 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCICONVBENCH: Benchmarking LLMs on Multi-Turn Clarification for Task Formulation in Computational Science
May 18, 2026Large Language Models (LLMs) are increasingly deployed as scientific AI as- sistants, and a growing body of benchmarks evaluates their capabilities across knowledge retrieval, reasoning, code generation, and tool use. These evaluations, however, typically assume the scientific problem is already well-posed, whereas practical scientific assistance often begins with an ill-posed user request that must be refined through dialogue before any computation, analysis, or experiment can be carried out reliably. We introduce SCICONVBENCH, a benchmark for multi- turn clarification in scientific task formulation across four computational science problem domains: fluid mechanics, solid mechanics, materials science, and par- tial differential equations (PDEs). SCICONVBENCH targets two complementary capabilities: eliciting missing information (disambiguation) and detecting and correcting erroneous requests containing internally contradictory information (in- consistency resolution). Our benchmark pairs a structured task ontology with a rubric-based evaluation framework, enabling systematic measurement of LLM per- formance across three dimensions: clarification behavior, conversational grounding, and final-specification fidelity. Current frontier models perform relatively well on inconsistency resolution, but even the best model resolves only 52.7% of the disambiguation cases in fluid mechanics. We further find that frontier LLMs fre- quently make silent assumptions and perform implicit specification repairs that are not grounded in the conversation with users. SCICONVBENCH establishes a foundation for evaluating the upstream conversational reasoning that a reliable computational science assistant requires. The code and data can be found at https://github.com/csml-rpi/SciConvBench.
A Cloud-based Multi-Agentic Workflow for Science
Jan 18, 2026As Large Language Models (LLMs) become ubiquitous across various scientific domains, their lack of ability to perform complex tasks like running simulations or to make complex decisions limits their utility. LLM-based agents bridge this gap due to their ability to call external resources and tools and thus are now rapidly gaining popularity. However, coming up with a workflow that can balance the models, cloud providers, and external resources is very challenging, making implementing an agentic system more of a hindrance than a help. In this work, we present a domain-agnostic, model-independent workflow for an agentic framework that can act as a scientific assistant while being run entirely on cloud. Built with a supervisor agent marshaling an array of agents with individual capabilities, our framework brings together straightforward tasks like literature review and data analysis with more complex ones like simulation runs. We describe the framework here in full, including a proof-of-concept system we built to accelerate the study of Catalysts, which is highly important in the field of Chemistry and Material Science. We report the cost to operate and use this framework, including the breakdown of the cost by services use. We also evaluate our system on a custom-curated synthetic benchmark and a popular Chemistry benchmark, and also perform expert validation of the system. The results show that our system is able to route the task to the correct agent 90% of the time and successfully complete the assigned task 97.5% of the time for the synthetic tasks and 91% of the time for real-world tasks, while still achieving better or comparable accuracy to most frontier models, showing that this is a viable framework for other scientific domains to replicate.
DISHONEST: Dissecting misInformation Spread using Homogeneous sOcial NEtworks and Semantic Topic classification
Dec 12, 2024The emergence of the COVID-19 pandemic resulted in a significant rise in the spread of misinformation on online platforms such as Twitter. Oftentimes this growth is blamed on the idea of the "echo chamber." However, the behavior said to characterize these echo chambers exists in two dimensions. The first is in a user's social interactions, where they are said to stick with the same clique of like-minded users. The second is in the content of their posts, where they are said to repeatedly espouse homogeneous ideas. In this study, we link the two by using Twitter's network of retweets to study social interactions and topic modeling to study tweet content. In order to measure the diversity of a user's interactions over time, we develop a novel metric to track the speed at which they travel through the social network. The application of these analysis methods to misinformation-focused data from the pandemic demonstrates correlation between social behavior and tweet content. We believe this correlation supports the common intuition about how antisocial users behave, and further suggests that it holds even in subcommunities already rife with misinformation.
