 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Knowledge Merge in Reinforced Agentic Models
Jan 20, 2026Reinforcement learning (RL) is central to post-training, particularly for agentic models that require specialized reasoning behaviors. In this setting, model merging offers a practical mechanism for integrating multiple RL-trained agents from different tasks into a single generalist model. However, existing merging methods are designed for supervised fine-tuning (SFT), and they are suboptimal to preserve task-specific capabilities on RL-trained agentic models. The root is a task-vector mismatch between RL and SFT: on-policy RL induces task vectors that are highly sparse and heterogeneous, whereas SFT-style merging implicitly assumes dense and globally comparable task vectors. When standard global averaging is applied under this mismatch, RL's non-overlapping task vectors that encode critical task-specific behaviors are reduced and parameter updates are diluted. To address this issue, we propose Reinforced Agent Merging (RAM), a distribution-aware merging framework explicitly designed for RL-trained agentic models. RAM disentangles shared and task-specific unique parameter updates, averaging shared components while selectively preserving and rescaling unique ones to counteract parameter update dilution. Experiments across multiple agent domains and model architectures demonstrate that RAM not only surpasses merging baselines, but also unlocks synergistic potential among agents to achieve performance superior to that of specialized agents in their domains.
SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs
Oct 06, 2025Recent work shows that, beyond discrete reasoning through explicit chain-of-thought steps, which are limited by the boundaries of natural languages, large language models (LLMs) can also reason continuously in latent space, allowing richer information per step and thereby improving token efficiency. Despite this promise, latent reasoning still faces two challenges, especially in training-free settings: 1) purely latent reasoning broadens the search distribution by maintaining multiple implicit paths, which diffuses probability mass, introduces noise, and impedes convergence to a single high-confidence solution, thereby hurting accuracy; and 2) overthinking persists even without explicit text, wasting tokens and degrading efficiency. To address these issues, we introduce SwiReasoning, a training-free framework for LLM reasoning which features two key innovations: 1) SwiReasoning dynamically switches between explicit and latent reasoning, guided by block-wise confidence estimated from entropy trends in next-token distributions, to balance exploration and exploitation and promote timely convergence. 2) By limiting the maximum number of thinking-block switches, SwiReasoning curbs overthinking and improves token efficiency across varying problem difficulties. On widely used mathematics and STEM benchmarks, SwiReasoning consistently improves average accuracy by 1.5%-2.8% across reasoning LLMs of different model families and scales. Furthermore, under constrained budgets, SwiReasoning improves average token efficiency by 56%-79%, with larger gains as budgets tighten.
Mitigating Forgetting Between Supervised and Reinforcement Learning Yields Stronger Reasoners
Oct 06, 2025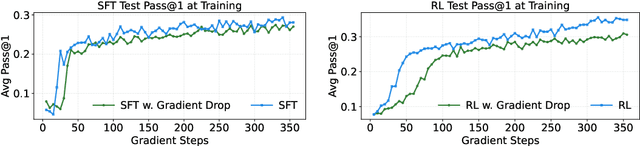
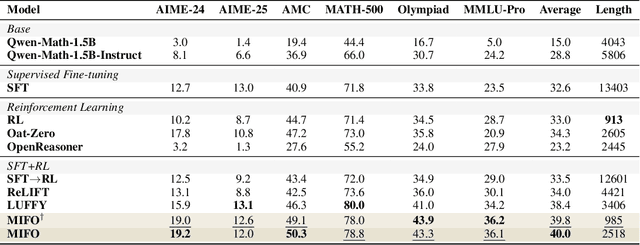
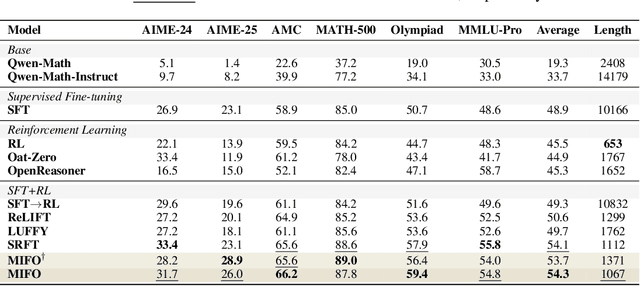

Large Language Models (LLMs) show strong reasoning abilities, often amplified by Chain-of-Thought (CoT) prompting and reinforcement learning (RL). Although RL algorithms can substantially improve reasoning, they struggle to expand reasoning boundaries because they learn from their own reasoning trajectories rather than acquiring external knowledge. Supervised fine-tuning (SFT) offers complementary benefits but typically requires large-scale data and risks overfitting. Recent attempts to combine SFT and RL face three main challenges: data inefficiency, algorithm-specific designs, and catastrophic forgetting. We propose a plug-and-play framework that dynamically integrates SFT into RL by selecting challenging examples for SFT. This approach reduces SFT data requirements and remains agnostic to the choice of RL or SFT algorithm. To mitigate catastrophic forgetting of RL-acquired skills during SFT, we select high-entropy tokens for loss calculation and freeze parameters identified as critical for RL. Our method achieves state-of-the-art (SoTA) reasoning performance using only 1.5% of the SFT data and 20.4% of the RL data used by prior SoTA, providing an efficient and plug-and-play solution for combining SFT and RL in reasoning post-training.
