 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePustakAI: Curriculum-Aligned and Interactive Textbooks Using Large Language Models
Nov 14, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and generating human-like content. This has revolutionized various sectors such as healthcare, software development, and education. In education, LLMs offer potential for personalized and interactive learning experiences, especially in regions with limited teaching resources. However, adapting these models effectively to curriculum-specific content, such as the National Council of Educational Research and Training (NCERT) syllabus in India, presents unique challenges in terms of accuracy, alignment, and pedagogical relevance. In this paper, we present the framework "PustakAI"\footnote{Pustak means `book' in many Indian languages.} for the design and evaluation of a novel question-answering dataset "NCERT-QA" aligned with the NCERT curriculum for English and Science subjects of grades 6 to 8. We classify the curated QA pairs as Factoid, Inferential, and Others (evaluative and reasoning). We evaluate the dataset with various prompting techniques, such as meta-prompt, few-shot, and CoT-style prompting, using diverse evaluation metrics to understand which approach aligns more efficiently with the structure and demands of the curriculum. Along with the usability of the dataset, we analyze the strengths and limitations of current open-source LLMs (Gemma3:1b, Llama3.2:3b, and Nemotron-mini:4b) and high-end LLMs (Llama-4-Scout-17B and Deepseek-r1-70B) as AI-based learning tools in formal education systems.
Toward Quantum Utility in Finance: A Robust Data-Driven Algorithm for Asset Clustering
Sep 09, 2025Clustering financial assets based on return correlations is a fundamental task in portfolio optimization and statistical arbitrage. However, classical clustering methods often fall short when dealing with signed correlation structures, typically requiring lossy transformations and heuristic assumptions such as a fixed number of clusters. In this work, we apply the Graph-based Coalition Structure Generation algorithm (GCS-Q) to directly cluster signed, weighted graphs without relying on such transformations. GCS-Q formulates each partitioning step as a QUBO problem, enabling it to leverage quantum annealing for efficient exploration of exponentially large solution spaces. We validate our approach on both synthetic and real-world financial data, benchmarking against state-of-the-art classical algorithms such as SPONGE and k-Medoids. Our experiments demonstrate that GCS-Q consistently achieves higher clustering quality, as measured by Adjusted Rand Index and structural balance penalties, while dynamically determining the number of clusters. These results highlight the practical utility of near-term quantum computing for graph-based unsupervised learning in financial applications.
Entity Framing and Role Portrayal in the News
Feb 20, 2025



We introduce a novel multilingual hierarchical corpus annotated for entity framing and role portrayal in news articles. The dataset uses a unique taxonomy inspired by storytelling elements, comprising 22 fine-grained roles, or archetypes, nested within three main categories: protagonist, antagonist, and innocent. Each archetype is carefully defined, capturing nuanced portrayals of entities such as guardian, martyr, and underdog for protagonists; tyrant, deceiver, and bigot for antagonists; and victim, scapegoat, and exploited for innocents. The dataset includes 1,378 recent news articles in five languages (Bulgarian, English, Hindi, European Portuguese, and Russian) focusing on two critical domains of global significance: the Ukraine-Russia War and Climate Change. Over 5,800 entity mentions have been annotated with role labels. This dataset serves as a valuable resource for research into role portrayal and has broader implications for news analysis. We describe the characteristics of the dataset and the annotation process, and we report evaluation results on fine-tuned state-of-the-art multilingual transformers and hierarchical zero-shot learning using LLMs at the level of a document, a paragraph, and a sentence.
SAFE-MEME: Structured Reasoning Framework for Robust Hate Speech Detection in Memes
Dec 29, 2024



