 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Adaptation Win? Scaling Laws for Meta-Learning in Quantum Control
Jan 26, 2026Quantum hardware suffers from intrinsic device heterogeneity and environmental drift, forcing practitioners to choose between suboptimal non-adaptive controllers or costly per-device recalibration. We derive a scaling law lower bound for meta-learning showing that the adaptation gain (expected fidelity improvement from task-specific gradient steps) saturates exponentially with gradient steps and scales linearly with task variance, providing a quantitative criterion for when adaptation justifies its overhead. Validation on quantum gate calibration shows negligible benefits for low-variance tasks but $>40\%$ fidelity gains on two-qubit gates under extreme out-of-distribution conditions (10$\times$ the training noise), with implications for reducing per-device calibration time on cloud quantum processors. Further validation on classical linear-quadratic control confirms these laws emerge from general optimization geometry rather than quantum-specific physics. Together, these results offer a transferable framework for decision-making in adaptive control.
Personalised recommendations of sleep behaviour with neural networks using sleep diaries captured in Sleepio
Jul 29, 2022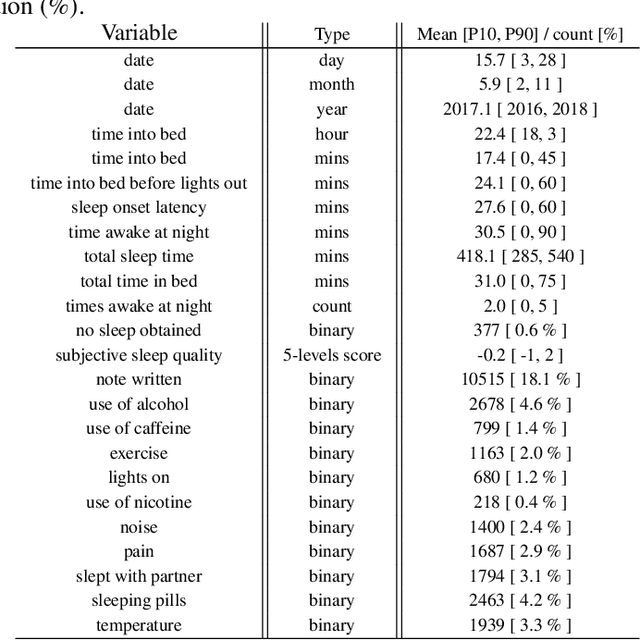
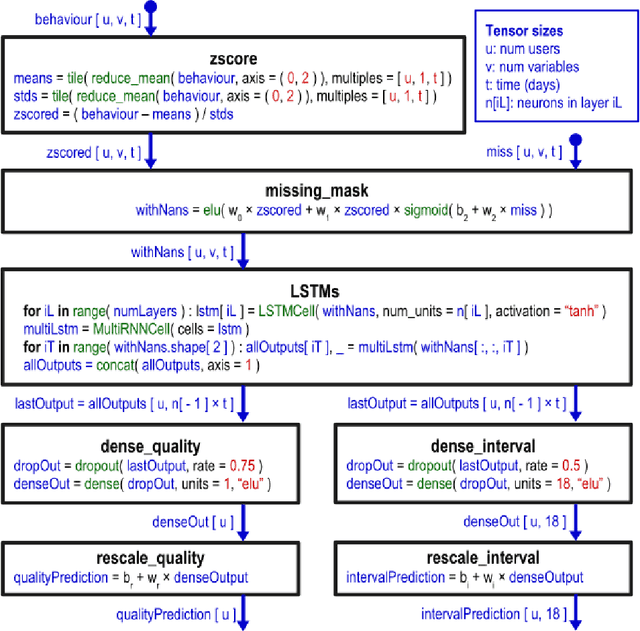
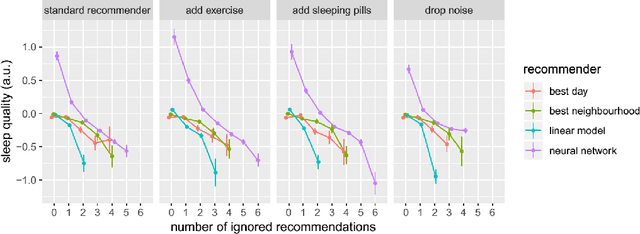
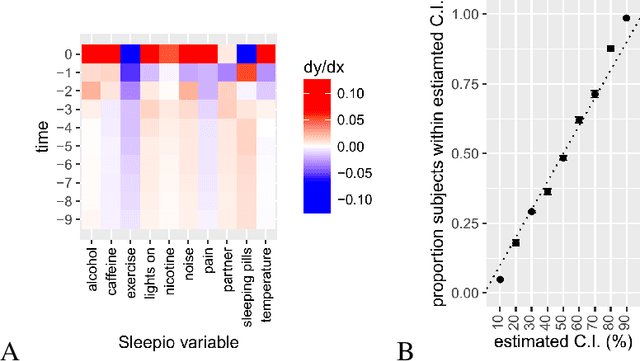
SleepioTM is a digital mobile phone and web platform that uses techniques from cognitive behavioural therapy (CBT) to improve sleep in people with sleep difficulty. As part of this process, Sleepio captures data about the sleep behaviour of the users that have consented to such data being processed. For neural networks, the scale of the data is an opportunity to train meaningful models translatable to actual clinical practice. In collaboration with Big Health, the therapeutics company that created and utilizes Sleepio, we have analysed data from a random sample of 401,174 sleep diaries and built a neural network to model sleep behaviour and sleep quality of each individual in a personalised manner. We demonstrate that this neural network is more accurate than standard statistical methods in predicting the sleep quality of an individual based on his/her behaviour from the last 10 days. We compare model performance in a wide range of hyperparameter settings representing various scenarios. We further show that the neural network can be used to produce personalised recommendations of what sleep habits users should follow to maximise sleep quality, and show that these recommendations are substantially better than the ones generated by standard methods. We finally show that the neural network can explain the recommendation given to each participant and calculate confidence intervals for each prediction, all of which are essential for clinicians to be able to adopt such a tool in clinical practice.