Superficial Self-Improved Reasoners Benefit from Model Merging
Mar 03, 2025As scaled language models (LMs) approach human-level reasoning capabilities, self-improvement emerges as a solution to synthesizing high-quality data corpus. While previous research has identified model collapse as a risk in self-improvement, where model outputs become increasingly deterministic, we discover a more fundamental challenge: the superficial self-improved reasoners phenomenon. In particular, our analysis reveals that even when LMs show improved in-domain (ID) reasoning accuracy, they actually compromise their generalized reasoning capabilities on out-of-domain (OOD) tasks due to memorization rather than genuine. Through a systematic investigation of LM architecture, we discover that during self-improvement, LM weight updates are concentrated in less reasoning-critical layers, leading to superficial learning. To address this, we propose Iterative Model Merging (IMM), a method that strategically combines weights from original and self-improved models to preserve generalization while incorporating genuine reasoning improvements. Our approach effectively mitigates both LM collapse and superficial learning, moving towards more stable self-improving systems.
Can Transformers Reason Logically? A Study in SAT Solving
Oct 09, 2024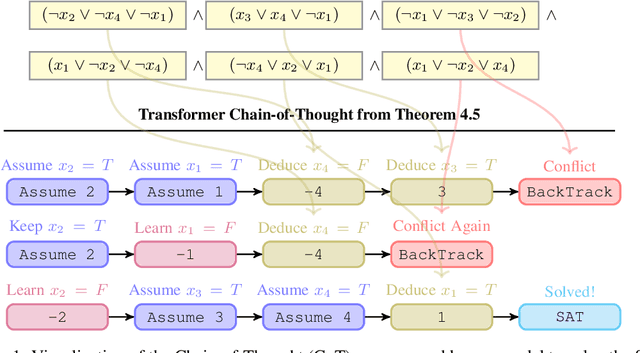
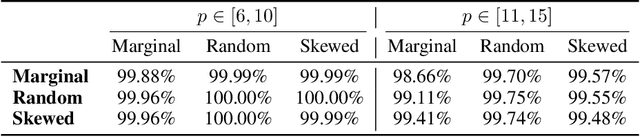
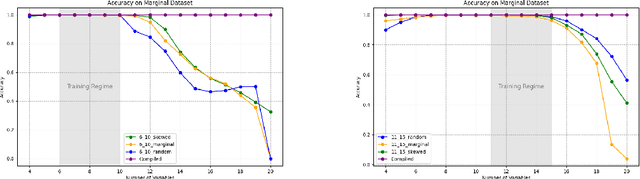
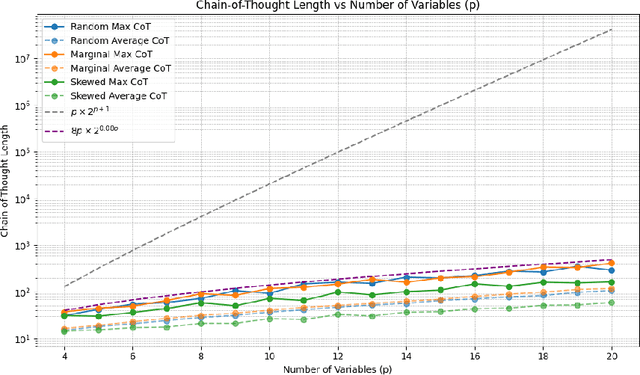
We theoretically and empirically study the logical reasoning capabilities of LLMs in the context of the Boolean satisfiability (SAT) problem. First, we construct a decoder-only Transformer that can solve SAT using backtracking and deduction via Chain-of-Thought (CoT). We prove its correctness by showing trace equivalence to the well-known DPLL SAT-solving algorithm. Second, to support the implementation of this abstract construction, we design a compiler $\texttt{PARAT}$ that takes as input a procedural specification and outputs a transformer model implementing this specification. Third, rather than $\textit{programming}$ a transformer to reason, we evaluate empirically whether it can be $\textit{trained}$ to do so by learning directly from algorithmic traces ("reasoning paths") of the DPLL algorithm.
