 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigate One, Skew Another? Tackling Intersectional Biases in Text-to-Image Models
May 22, 2025The biases exhibited by text-to-image (TTI) models are often treated as independent, though in reality, they may be deeply interrelated. Addressing bias along one dimension - such as ethnicity or age - can inadvertently affect another, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. To address this, we introduce BiasConnect, a novel tool for analyzing and quantifying bias interactions in TTI models. BiasConnect uses counterfactual interventions along different bias axes to reveal the underlying structure of these interactions and estimates the effect of mitigating one bias axis on another. These estimates show strong correlation (+0.65) with observed post-mitigation outcomes. Building on BiasConnect, we propose InterMit, an intersectional bias mitigation algorithm guided by user-defined target distributions and priority weights. InterMit achieves lower bias (0.33 vs. 0.52) with fewer mitigation steps (2.38 vs. 3.15 average steps), and yields superior image quality compared to traditional techniques. Although our implementation is training-free, InterMit is modular and can be integrated with many existing debiasing approaches for TTI models, making it a flexible and extensible solution.
Utilizing Adversarial Examples for Bias Mitigation and Accuracy Enhancement
Apr 18, 2024

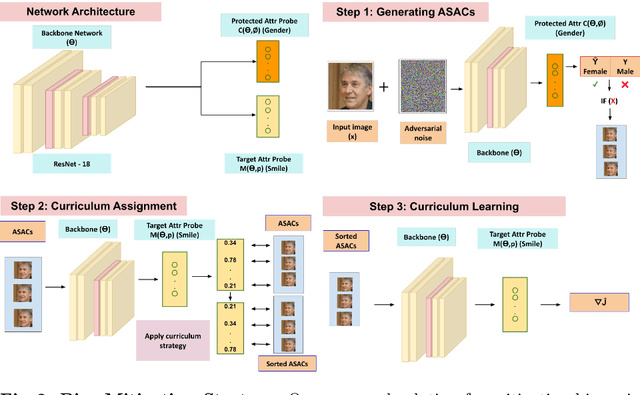

We propose a novel approach to mitigate biases in computer vision models by utilizing counterfactual generation and fine-tuning. While counterfactuals have been used to analyze and address biases in DNN models, the counterfactuals themselves are often generated from biased generative models, which can introduce additional biases or spurious correlations. To address this issue, we propose using adversarial images, that is images that deceive a deep neural network but not humans, as counterfactuals for fair model training. Our approach leverages a curriculum learning framework combined with a fine-grained adversarial loss to fine-tune the model using adversarial examples. By incorporating adversarial images into the training data, we aim to prevent biases from propagating through the pipeline. We validate our approach through both qualitative and quantitative assessments, demonstrating improved bias mitigation and accuracy compared to existing methods. Qualitatively, our results indicate that post-training, the decisions made by the model are less dependent on the sensitive attribute and our model better disentangles the relationship between sensitive attributes and classification variables.
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Dec 03, 2023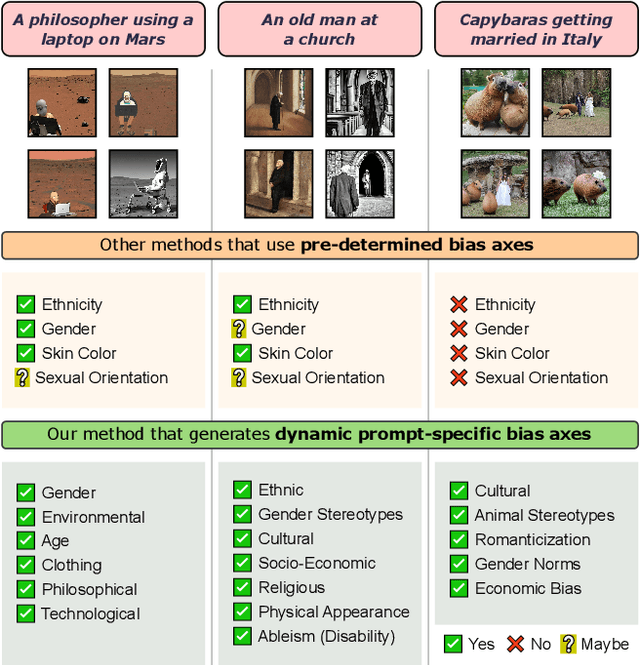

