 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Aware Model Adaptation via Feedback-Guided Optimization
Feb 02, 2026Fine-tuning is the primary mechanism for adapting foundation models to downstream tasks; however, standard approaches largely optimize task objectives in isolation and do not account for secondary yet critical alignment objectives (e.g., safety and hallucination avoidance). As a result, downstream fine-tuning can degrade alignment and fail to correct pre-existing misaligned behavior. We propose an alignment-aware fine-tuning framework that integrates feedback from an external alignment signal through policy-gradient-based regularization. Our method introduces an adaptive gating mechanism that dynamically balances supervised and alignment-driven gradients on a per-sample basis, prioritizing uncertain or misaligned cases while allowing well-aligned examples to follow standard supervised updates. The framework further learns abstention behavior for fully misaligned inputs, incorporating conservative responses directly into the fine-tuned model. Experiments on general and domain-specific instruction-tuning benchmarks demonstrate consistent reductions in harmful and hallucinated outputs without sacrificing downstream task performance. Additional analyses show robustness to adversarial fine-tuning, prompt-based attacks, and unsafe initializations, establishing adaptively gated alignment optimization as an effective approach for alignment-preserving and alignment-recovering model adaptation.
RewardRank: Optimizing True Learning-to-Rank Utility
Aug 19, 2025
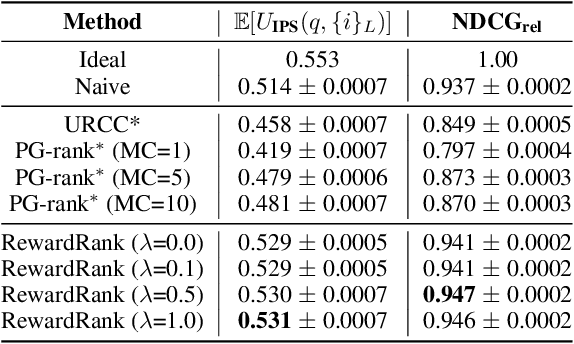
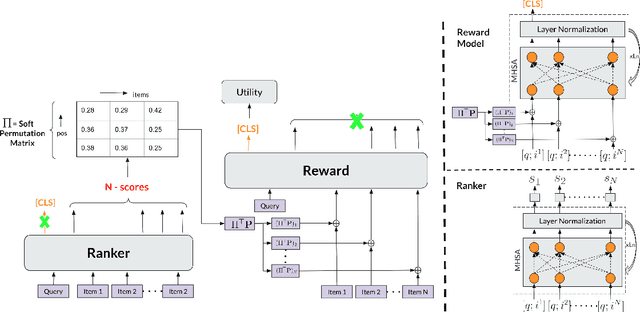
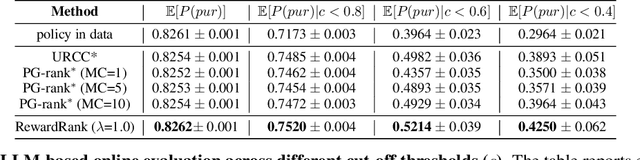
Traditional ranking systems rely on proxy loss functions that assume simplistic user behavior, such as users preferring a rank list where items are sorted by hand-crafted relevance. However, real-world user interactions are influenced by complex behavioral biases, including position bias, brand affinity, decoy effects, and similarity aversion, which these objectives fail to capture. As a result, models trained on such losses often misalign with actual user utility, such as the probability of any click or purchase across the ranked list. In this work, we propose a data-driven framework for modeling user behavior through counterfactual reward learning. Our method, RewardRank, first trains a deep utility model to estimate user engagement for entire item permutations using logged data. Then, a ranking policy is optimized to maximize predicted utility via differentiable soft permutation operators, enabling end-to-end training over the space of factual and counterfactual rankings. To address the challenge of evaluation without ground-truth for unseen permutations, we introduce two automated protocols: (i) $\textit{KD-Eval}$, using a position-aware oracle for counterfactual reward estimation, and (ii) $\textit{LLM-Eval}$, which simulates user preferences via large language models. Experiments on large-scale benchmarks, including Baidu-ULTR and the Amazon KDD Cup datasets, demonstrate that our approach consistently outperforms strong baselines, highlighting the effectiveness of modeling user behavior dynamics for utility-optimized ranking. Our code is available at: https://github.com/GauravBh1010tt/RewardRank
Preventing Catastrophic Forgetting through Memory Networks in Continuous Detection
Mar 21, 2024Modern pre-trained architectures struggle to retain previous information while undergoing continuous fine-tuning on new tasks. Despite notable progress in continual classification, systems designed for complex vision tasks such as detection or segmentation still struggle to attain satisfactory performance. In this work, we introduce a memory-based detection transformer architecture to adapt a pre-trained DETR-style detector to new tasks while preserving knowledge from previous tasks. We propose a novel localized query function for efficient information retrieval from memory units, aiming to minimize forgetting. Furthermore, we identify a fundamental challenge in continual detection referred to as background relegation. This arises when object categories from earlier tasks reappear in future tasks, potentially without labels, leading them to be implicitly treated as background. This is an inevitable issue in continual detection or segmentation. The introduced continual optimization technique effectively tackles this challenge. Finally, we assess the performance of our proposed system on continual detection benchmarks and demonstrate that our approach surpasses the performance of existing state-of-the-art resulting in 5-7% improvements on MS-COCO and PASCAL-VOC on the task of continual detection.
