 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
Mar 20, 2026We present Future-KL Influenced Policy Optimization (FIPO), a reinforcement learning algorithm designed to overcome reasoning bottlenecks in large language models. While GRPO style training scales effectively, it typically relies on outcome-based rewards (ORM) that distribute a global advantage uniformly across every token in a trajectory. We argue that this coarse-grained credit assignment imposes a performance ceiling by failing to distinguish critical logical pivots from trivial tokens. FIPO addresses this by incorporating discounted future-KL divergence into the policy update, creating a dense advantage formulation that re-weights tokens based on their influence on subsequent trajectory behavior. Empirically, FIPO enables models to break through the length stagnation seen in standard baselines. Evaluated on Qwen2.5-32B, FIPO extends the average chain-of-thought length from roughly 4,000 to over 10,000 tokens and increases AIME 2024 Pass@1 accuracy from 50.0% to a peak of 58.0% (converging at approximately 56.0\%). This outperforms both DeepSeek-R1-Zero-Math-32B (around 47.0%) and o1-mini (approximately 56.0%). Our results suggest that establishing dense advantage formulations is a vital path for evolving ORM-based algorithms to unlock the full reasoning potential of base models. We open-source our training system, built on the verl framework.
Behavior Knowledge Merge in Reinforced Agentic Models
Jan 20, 2026Reinforcement learning (RL) is central to post-training, particularly for agentic models that require specialized reasoning behaviors. In this setting, model merging offers a practical mechanism for integrating multiple RL-trained agents from different tasks into a single generalist model. However, existing merging methods are designed for supervised fine-tuning (SFT), and they are suboptimal to preserve task-specific capabilities on RL-trained agentic models. The root is a task-vector mismatch between RL and SFT: on-policy RL induces task vectors that are highly sparse and heterogeneous, whereas SFT-style merging implicitly assumes dense and globally comparable task vectors. When standard global averaging is applied under this mismatch, RL's non-overlapping task vectors that encode critical task-specific behaviors are reduced and parameter updates are diluted. To address this issue, we propose Reinforced Agent Merging (RAM), a distribution-aware merging framework explicitly designed for RL-trained agentic models. RAM disentangles shared and task-specific unique parameter updates, averaging shared components while selectively preserving and rescaling unique ones to counteract parameter update dilution. Experiments across multiple agent domains and model architectures demonstrate that RAM not only surpasses merging baselines, but also unlocks synergistic potential among agents to achieve performance superior to that of specialized agents in their domains.
Addressing Overthinking in Large Vision-Language Models via Gated Perception-Reasoning Optimization
Jan 07, 2026Large Vision-Language Models (LVLMs) have exhibited strong reasoning capabilities through chain-of-thought mechanisms that generate step-by-step rationales. However, such slow-thinking approaches often lead to overthinking, where models produce excessively verbose responses even for simple queries, resulting in test-time inefficiency and even degraded accuracy. Prior work has attempted to mitigate this issue via adaptive reasoning strategies, but these methods largely overlook a fundamental bottleneck: visual perception failures. We argue that stable reasoning critically depends on low-level visual grounding, and that reasoning errors often originate from imperfect perception rather than insufficient deliberation. To address this limitation, we propose Gated Perception-Reasoning Optimization (GPRO), a meta-reasoning controller that dynamically routes computation among three decision paths at each generation step: a lightweight fast path, a slow perception path for re-examining visual inputs, and a slow reasoning path for internal self-reflection. To learn this distinction, we derive large-scale failure attribution supervision from approximately 790k samples, using teacher models to distinguish perceptual hallucinations from reasoning errors. We then train the controller with multi-objective reinforcement learning to optimize the trade-off between task accuracy and computational cost under uncertainty. Experiments on five benchmarks demonstrate that GPRO substantially improves both accuracy and efficiency, outperforming recent slow-thinking methods while generating significantly shorter responses.