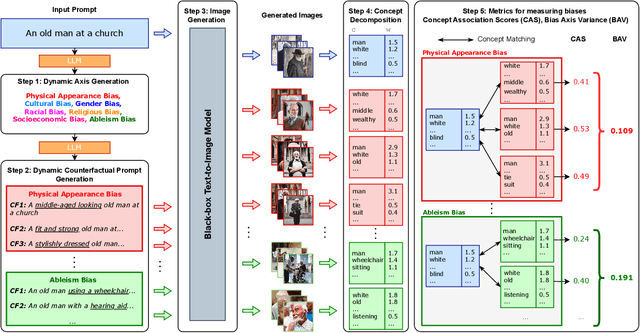
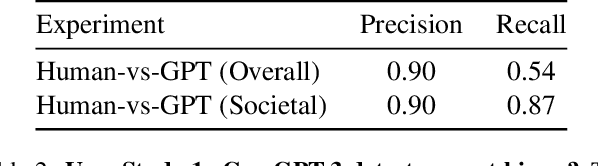
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, our paper extends quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
Sparse Fusion for Multimodal Transformers
Nov 24, 2021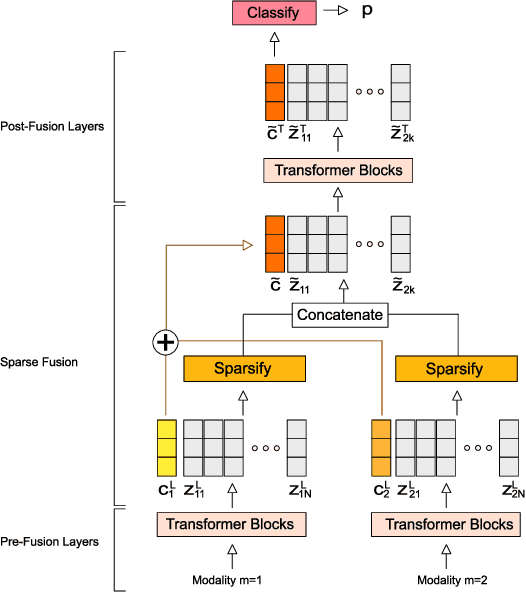
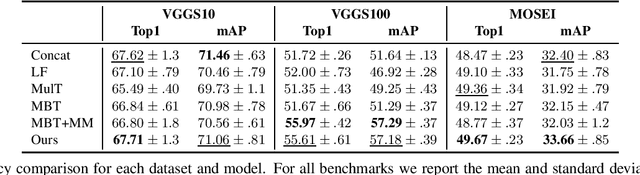
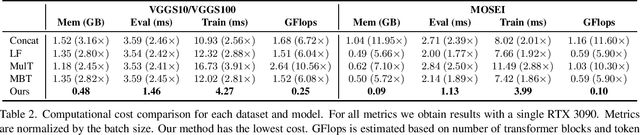
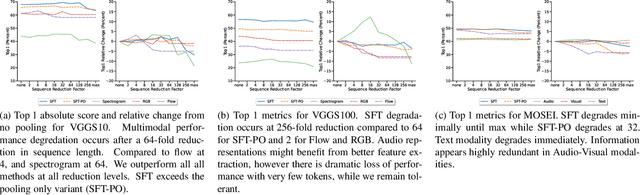
Multimodal classification is a core task in human-centric machine learning. We observe that information is highly complementary across modalities, thus unimodal information can be drastically sparsified prior to multimodal fusion without loss of accuracy. To this end, we present Sparse Fusion Transformers (SFT), a novel multimodal fusion method for transformers that performs comparably to existing state-of-the-art methods while having greatly reduced memory footprint and computation cost. Key to our idea is a sparse-pooling block that reduces unimodal token sets prior to cross-modality modeling. Evaluations are conducted on multiple multimodal benchmark datasets for a wide range of classification tasks. State-of-the-art performance is obtained on multiple benchmarks under similar experiment conditions, while reporting up to six-fold reduction in computational cost and memory requirements. Extensive ablation studies showcase our benefits of combining sparsification and multimodal learning over naive approaches. This paves the way for enabling multimodal learning on low-resource devices.
One-Class Meta-Learning: Towards Generalizable Few-Shot Open-Set Classification
Sep 14, 2021
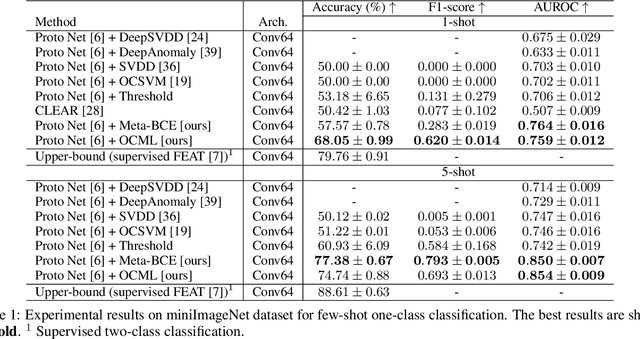