Memes act as cryptic tools for sharing sensitive ideas, often requiring contextual knowledge to interpret. This makes moderating multimodal memes challenging, as existing works either lack high-quality datasets on nuanced hate categories or rely on low-quality social media visuals. Here, we curate two novel multimodal hate speech datasets, MHS and MHS-Con, that capture fine-grained hateful abstractions in regular and confounding scenarios, respectively. We benchmark these datasets against several competing baselines. Furthermore, we introduce SAFE-MEME (Structured reAsoning FramEwork), a novel multimodal Chain-of-Thought-based framework employing Q&A-style reasoning (SAFE-MEME-QA) and hierarchical categorization (SAFE-MEME-H) to enable robust hate speech detection in memes. SAFE-MEME-QA outperforms existing baselines, achieving an average improvement of approximately 5% and 4% on MHS and MHS-Con, respectively. In comparison, SAFE-MEME-H achieves an average improvement of 6% in MHS while outperforming only multimodal baselines in MHS-Con. We show that fine-tuning a single-layer adapter within SAFE-MEME-H outperforms fully fine-tuned models in regular fine-grained hateful meme detection. However, the fully fine-tuning approach with a Q&A setup is more effective for handling confounding cases. We also systematically examine the error cases, offering valuable insights into the robustness and limitations of the proposed structured reasoning framework for analyzing hateful memes.
Exploring the Benefits of Domain-Pretraining of Generative Large Language Models for Chemistry
Nov 05, 2024
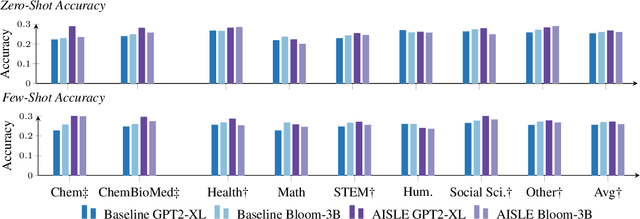
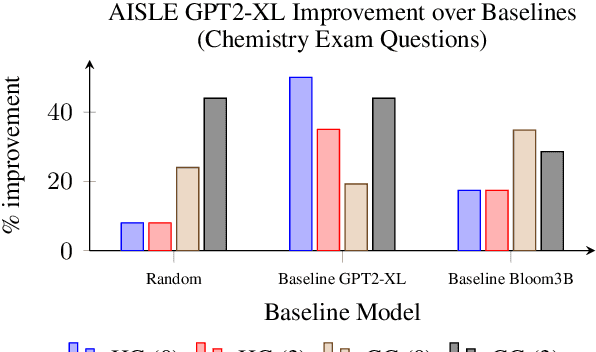
A proliferation of Large Language Models (the GPT series, BLOOM, LLaMA, and more) are driving forward novel development of multipurpose AI for a variety of tasks, particularly natural language processing (NLP) tasks. These models demonstrate strong performance on a range of tasks; however, there has been evidence of brittleness when applied to more niche or narrow domains where hallucinations or fluent but incorrect responses reduce performance. Given the complex nature of scientific domains, it is prudent to investigate the trade-offs of leveraging off-the-shelf versus more targeted foundation models for scientific domains. In this work, we examine the benefits of in-domain pre-training for a given scientific domain, chemistry, and compare these to open-source, off-the-shelf models with zero-shot and few-shot prompting. Our results show that not only do in-domain base models perform reasonably well on in-domain tasks in a zero-shot setting but that further adaptation using instruction fine-tuning yields impressive performance on chemistry-specific tasks such as named entity recognition and molecular formula generation.
RAG vs. Long Context: Examining Frontier Large Language Models for Environmental Review Document Comprehension
Jul 10, 2024



Large Language Models (LLMs) have been applied to many research problems across various domains. One of the applications of LLMs is providing question-answering systems that cater to users from different fields. The effectiveness of LLM-based question-answering systems has already been established at an acceptable level for users posing questions in popular and public domains such as trivia and literature. However, it has not often been established in niche domains that traditionally require specialized expertise. To this end, we construct the NEPAQuAD1.0 benchmark to evaluate the performance of three frontier LLMs -- Claude Sonnet, Gemini, and GPT-4 -- when answering questions originating from Environmental Impact Statements prepared by U.S. federal government agencies in accordance with the National Environmental Environmental Act (NEPA). We specifically measure the ability of LLMs to understand the nuances of legal, technical, and compliance-related information present in NEPA documents in different contextual scenarios. For example, we test the LLMs' internal prior NEPA knowledge by providing questions without any context, as well as assess how LLMs synthesize the contextual information present in long NEPA documents to facilitate the question/answering task. We compare the performance of the long context LLMs and RAG powered models in handling different types of questions (e.g., problem-solving, divergent). Our results suggest that RAG powered models significantly outperform the long context models in the answer accuracy regardless of the choice of the frontier LLM. Our further analysis reveals that many models perform better answering closed questions than divergent and problem-solving questions.
MemeMQA: Multimodal Question Answering for Memes via Rationale-Based Inferencing
May 18, 2024