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Dec 03, 2023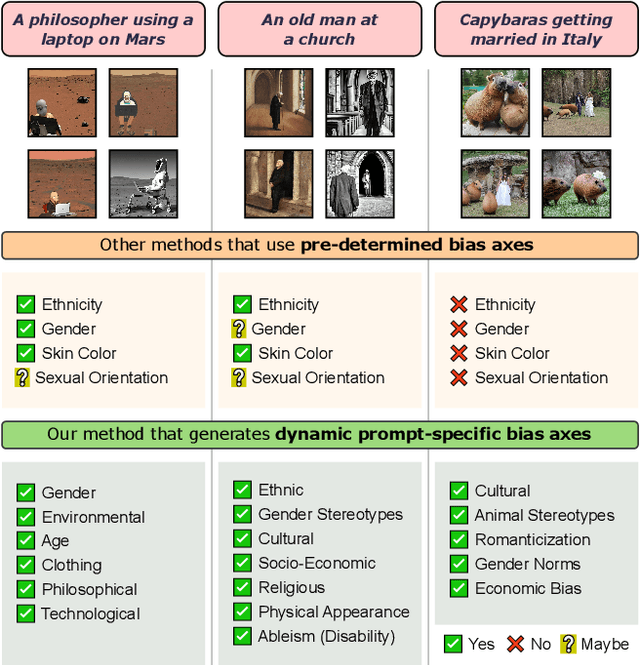

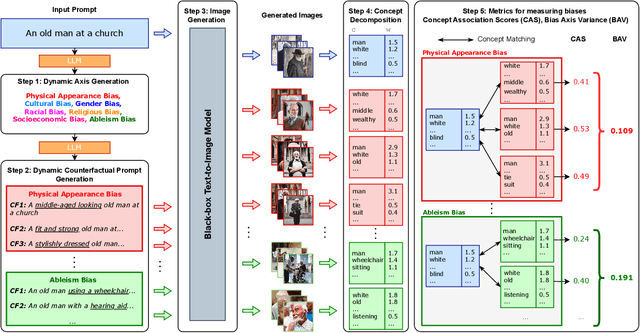
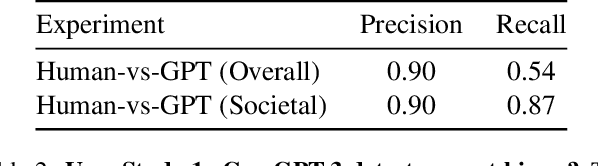
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, our paper extends quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
Mitigating the Effect of Incidental Correlations on Part-based Learning
Sep 30, 2023



Intelligent systems possess a crucial characteristic of breaking complicated problems into smaller reusable components or parts and adjusting to new tasks using these part representations. However, current part-learners encounter difficulties in dealing with incidental correlations resulting from the limited observations of objects that may appear only in specific arrangements or with specific backgrounds. These incidental correlations may have a detrimental impact on the generalization and interpretability of learned part representations. This study asserts that part-based representations could be more interpretable and generalize better with limited data, employing two innovative regularization methods. The first regularization separates foreground and background information's generative process via a unique mixture-of-parts formulation. Structural constraints are imposed on the parts using a weakly-supervised loss, guaranteeing that the mixture-of-parts for foreground and background entails soft, object-agnostic masks. The second regularization assumes the form of a distillation loss, ensuring the invariance of the learned parts to the incidental background correlations. Furthermore, we incorporate sparse and orthogonal constraints to facilitate learning high-quality part representations. By reducing the impact of incidental background correlations on the learned parts, we exhibit state-of-the-art (SoTA) performance on few-shot learning tasks on benchmark datasets, including MiniImagenet, TieredImageNet, and FC100. We also demonstrate that the part-based representations acquired through our approach generalize better than existing techniques, even under domain shifts of the background and common data corruption on the ImageNet-9 dataset. The implementation is available on GitHub: https://github.com/GauravBh1010tt/DPViT.git
Learn from Anywhere: Rethinking Generalized Zero-Shot Learning with Limited Supervision
Jul 14, 2021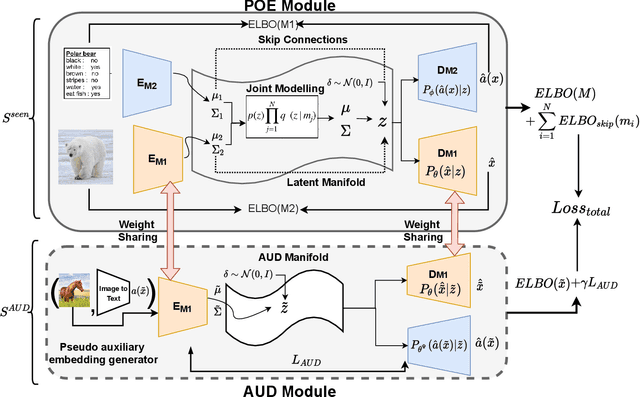

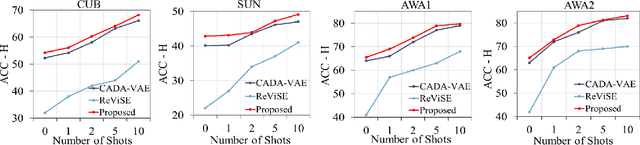