Exploring the Benefits of Domain-Pretraining of Generative Large Language Models for Chemistry
Nov 05, 2024
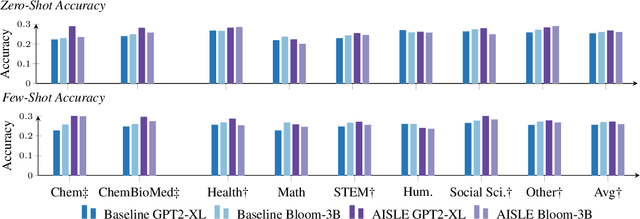
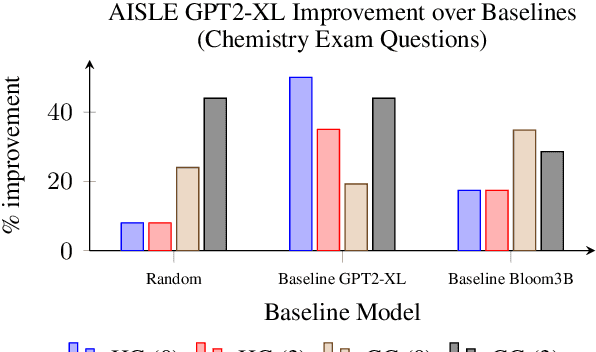
A proliferation of Large Language Models (the GPT series, BLOOM, LLaMA, and more) are driving forward novel development of multipurpose AI for a variety of tasks, particularly natural language processing (NLP) tasks. These models demonstrate strong performance on a range of tasks; however, there has been evidence of brittleness when applied to more niche or narrow domains where hallucinations or fluent but incorrect responses reduce performance. Given the complex nature of scientific domains, it is prudent to investigate the trade-offs of leveraging off-the-shelf versus more targeted foundation models for scientific domains. In this work, we examine the benefits of in-domain pre-training for a given scientific domain, chemistry, and compare these to open-source, off-the-shelf models with zero-shot and few-shot prompting. Our results show that not only do in-domain base models perform reasonably well on in-domain tasks in a zero-shot setting but that further adaptation using instruction fine-tuning yields impressive performance on chemistry-specific tasks such as named entity recognition and molecular formula generation.
PermitQA: A Benchmark for Retrieval Augmented Generation in Wind Siting and Permitting domain
Aug 21, 2024

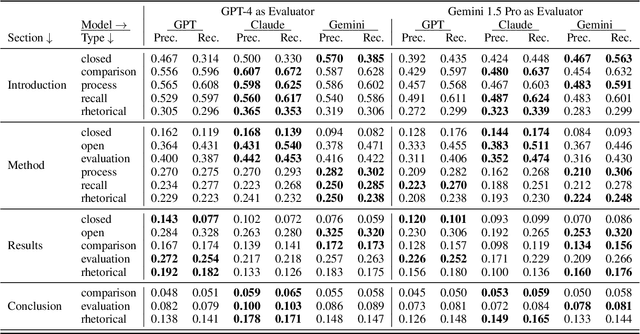
In the rapidly evolving landscape of Natural Language Processing (NLP) and text generation, the emergence of Retrieval Augmented Generation (RAG) presents a promising avenue for improving the quality and reliability of generated text by leveraging information retrieved from user specified database. Benchmarking is essential to evaluate and compare the performance of the different RAG configurations in terms of retriever and generator, providing insights into their effectiveness, scalability, and suitability for the specific domain and applications. In this paper, we present a comprehensive framework to generate a domain relevant RAG benchmark. Our framework is based on automatic question-answer generation with Human (domain experts)-AI Large Language Model (LLM) teaming. As a case study, we demonstrate the framework by introducing PermitQA, a first-of-its-kind benchmark on the wind siting and permitting domain which comprises of multiple scientific documents/reports related to environmental impact of wind energy projects. Our framework systematically evaluates RAG performance using diverse metrics and multiple question types with varying complexity level. We also demonstrate the performance of different models on our benchmark.
RAG vs. Long Context: Examining Frontier Large Language Models for Environmental Review Document Comprehension
Jul 10, 2024



Large Language Models (LLMs) have been applied to many research problems across various domains. One of the applications of LLMs is providing question-answering systems that cater to users from different fields. The effectiveness of LLM-based question-answering systems has already been established at an acceptable level for users posing questions in popular and public domains such as trivia and literature. However, it has not often been established in niche domains that traditionally require specialized expertise. To this end, we construct the NEPAQuAD1.0 benchmark to evaluate the performance of three frontier LLMs -- Claude Sonnet, Gemini, and GPT-4 -- when answering questions originating from Environmental Impact Statements prepared by U.S. federal government agencies in accordance with the National Environmental Environmental Act (NEPA). We specifically measure the ability of LLMs to understand the nuances of legal, technical, and compliance-related information present in NEPA documents in different contextual scenarios. For example, we test the LLMs' internal prior NEPA knowledge by providing questions without any context, as well as assess how LLMs synthesize the contextual information present in long NEPA documents to facilitate the question/answering task. We compare the performance of the long context LLMs and RAG powered models in handling different types of questions (e.g., problem-solving, divergent). Our results suggest that RAG powered models significantly outperform the long context models in the answer accuracy regardless of the choice of the frontier LLM. Our further analysis reveals that many models perform better answering closed questions than divergent and problem-solving questions.