Real-world classification tasks are frequently required to work in an open-set setting. This is especially challenging for few-shot learning problems due to the small sample size for each known category, which prevents existing open-set methods from working effectively; however, most multiclass few-shot methods are limited to closed-set scenarios. In this work, we address the problem of few-shot open-set classification by first proposing methods for few-shot one-class classification and then extending them to few-shot multiclass open-set classification. We introduce two independent few-shot one-class classification methods: Meta Binary Cross-Entropy (Meta-BCE), which learns a separate feature representation for one-class classification, and One-Class Meta-Learning (OCML), which learns to generate one-class classifiers given standard multiclass feature representation. Both methods can augment any existing few-shot learning method without requiring retraining to work in a few-shot multiclass open-set setting without degrading its closed-set performance. We demonstrate the benefits and drawbacks of both methods in different problem settings and evaluate them on three standard benchmark datasets, miniImageNet, tieredImageNet, and Caltech-UCSD-Birds-200-2011, where they surpass the state-of-the-art methods in the few-shot multiclass open-set and few-shot one-class tasks.
What Should I Ask? Using Conversationally Informative Rewards for Goal-Oriented Visual Dialog
Jul 28, 2019
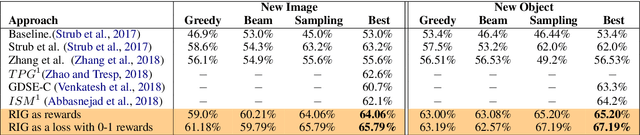
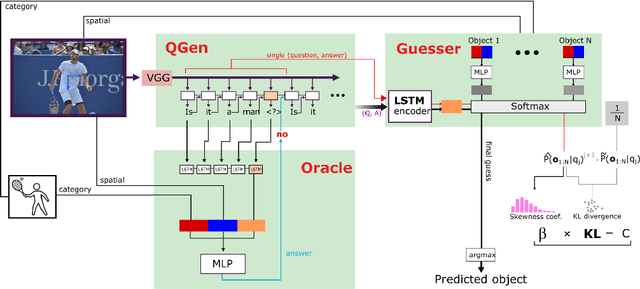
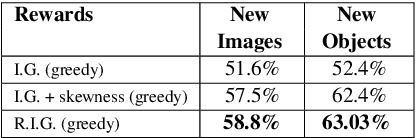
The ability to engage in goal-oriented conversations has allowed humans to gain knowledge, reduce uncertainty, and perform tasks more efficiently. Artificial agents, however, are still far behind humans in having goal-driven conversations. In this work, we focus on the task of goal-oriented visual dialogue, aiming to automatically generate a series of questions about an image with a single objective. This task is challenging since these questions must not only be consistent with a strategy to achieve a goal, but also consider the contextual information in the image. We propose an end-to-end goal-oriented visual dialogue system, that combines reinforcement learning with regularized information gain. Unlike previous approaches that have been proposed for the task, our work is motivated by the Rational Speech Act framework, which models the process of human inquiry to reach a goal. We test the two versions of our model on the GuessWhat?! dataset, obtaining significant results that outperform the current state-of-the-art models in the task of generating questions to find an undisclosed object in an image.
ANSAC: Adaptive Non-minimal Sample and Consensus
Sep 27, 2017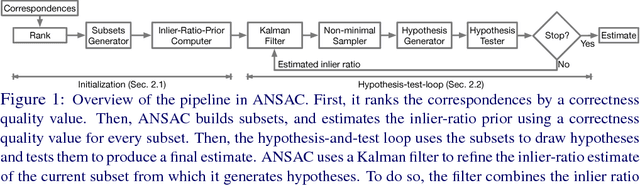