Diffusion Language Models Know the Answer Before Decoding
Aug 27, 2025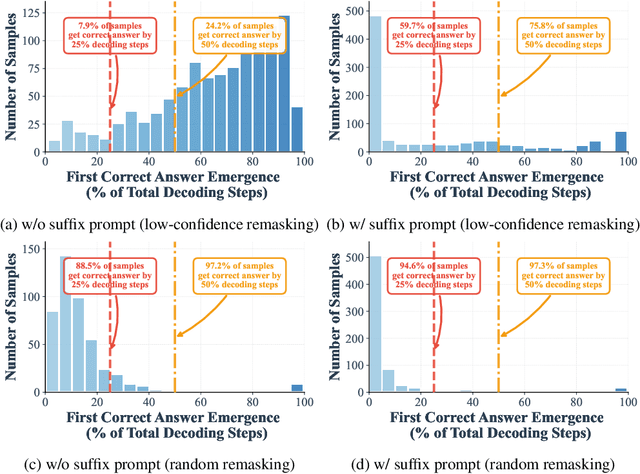
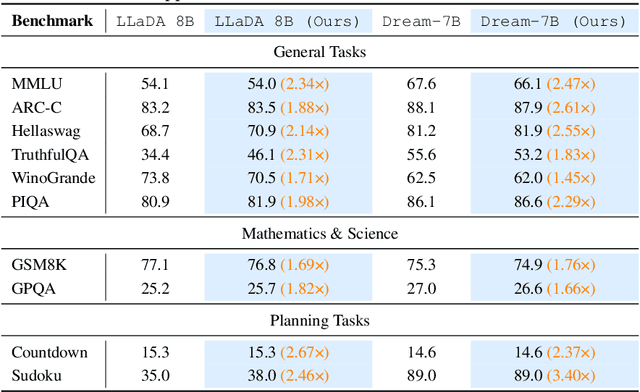
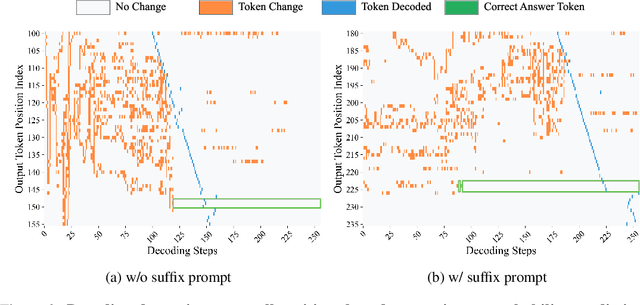
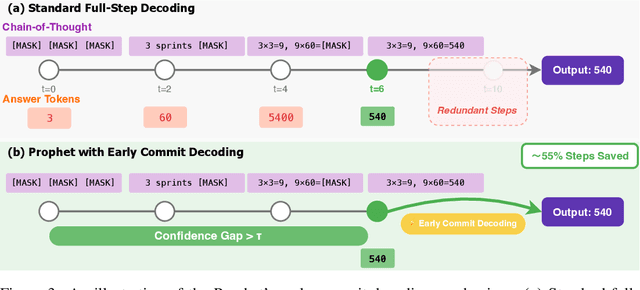
Diffusion language models (DLMs) have recently emerged as an alternative to autoregressive approaches, offering parallel sequence generation and flexible token orders. However, their inference remains slower than that of autoregressive models, primarily due to the cost of bidirectional attention and the large number of refinement steps required for high quality outputs. In this work, we highlight and leverage an overlooked property of DLMs early answer convergence: in many cases, the correct answer can be internally identified by half steps before the final decoding step, both under semi-autoregressive and random remasking schedules. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps. Building on this observation, we introduce Prophet, a training-free fast decoding paradigm that enables early commit decoding. Specifically, Prophet dynamically decides whether to continue refinement or to go "all-in" (i.e., decode all remaining tokens in one step), using the confidence gap between the top-2 prediction candidates as the criterion. It integrates seamlessly into existing DLM implementations, incurs negligible overhead, and requires no additional training. Empirical evaluations of LLaDA-8B and Dream-7B across multiple tasks show that Prophet reduces the number of decoding steps by up to 3.4x while preserving high generation quality. These results recast DLM decoding as a problem of when to stop sampling, and demonstrate that early decode convergence provides a simple yet powerful mechanism for accelerating DLM inference, complementary to existing speedup techniques. Our code is publicly available at https://github.com/pixeli99/Prophet.
SoundMind: RL-Incentivized Logic Reasoning for Audio-Language Models
Jun 15, 2025While large language models have shown reasoning capabilities, their application to the audio modality, particularly in large audio-language models (ALMs), remains significantly underdeveloped. Addressing this gap requires a systematic approach, involving a capable base model, high-quality reasoning-oriented audio data, and effective training algorithms. In this study, we present a comprehensive solution: we introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building on this resource, we propose SoundMind, a rule-based reinforcement learning (RL) algorithm tailored to endow ALMs with deep bimodal reasoning abilities. By training Qwen2.5-Omni-7B on the ALR dataset using SoundMind, our approach achieves state-of-the-art performance in audio logical reasoning. This work highlights the impact of combining high-quality, reasoning-focused datasets with specialized RL techniques, advancing the frontier of auditory intelligence in language models. Our code and the proposed dataset are available at https://github.com/xid32/SoundMind.
KCES: Training-Free Defense for Robust Graph Neural Networks via Kernel Complexity
Jun 13, 2025Graph Neural Networks (GNNs) have achieved impressive success across a wide range of graph-based tasks, yet they remain highly vulnerable to small, imperceptible perturbations and adversarial attacks. Although numerous defense methods have been proposed to address these vulnerabilities, many rely on heuristic metrics, overfit to specific attack patterns, and suffer from high computational complexity. In this paper, we propose Kernel Complexity-Based Edge Sanitization (KCES), a training-free, model-agnostic defense framework. KCES leverages Graph Kernel Complexity (GKC), a novel metric derived from the graph's Gram matrix that characterizes GNN generalization via its test error bound. Building on GKC, we define a KC score for each edge, measuring the change in GKC when the edge is removed. Edges with high KC scores, typically introduced by adversarial perturbations, are pruned to mitigate their harmful effects, thereby enhancing GNNs' robustness. KCES can also be seamlessly integrated with existing defense strategies as a plug-and-play module without requiring training. Theoretical analysis and extensive experiments demonstrate that KCES consistently enhances GNN robustness, outperforms state-of-the-art baselines, and amplifies the effectiveness of existing defenses, offering a principled and efficient solution for securing GNNs.