ATLANTIC: Structure-Aware Retrieval-Augmented Language Model for Interdisciplinary Science
Nov 21, 2023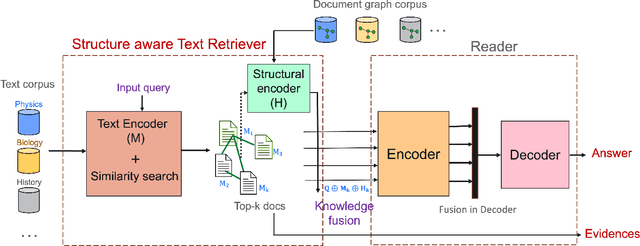

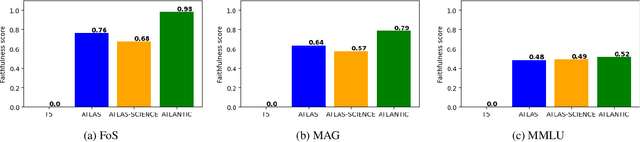

Large language models record impressive performance on many natural language processing tasks. However, their knowledge capacity is limited to the pretraining corpus. Retrieval augmentation offers an effective solution by retrieving context from external knowledge sources to complement the language model. However, existing retrieval augmentation techniques ignore the structural relationships between these documents. Furthermore, retrieval models are not explored much in scientific tasks, especially in regard to the faithfulness of retrieved documents. In this paper, we propose a novel structure-aware retrieval augmented language model that accommodates document structure during retrieval augmentation. We create a heterogeneous document graph capturing multiple types of relationships (e.g., citation, co-authorship, etc.) that connect documents from more than 15 scientific disciplines (e.g., Physics, Medicine, Chemistry, etc.). We train a graph neural network on the curated document graph to act as a structural encoder for the corresponding passages retrieved during the model pretraining. Particularly, along with text embeddings of the retrieved passages, we obtain structural embeddings of the documents (passages) and fuse them together before feeding them to the language model. We evaluate our model extensively on various scientific benchmarks that include science question-answering and scientific document classification tasks. Experimental results demonstrate that structure-aware retrieval improves retrieving more coherent, faithful and contextually relevant passages, while showing a comparable performance in the overall accuracy.
Empirical evaluation of Uncertainty Quantification in Retrieval-Augmented Language Models for Science
Nov 15, 2023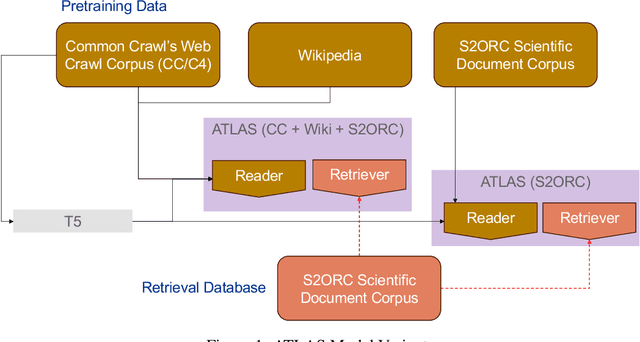
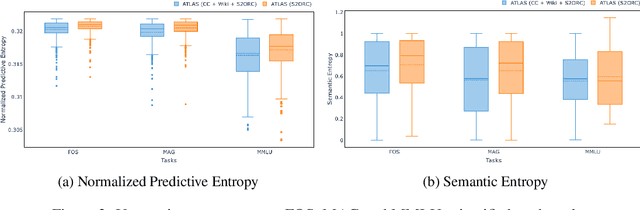

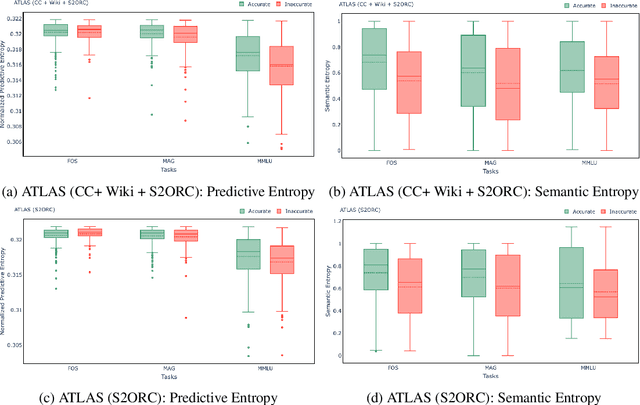
Large language models (LLMs) have shown remarkable achievements in natural language processing tasks, producing high-quality outputs. However, LLMs still exhibit limitations, including the generation of factually incorrect information. In safety-critical applications, it is important to assess the confidence of LLM-generated content to make informed decisions. Retrieval Augmented Language Models (RALMs) is relatively a new area of research in NLP. RALMs offer potential benefits for scientific NLP tasks, as retrieved documents, can serve as evidence to support model-generated content. This inclusion of evidence enhances trustworthiness, as users can verify and explore the retrieved documents to validate model outputs. Quantifying uncertainty in RALM generations further improves trustworthiness, with retrieved text and confidence scores contributing to a comprehensive and reliable model for scientific applications. However, there is limited to no research on UQ for RALMs, particularly in scientific contexts. This study aims to address this gap by conducting a comprehensive evaluation of UQ in RALMs, focusing on scientific tasks. This