A common problem with most zero and few-shot learning approaches is they suffer from bias towards seen classes resulting in sub-optimal performance. Existing efforts aim to utilize unlabeled images from unseen classes (i.e transductive zero-shot) during training to enable generalization. However, this limits their use in practical scenarios where data from target unseen classes is unavailable or infeasible to collect. In this work, we present a practical setting of inductive zero and few-shot learning, where unlabeled images from other out-of-data classes, that do not belong to seen or unseen categories, can be used to improve generalization in any-shot learning. We leverage a formulation based on product-of-experts and introduce a new AUD module that enables us to use unlabeled samples from out-of-data classes which are usually easily available and practically entail no annotation cost. In addition, we also demonstrate the applicability of our model to address a more practical and challenging, Generalized Zero-shot under a limited supervision setting, where even base seen classes do not have sufficient annotated samples.
Attentive Recurrent Tensor Model for Community Question Answering
Jan 21, 2018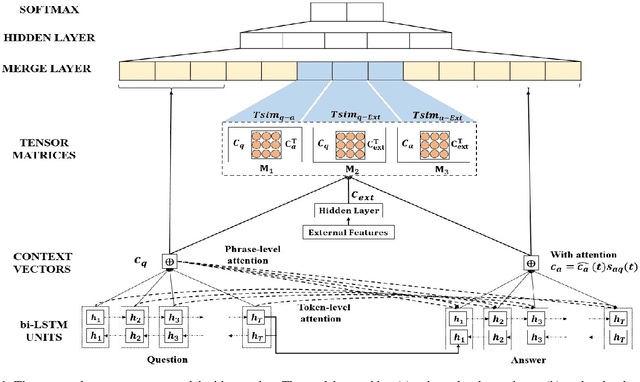
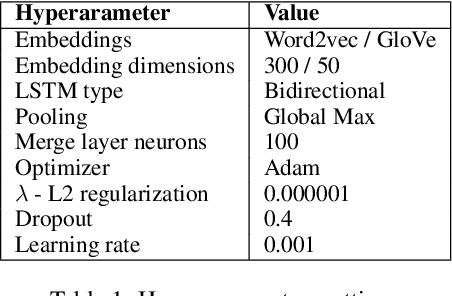
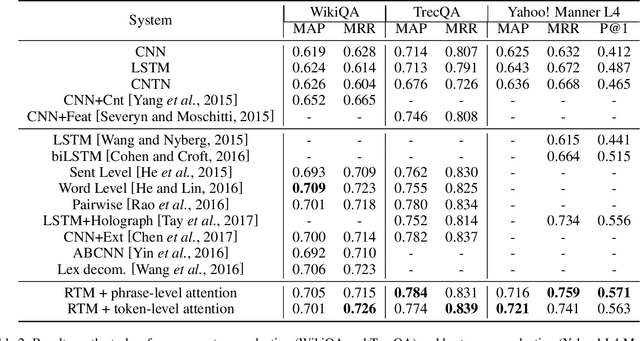
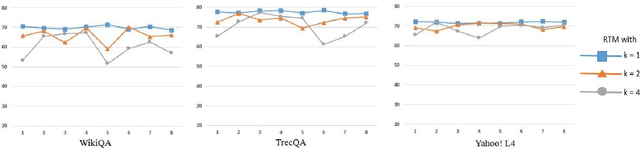
A major challenge to the problem of community question answering is the lexical and semantic gap between the sentence representations. Some solutions to minimize this gap includes the introduction of extra parameters to deep models or augmenting the external handcrafted features. In this paper, we propose a novel attentive recurrent tensor network for solving the lexical and semantic gap in community question answering. We introduce token-level and phrase-level attention strategy that maps input sequences to the output using trainable parameters. Further, we use the tensor parameters to introduce a 3-way interaction between question, answer and external features in vector space. We introduce simplified tensor matrices with L2 regularization that results in smooth optimization during training. The proposed model achieves state-of-the-art performance on the task of answer sentence selection (TrecQA and WikiQA datasets) while outperforming the current state-of-the-art on the tasks of best answer selection (Yahoo! L4) and answer triggering task (WikiQA).
On the Benefit of Combining Neural, Statistical and External Features for Fake News Identification