Unsupervised Cross-Task Generalization via Retrieval Augmentation
Apr 17, 2022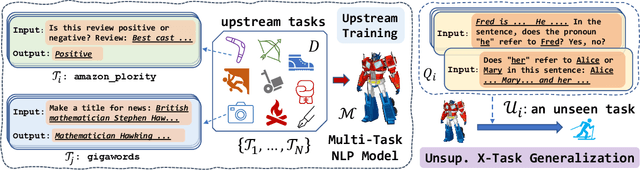


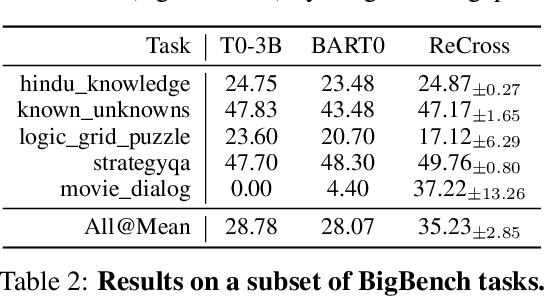
Humans can perform unseen tasks by recalling relevant skills that are acquired previously and then generalizing them to the target tasks, even if there is no supervision at all. In this paper, we aim to improve such cross-task generalization ability of massive multi-task language models such as T0 (Sanh et al., 2021) in an unsupervised setting. We propose a retrieval-augmentation method named ReCross that takes a few unlabelled examples as queries to retrieve a small subset of upstream data and uses them to update the multi-task model for better generalization. Our empirical results show that the proposed ReCross consistently outperforms non-retrieval baselines by a significant margin.
Finding Trolls Under Bridges: Preliminary Work on a Motif Detector
Apr 12, 2022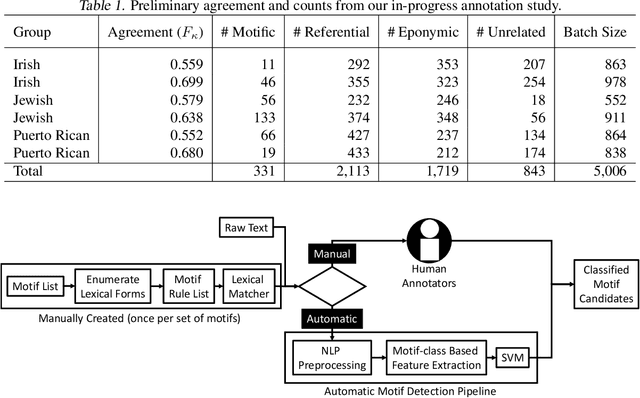

Motifs are distinctive recurring elements found in folklore that have significance as communicative devices in news, literature, press releases, and propaganda. Motifs concisely imply a large constellation of culturally-relevant information, and their broad usage suggests their cognitive importance as touchstones of cultural knowledge, making their detection a worthy step toward culturally-aware natural language processing tasks. Until now, folklorists and others interested in motifs have only extracted motifs from narratives manually. We present a preliminary report on the development of a system for automatically detecting motifs. We briefly describe an annotation effort to produce data for training motif detection, which is on-going. We describe our in-progress architecture in detail, which aims to capture, in part, how people determine whether or not a motif candidate is being used in a motific way. This description includes a test of an off-the-shelf metaphor detector as a feature for motif detection, which achieves a F1 of 0.35 on motifs and a macro-average F1 of 0.21 across four categories which we assign to motif candidates.
