlights using Multimodal Excitement Features
Jul 22, 2017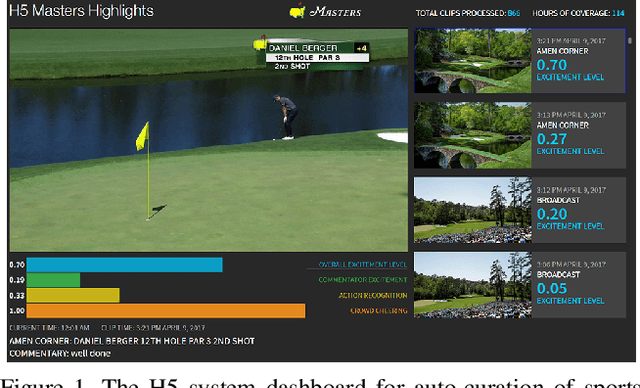

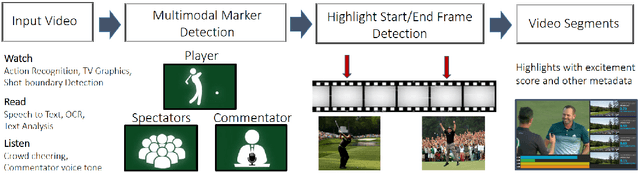
The production of sports highlight packages summarizing a game's most exciting moments is an essential task for broadcast media. Yet, it requires labor-intensive video editing. We propose a novel approach for auto-curating sports highlights, and use it to create a real-world system for the editorial aid of golf highlight reels. Our method fuses information from the players' reactions (action recognition such as high-fives and fist pumps), spectators (crowd cheering), and commentator (tone of the voice and word analysis) to determine the most interesting moments of a game. We accurately identify the start and end frames of key shot highlights with additional metadata, such as the player's name and the hole number, allowing personalized content summarization and retrieval. In addition, we introduce new techniques for learning our classifiers with reduced manual training data annotation by exploiting the correlation of different modalities. Our work has been demonstrated at a major golf tournament, successfully extracting highlights from live video streams over four consecutive days.
A Recurrent Encoder-Decoder Network for Sequential Face Alignment
Aug 23, 2016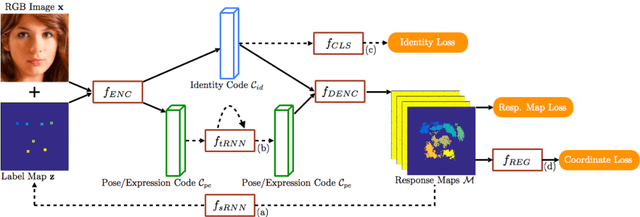
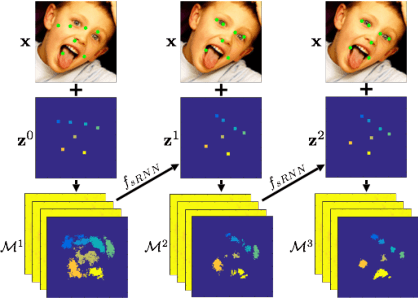

We propose a novel recurrent encoder-decoder network model for real-time video-based face alignment. Our proposed model predicts 2D facial point maps regularized by a regression loss, while uniquely exploiting recurrent learning at both spatial and temporal dimensions. At the spatial level, we add a feedback loop connection between the combined output response map and the input, in order to enable iterative coarse-to-fine face alignment using a single network model. At the temporal level, we first decouple the features in the bottleneck of the network into temporal-variant factors, such as pose and expression, and temporal-invariant factors, such as identity information. Temporal recurrent learning is then applied to the decoupled temporal-variant features, yielding better generalization and significantly more accurate results at test time. We perform a comprehensive experimental analysis, showing the importance of each component of our proposed model, as well as superior results over the state-of-the-art in standard datasets.
A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
Jul 25, 2016