research investigates how uncertainty scores vary when scientific knowledge is incorporated as pretraining and retrieval data and explores the relationship between uncertainty scores and the accuracy of model-generated outputs. We observe that an existing RALM finetuned with scientific knowledge as the retrieval data tends to be more confident in generating predictions compared to the model pretrained only with scientific knowledge. We also found that RALMs are overconfident in their predictions, making inaccurate predictions more confidently than accurate ones. Scientific knowledge provided either as pretraining or retrieval corpus does not help alleviate this issue. We released our code, data and dashboards at https://github.com/pnnl/EXPERT2.
Evaluating the Effectiveness of Retrieval-Augmented Large Language Models in Scientific Document Reasoning
Nov 07, 2023Despite the dramatic progress in Large Language Model (LLM) development, LLMs often provide seemingly plausible but not factual information, often referred to as hallucinations. Retrieval-augmented LLMs provide a non-parametric approach to solve these issues by retrieving relevant information from external data sources and augment the training process. These models help to trace evidence from an externally provided knowledge base allowing the model predictions to be better interpreted and verified. In this work, we critically evaluate these models in their ability to perform in scientific document reasoning tasks. To this end, we tuned multiple such model variants with science-focused instructions and evaluated them on a scientific document reasoning benchmark for the usefulness of the retrieved document passages. Our findings suggest that models justify predictions in science tasks with fabricated evidence and leveraging scientific corpus as pretraining data does not alleviate the risk of evidence fabrication.
NuclearQA: A Human-Made Benchmark for Language Models for the Nuclear Domain
Oct 17, 2023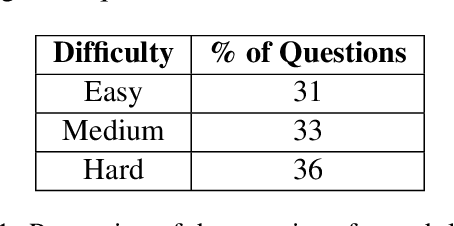

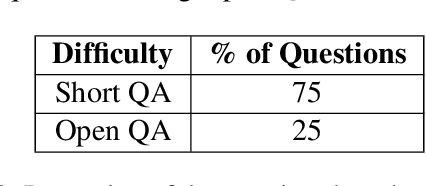
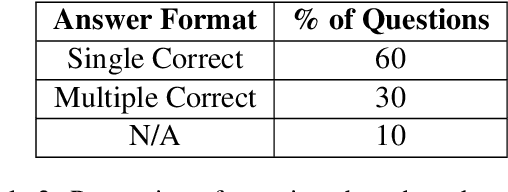
As LLMs have become increasingly popular, they have been used in almost every field. But as the application for LLMs expands from generic fields to narrow, focused science domains, there exists an ever-increasing gap in ways to evaluate their efficacy in those fields. For the benchmarks that do exist, a lot of them focus on questions that don't require proper understanding of the subject in question. In this paper, we present NuclearQA, a human-made benchmark of 100 questions to evaluate language models in the nuclear domain, consisting of a varying collection of questions that have been specifically designed by experts to test the abilities of language models. We detail our approach and show how the mix of several types of questions makes our benchmark uniquely capable of evaluating models in the nuclear domain. We also present our own evaluation metric for assessing LLM's performances due to the limitations of existing ones. Our experiments on state-of-the-art models suggest that even the best LLMs perform less than satisfactorily on our benchmark, demonstrating the scientific knowledge gap of existing LLMs.