While RANSAC-based methods are robust to incorrect image correspondences (outliers), their hypothesis generators are not robust to correct image correspondences (inliers) with positional error (noise). This slows down their convergence because hypotheses drawn from a minimal set of noisy inliers can deviate significantly from the optimal model. This work addresses this problem by introducing ANSAC, a RANSAC-based estimator that accounts for noise by adaptively using more than the minimal number of correspondences required to generate a hypothesis. ANSAC estimates the inlier ratio (the fraction of correct correspondences) of several ranked subsets of candidate correspondences and generates hypotheses from them. Its hypothesis-generation mechanism prioritizes the use of subsets with high inlier ratio to generate high-quality hypotheses. ANSAC uses an early termination criterion that keeps track of the inlier ratio history and terminates when it has not changed significantly for a period of time. The experiments show that ANSAC finds good homography and fundamental matrix estimates in a few iterations, consistently outperforming state-of-the-art methods.
Data-Intensive Supercomputing in the Cloud: Global Analytics for Satellite Imagery
Feb 13, 2017
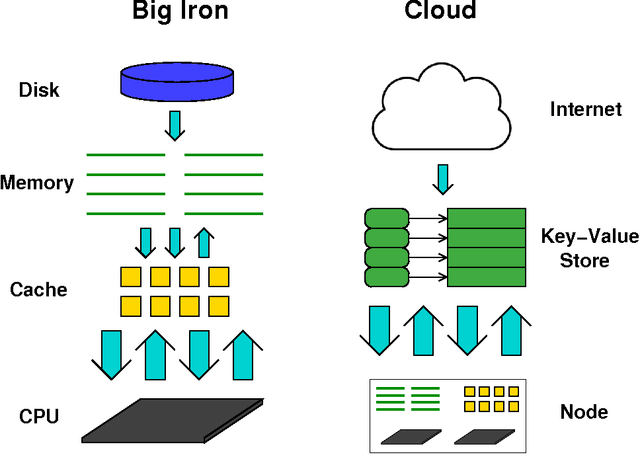
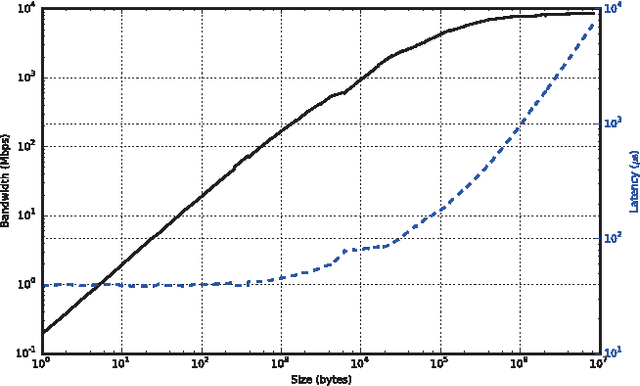