Dec 11, 2017
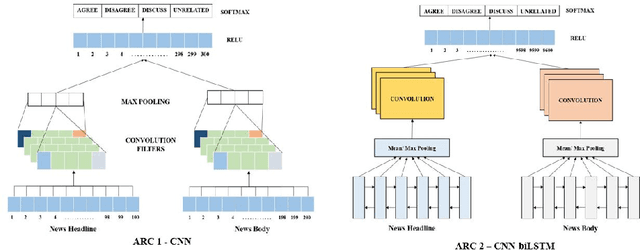
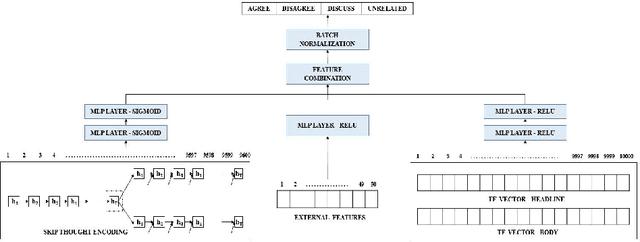

Identifying the veracity of a news article is an interesting problem while automating this process can be a challenging task. Detection of a news article as fake is still an open question as it is contingent on many factors which the current state-of-the-art models fail to incorporate. In this paper, we explore a subtask to fake news identification, and that is stance detection. Given a news article, the task is to determine the relevance of the body and its claim. We present a novel idea that combines the neural, statistical and external features to provide an efficient solution to this problem. We compute the neural embedding from the deep recurrent model, statistical features from the weighted n-gram bag-of-words model and handcrafted external features with the help of feature engineering heuristics. Finally, using deep neural layer all the features are combined, thereby classifying the headline-body news pair as agree, disagree, discuss, or unrelated. We compare our proposed technique with the current state-of-the-art models on the fake news challenge dataset. Through extensive experiments, we find that the proposed model outperforms all the state-of-the-art techniques including the submissions to the fake news challenge.
Common Representation Learning Using Step-based Correlation Multi-Modal CNN
Oct 31, 2017



Deep learning techniques have been successfully used in learning a common representation for multi-view data, wherein the different modalities are projected onto a common subspace. In a broader perspective, the techniques used to investigate common representation learning falls under the categories of canonical correlation-based approaches and autoencoder based approaches. In this paper, we investigate the performance of deep autoencoder based methods on multi-view data. We propose a novel step-based correlation multi-modal CNN (CorrMCNN) which reconstructs one view of the data given the other while increasing the interaction between the representations at each hidden layer or every intermediate step. Finally, we evaluate the performance of the proposed model on two benchmark datasets - MNIST and XRMB. Through extensive experiments, we find that the proposed model achieves better performance than the current state-of-the-art techniques on joint common representation learning and transfer learning tasks.