Big Green at WNUT 2020 Shared Task-1: Relation Extraction as Contextualized Sequence Classification
Dec 07, 2020
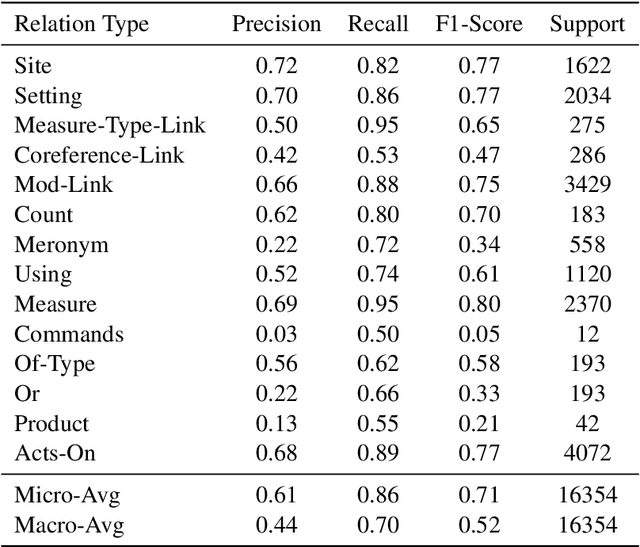
Relation and event extraction is an important task in natural language processing. We introduce a system which uses contextualized knowledge graph completion to classify relations and events between known entities in a noisy text environment. We report results which show that our system is able to effectively extract relations and events from a dataset of wet lab protocols.
Query-Free Adversarial Transfer via Undertrained Surrogates
Jul 01, 2020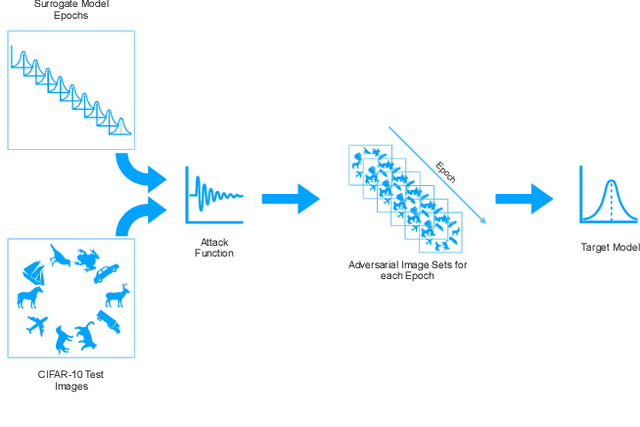
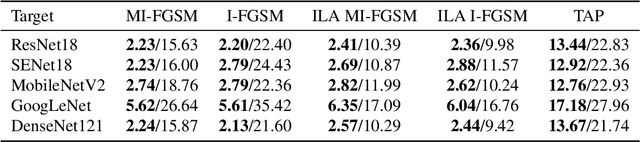

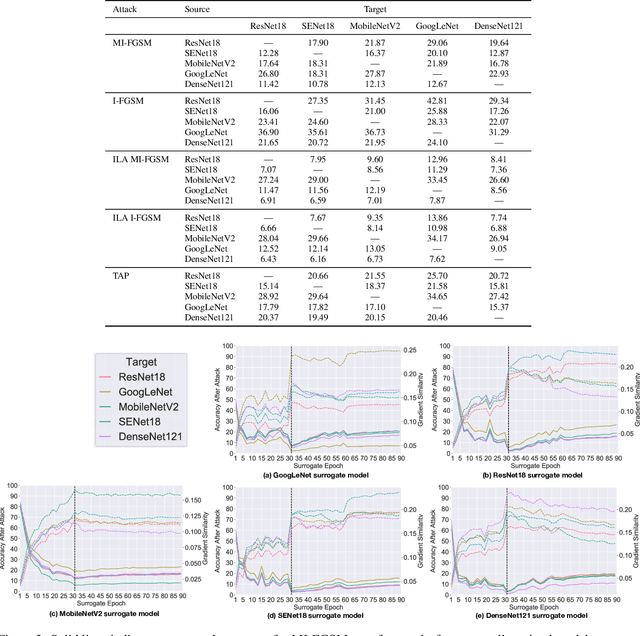
Deep neural networks have been shown to be highly vulnerable to adversarial examples---minor perturbations added to a model's input which cause the model to output an incorrect prediction. This vulnerability represents both a risk for the use of deep learning models in security-conscious fields and an opportunity to improve our understanding of how deep networks generalize to unexpected inputs. In a transfer attack, the adversary builds an adversarial attack using a surrogate model, then uses that attack to fool an unseen target model. Recent work in this subfield has focused on attack generation methods which can improve transferability between models. We show that optimizing a single surrogate model is a more effective method of improving adversarial transfer, using the simple example of an undertrained surrogate. This method transfers well across varied architectures and outperforms state-of-the-art methods. To interpret the effectiveness of undertrained surrogate models, we represent adversarial transferability as a function of surrogate model loss function curvature and similarity between surrogate and target gradients and show that our approach reduces the presence of local loss maxima which hinder transferability. Our results suggest that finding good single surrogate models is a highly effective and simple method for generating transferable adversarial attacks, and that this method represents a valuable route for future study in this field.