We present our experiences using cloud computing to support data-intensive analytics on satellite imagery for commercial applications. Drawing from our background in high-performance computing, we draw parallels between the early days of clustered computing systems and the current state of cloud computing and its potential to disrupt the HPC market. Using our own virtual file system layer on top of cloud remote object storage, we demonstrate aggregate read bandwidth of 230 gigabytes per second using 512 Google Compute Engine (GCE) nodes accessing a USA multi-region standard storage bucket. This figure is comparable to the best HPC storage systems in existence. We also present several of our application results, including the identification of field boundaries in Ukraine, and the generation of a global cloud-free base layer from Landsat imagery.
* 8 pages, 9 figures. Copyright 2016 IEEE. DataCloud 2016: The Seventh International Workshop on Data-Intensive Computing in the Clouds. In conjunction with SC16. Salt Lake City, Utah
Large Scale SfM with the Distributed Camera Model
Dec 01, 2016

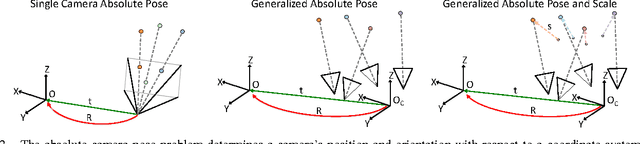

We introduce the distributed camera model, a novel model for Structure-from-Motion (SfM). This model describes image observations in terms of light rays with ray origins and directions rather than pixels. As such, the proposed model is capable of describing a single camera or multiple cameras simultaneously as the collection of all light rays observed. We show how the distributed camera model is a generalization of the standard camera model and describe a general formulation and solution to the absolute camera pose problem that works for standard or distributed cameras. The proposed method computes a solution that is up to 8 times more efficient and robust to rotation singularities in comparison with gDLS. Finally, this method is used in an novel large-scale incremental SfM pipeline where distributed cameras are accurately and robustly merged together. This pipeline is a direct generalization of traditional incremental SfM; however, instead of incrementally adding one camera at a time to grow the reconstruction the reconstruction is grown by adding a distributed camera. Our pipeline produces highly accurate reconstructions efficiently by avoiding the need for many bundle adjustment iterations and is capable of computing a 3D model of Rome from over 15,000 images in just 22 minutes.
One-Class Slab Support Vector Machine
Aug 02, 2016
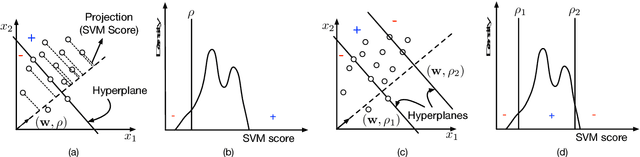
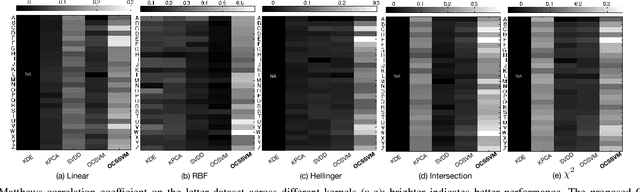

This work introduces the one-class slab SVM (OCSSVM), a one-class classifier that aims at improving the performance of the one-class SVM. The proposed strategy reduces the false positive rate and increases the accuracy of detecting instances from novel classes. To this end, it uses two parallel hyperplanes to learn the normal region of the decision scores of the target class. OCSSVM extends one-class SVM since it can scale and learn non-linear decision functions via kernel methods. The experiments on two publicly available datasets show that OCSSVM can consistently outperform the one-class SVM and perform comparable to or better than other state-of-the-art one-class classifiers.