Probing Association Biases in LLM Moderation Over-Sensitivity
May 29, 2025Large Language Models are widely used for content moderation but often misclassify benign comments as toxic, leading to over-sensitivity. While previous research attributes this issue primarily to the presence of offensive terms, we reveal a potential cause beyond token level: LLMs exhibit systematic topic biases in their implicit associations. Inspired by cognitive psychology's implicit association tests, we introduce Topic Association Analysis, a semantic-level approach to quantify how LLMs associate certain topics with toxicity. By prompting LLMs to generate free-form scenario imagination for misclassified benign comments and analyzing their topic amplification levels, we find that more advanced models (e.g., GPT-4 Turbo) demonstrate stronger topic stereotype despite lower overall false positive rates. These biases suggest that LLMs do not merely react to explicit, offensive language but rely on learned topic associations, shaping their moderation decisions. Our findings highlight the need for refinement beyond keyword-based filtering, providing insights into the underlying mechanisms driving LLM over-sensitivity.
Music's Multimodal Complexity in AVQA: Why We Need More than General Multimodal LLMs
May 27, 2025While recent Multimodal Large Language Models exhibit impressive capabilities for general multimodal tasks, specialized domains like music necessitate tailored approaches. Music Audio-Visual Question Answering (Music AVQA) particularly underscores this, presenting unique challenges with its continuous, densely layered audio-visual content, intricate temporal dynamics, and the critical need for domain-specific knowledge. Through a systematic analysis of Music AVQA datasets and methods, this position paper identifies that specialized input processing, architectures incorporating dedicated spatial-temporal designs, and music-specific modeling strategies are critical for success in this domain. Our study provides valuable insights for researchers by highlighting effective design patterns empirically linked to strong performance, proposing concrete future directions for incorporating musical priors, and aiming to establish a robust foundation for advancing multimodal musical understanding. This work is intended to inspire broader attention and further research, supported by a continuously updated anonymous GitHub repository of relevant papers: https://github.com/xid32/Survey4MusicAVQA.
Judging with Many Minds: Do More Perspectives Mean Less Prejudice?
May 26, 2025LLM-as-Judge has emerged as a scalable alternative to human evaluation, enabling large language models (LLMs) to provide reward signals in trainings. While recent work has explored multi-agent extensions such as multi-agent debate and meta-judging to enhance evaluation quality, the question of how intrinsic biases manifest in these settings remains underexplored. In this study, we conduct a systematic analysis of four diverse bias types: position bias, verbosity bias, chain-of-thought bias, and bandwagon bias. We evaluate these biases across two widely adopted multi-agent LLM-as-Judge frameworks: Multi-Agent-Debate and LLM-as-Meta-Judge. Our results show that debate framework amplifies biases sharply after the initial debate, and this increased bias is sustained in subsequent rounds, while meta-judge approaches exhibit greater resistance. We further investigate the incorporation of PINE, a leading single-agent debiasing method, as a bias-free agent within these systems. The results reveal that this bias-free agent effectively reduces biases in debate settings but provides less benefit in meta-judge scenarios. Our work provides a comprehensive study of bias behavior in multi-agent LLM-as-Judge systems and highlights the need for targeted bias mitigation strategies in collaborative evaluation settings.
DECASTE: Unveiling Caste Stereotypes in Large Language Models through Multi-Dimensional Bias Analysis
May 20, 2025Recent advancements in large language models (LLMs) have revolutionized natural language processing (NLP) and expanded their applications across diverse domains. However, despite their impressive capabilities, LLMs have been shown to reflect and perpetuate harmful societal biases, including those based on ethnicity, gender, and religion. A critical and underexplored issue is the reinforcement of caste-based biases, particularly towards India's marginalized caste groups such as Dalits and Shudras. In this paper, we address this gap by proposing DECASTE, a novel, multi-dimensional framework designed to detect and assess both implicit and explicit caste biases in LLMs. Our approach evaluates caste fairness across four dimensions: socio-cultural, economic, educational, and political, using a range of customized prompting strategies. By benchmarking several state-of-the-art LLMs, we reveal that these models systematically reinforce caste biases, with significant disparities observed in the treatment of oppressed versus dominant caste groups. For example, bias scores are notably elevated when comparing Dalits and Shudras with dominant caste groups, reflecting societal prejudices that persist in model outputs. These results expose the subtle yet pervasive caste biases in LLMs and emphasize the need for more comprehensive and inclusive bias evaluation methodologies that assess the potential risks of deploying such models in real-world contexts.