Optimal Classification-based Anomaly Detection with Neural Networks: Theory and Practice
Sep 13, 2024Anomaly detection is an important problem in many application areas, such as network security. Many deep learning methods for unsupervised anomaly detection produce good empirical performance but lack theoretical guarantees. By casting anomaly detection into a binary classification problem, we establish non-asymptotic upper bounds and a convergence rate on the excess risk on rectified linear unit (ReLU) neural networks trained on synthetic anomalies. Our convergence rate on the excess risk matches the minimax optimal rate in the literature. Furthermore, we provide lower and upper bounds on the number of synthetic anomalies that can attain this optimality. For practical implementation, we relax some conditions to improve the search for the empirical risk minimizer, which leads to competitive performance to other classification-based methods for anomaly detection. Overall, our work provides the first theoretical guarantees of unsupervised neural network-based anomaly detectors and empirical insights on how to design them well.
Non-Robust Features are Not Always Useful in One-Class Classification
Jul 08, 2024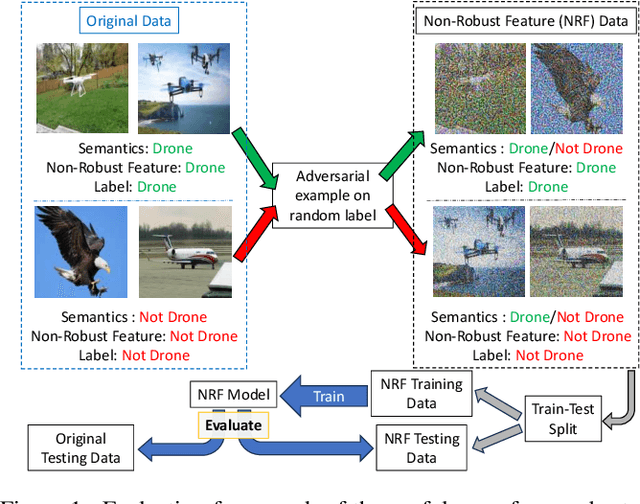

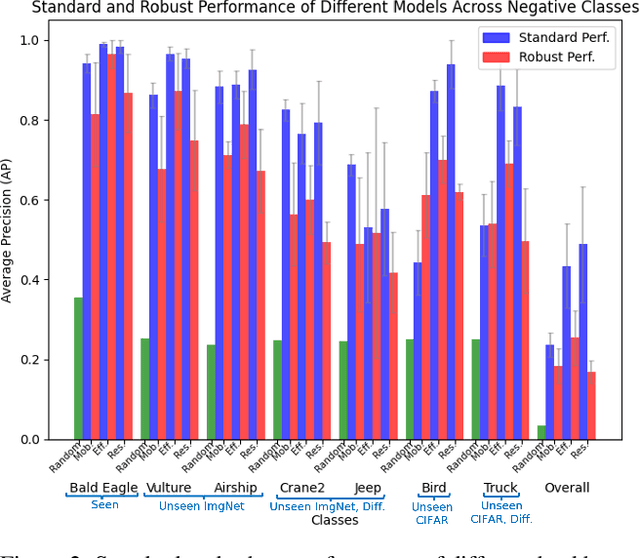
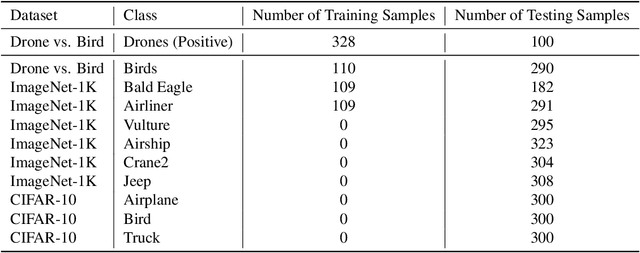
The robustness of machine learning models has been questioned by the existence of adversarial examples. We examine the threat of adversarial examples in practical applications that require lightweight models for one-class classification. Building on Ilyas et al. (2019), we investigate the vulnerability of lightweight one-class classifiers to adversarial attacks and possible reasons for it. Our results show that lightweight one-class classifiers learn features that are not robust (e.g. texture) under stronger attacks. However, unlike in multi-class classification (Ilyas et al., 2019), these non-robust features are not always useful for the one-class task, suggesting that learning these unpredictive and non-robust features is an unwanted consequence of training.