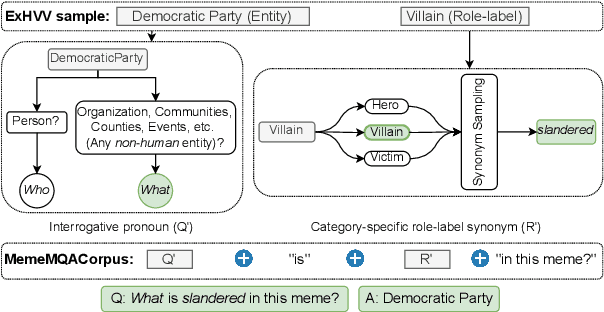
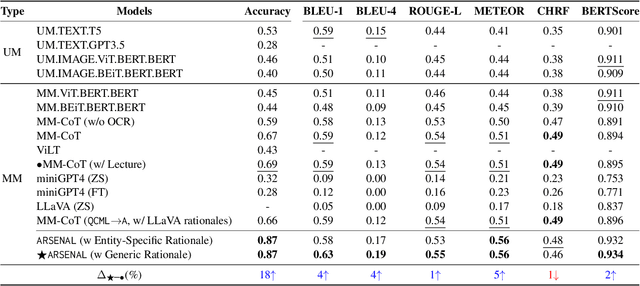
Memes have evolved as a prevalent medium for diverse communication, ranging from humour to propaganda. With the rising popularity of image-focused content, there is a growing need to explore its potential harm from different aspects. Previous studies have analyzed memes in closed settings - detecting harm, applying semantic labels, and offering natural language explanations. To extend this research, we introduce MemeMQA, a multimodal question-answering framework aiming to solicit accurate responses to structured questions while providing coherent explanations. We curate MemeMQACorpus, a new dataset featuring 1,880 questions related to 1,122 memes with corresponding answer-explanation pairs. We further propose ARSENAL, a novel two-stage multimodal framework that leverages the reasoning capabilities of LLMs to address MemeMQA. We benchmark MemeMQA using competitive baselines and demonstrate its superiority - ~18% enhanced answer prediction accuracy and distinct text generation lead across various metrics measuring lexical and semantic alignment over the best baseline. We analyze ARSENAL's robustness through diversification of question-set, confounder-based evaluation regarding MemeMQA's generalizability, and modality-specific assessment, enhancing our understanding of meme interpretation in the multimodal communication landscape.
Recent Advances in Hate Speech Moderation: Multimodality and the Role of Large Models
Feb 02, 2024


In the evolving landscape of online communication, moderating hate speech (HS) presents an intricate challenge, compounded by the multimodal nature of digital content. This comprehensive survey delves into the recent strides in HS moderation, spotlighting the burgeoning role of large language models (LLMs) and large multimodal models (LMMs). Our exploration begins with a thorough analysis of current literature, revealing the nuanced interplay between textual, visual, and auditory elements in propagating HS. We uncover a notable trend towards integrating these modalities, primarily due to the complexity and subtlety with which HS is disseminated. A significant emphasis is placed on the advances facilitated by LLMs and LMMs, which have begun to redefine the boundaries of detection and moderation capabilities. We identify existing gaps in research, particularly in the context of underrepresented languages and cultures, and the need for solutions to handle low-resource settings. The survey concludes with a forward-looking perspective, outlining potential avenues for future research, including the exploration of novel AI methodologies, the ethical governance of AI in moderation, and the development of more nuanced, context-aware systems. This comprehensive overview aims to catalyze further research and foster a collaborative effort towards more sophisticated, responsible, and human-centric approaches to HS moderation in the digital era. WARNING: This paper contains offensive examples.
Factuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
Data-efficient Deep Learning Approach for Single-Channel EEG-Based Sleep Stage Classification with Model Interpretability
Sep 28, 2023



Sleep, a fundamental physiological process, occupies a significant portion of our lives. Accurate classification of sleep stages serves as a crucial tool for evaluating sleep quality and identifying probable sleep disorders. Our work introduces a novel methodology that utilizes a SE-Resnet-Bi-LSTM architecture to classify sleep into five separate stages. The classification process is based on the analysis of single-channel electroencephalograms (EEGs). The suggested framework consists of two fundamental elements: a feature extractor that utilizes SE-ResNet, and a temporal context encoder that uses stacks of Bi-LSTM units. The effectiveness of our approach is substantiated by thorough assessments conducted on three different datasets, namely SleepEDF-20, SleepEDF-78, and SHHS. The proposed methodology achieves significant model performance, with Macro-F1 scores of 82.5, 78.9, and 81.9 for the respective datasets. We employ 1D-GradCAM visualization as a methodology to elucidate the decision-making process inherent in our model in the realm of sleep stage classification. This visualization method not only provides valuable insights into the model's classification rationale but also aligns its outcomes with the annotations made by sleep experts. One notable feature of our research lies in the incorporation of an efficient training approach, which adeptly upholds the model's resilience in terms of performance. The experimental evaluations provide a comprehensive evaluation of the effectiveness of our proposed model in comparison to the existing approaches, highlighting its potential for practical applications.