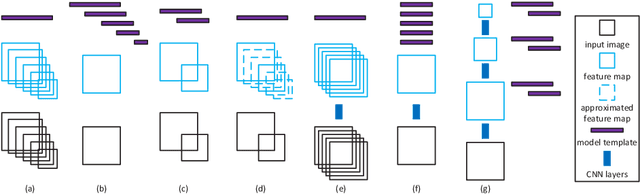
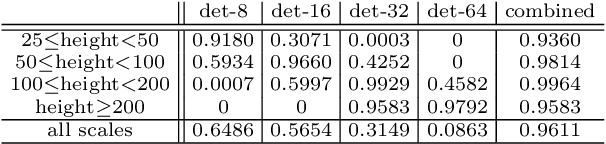
A unified deep neural network, denoted the multi-scale CNN (MS-CNN), is proposed for fast multi-scale object detection. The MS-CNN consists of a proposal sub-network and a detection sub-network. In the proposal sub-network, detection is performed at multiple output layers, so that receptive fields match objects of different scales. These complementary scale-specific detectors are combined to produce a strong multi-scale object detector. The unified network is learned end-to-end, by optimizing a multi-task loss. Feature upsampling by deconvolution is also explored, as an alternative to input upsampling, to reduce the memory and computation costs. State-of-the-art object detection performance, at up to 15 fps, is reported on datasets, such as KITTI and Caltech, containing a substantial number of small objects.
An exploration of parameter redundancy in deep networks with circulant projections
Oct 27, 2015
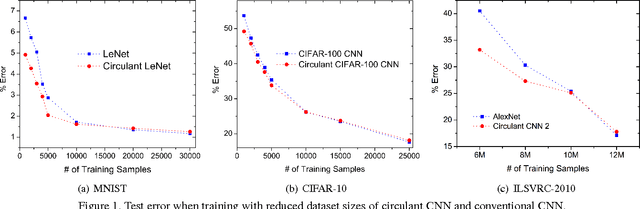
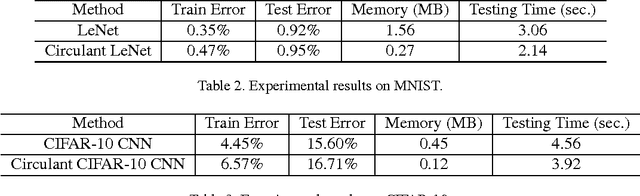

We explore the redundancy of parameters in deep neural networks by replacing the conventional linear projection in fully-connected layers with the circulant projection. The circulant structure substantially reduces memory footprint and enables the use of the Fast Fourier Transform to speed up the computation. Considering a fully-connected neural network layer with d input nodes, and d output nodes, this method improves the time complexity from O(d^2) to O(dlogd) and space complexity from O(d^2) to O(d). The space savings are particularly important for modern deep convolutional neural network architectures, where fully-connected layers typically contain more than 90% of the network parameters. We further show that the gradient computation and optimization of the circulant projections can be performed very efficiently. Our experiments on three standard datasets show that the proposed approach achieves this significant gain in storage and efficiency with minimal increase in error rate compared to neural networks with unstructured projections.
Cross-domain Image Retrieval with a Dual Attribute-aware Ranking Network
May 29, 2015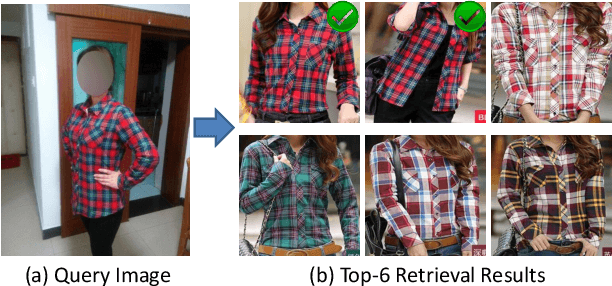
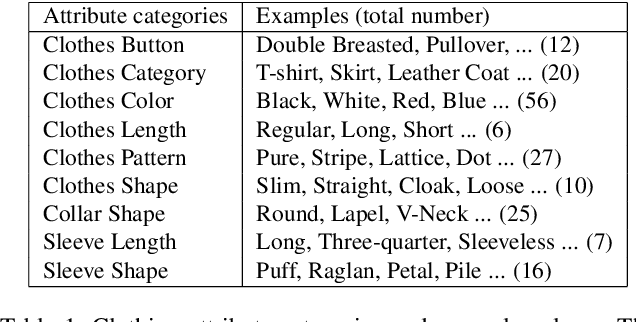