Revisiting Non-separable Binary Classification and its Applications in Anomaly Detection
Dec 03, 2023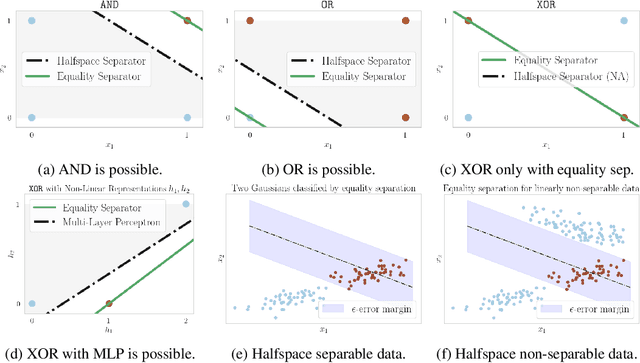

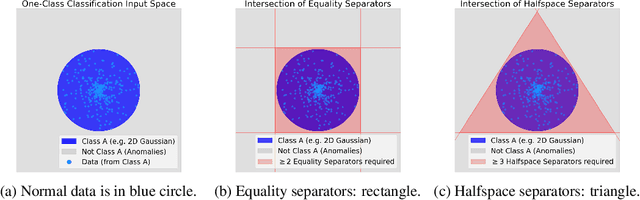
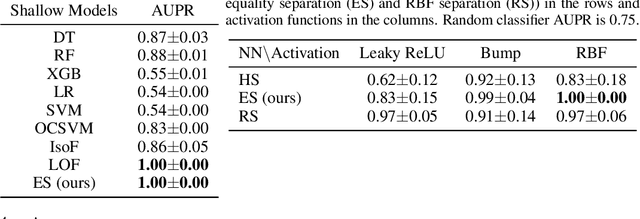
The inability to linearly classify XOR has motivated much of deep learning. We revisit this age-old problem and show that linear classification of XOR is indeed possible. Instead of separating data between halfspaces, we propose a slightly different paradigm, equality separation, that adapts the SVM objective to distinguish data within or outside the margin. Our classifier can then be integrated into neural network pipelines with a smooth approximation. From its properties, we intuit that equality separation is suitable for anomaly detection. To formalize this notion, we introduce closing numbers, a quantitative measure on the capacity for classifiers to form closed decision regions for anomaly detection. Springboarding from this theoretical connection between binary classification and anomaly detection, we test our hypothesis on supervised anomaly detection experiments, showing that equality separation can detect both seen and unseen anomalies.
The Threat of Offensive AI to Organizations
Jun 30, 2021
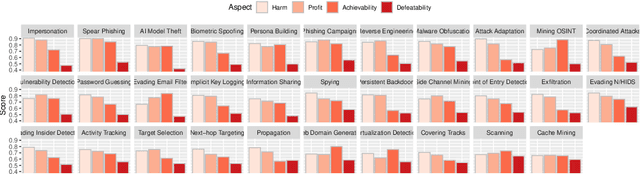


AI has provided us with the ability to automate tasks, extract information from vast amounts of data, and synthesize media that is nearly indistinguishable from the real thing. However, positive tools can also be used for negative purposes. In particular, cyber adversaries can use AI (such as machine learning) to enhance their attacks and expand their campaigns. Although offensive AI has been discussed in the past, there is a need to analyze and understand the threat in the context of organizations. For example, how does an AI-capable adversary impact the cyber kill chain? Does AI benefit the attacker more than the defender? What are the most significant AI threats facing organizations today and what will be their impact on the future? In this survey, we explore the threat of offensive AI on organizations. First, we present the background and discuss how AI changes the adversary's methods, strategies, goals, and overall attack model. Then, through a literature review, we identify 33 offensive AI capabilities which adversaries can use to enhance their attacks. Finally, through a user study spanning industry and academia, we rank the AI threats and provide insights on the adversaries.
The Creation and Detection of Deepfakes: A Survey
May 12, 2020
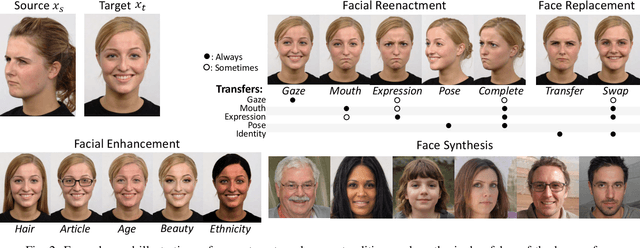


Generative deep learning algorithms have progressed to a point where it is difficult to tell the difference between what is real and what is fake. In 2018, it was discovered how easy it is to use this technology for unethical and malicious applications, such as the spread of misinformation, impersonation of political leaders, and the defamation of innocent individuals. Since then, these `deepfakes' have advanced significantly. In this paper, we explore the creation and detection of deepfakes and provide an in-depth view of how these architectures work. The purpose of this survey is to provide the reader with a deeper understanding of (1) how deepfakes are created and detected, (2) the current trends and advancements in this domain, (3) the shortcomings of the current defense solutions, and (4) the areas which require further research and attention.