We address the problem of cross-domain image retrieval, considering the following practical application: given a user photo depicting a clothing image, our goal is to retrieve the same or attribute-similar clothing items from online shopping stores. This is a challenging problem due to the large discrepancy between online shopping images, usually taken in ideal lighting/pose/background conditions, and user photos captured in uncontrolled conditions. To address this problem, we propose a Dual Attribute-aware Ranking Network (DARN) for retrieval feature learning. More specifically, DARN consists of two sub-networks, one for each domain, whose retrieval feature representations are driven by semantic attribute learning. We show that this attribute-guided learning is a key factor for retrieval accuracy improvement. In addition, to further align with the nature of the retrieval problem, we impose a triplet visual similarity constraint for learning to rank across the two sub-networks. Another contribution of our work is a large-scale dataset which makes the network learning feasible. We exploit customer review websites to crawl a large set of online shopping images and corresponding offline user photos with fine-grained clothing attributes, i.e., around 450,000 online shopping images and about 90,000 exact offline counterpart images of those online ones. All these images are collected from real-world consumer websites reflecting the diversity of the data modality, which makes this dataset unique and rare in the academic community. We extensively evaluate the retrieval performance of networks in different configurations. The top-20 retrieval accuracy is doubled when using the proposed DARN other than the current popular solution using pre-trained CNN features only (0.570 vs. 0.268).
Face Verification in Polar Frequency Domain: a Biologically Motivated Approach
Sep 27, 2005
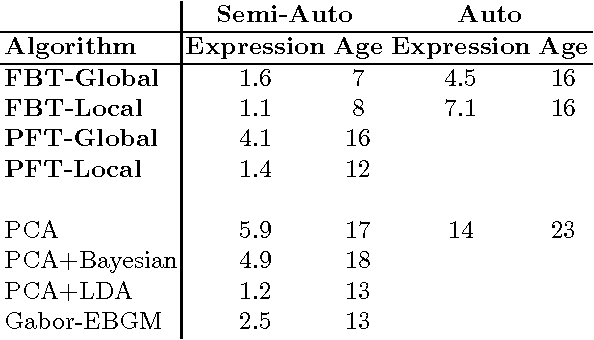
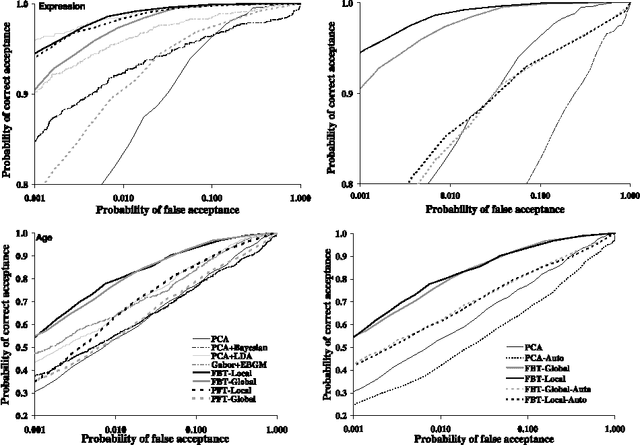
We present a novel local-based face verification system whose components are analogous to those of biological systems. In the proposed system, after global registration and normalization, three eye regions are converted from the spatial to polar frequency domain by a Fourier-Bessel Transform. The resulting representations are embedded in a dissimilarity space, where each image is represented by its distance to all the other images. In this dissimilarity space a Pseudo-Fisher discriminator is built. ROC and equal error rate verification test results on the FERET database showed that the system performed at least as state-of-the-art methods and better than a system based on polar Fourier features. The local-based system is especially robust to facial expression and age variations, but sensitive to registration errors.