 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Knowledge Merge in Reinforced Agentic Models
Jan 20, 2026Reinforcement learning (RL) is central to post-training, particularly for agentic models that require specialized reasoning behaviors. In this setting, model merging offers a practical mechanism for integrating multiple RL-trained agents from different tasks into a single generalist model. However, existing merging methods are designed for supervised fine-tuning (SFT), and they are suboptimal to preserve task-specific capabilities on RL-trained agentic models. The root is a task-vector mismatch between RL and SFT: on-policy RL induces task vectors that are highly sparse and heterogeneous, whereas SFT-style merging implicitly assumes dense and globally comparable task vectors. When standard global averaging is applied under this mismatch, RL's non-overlapping task vectors that encode critical task-specific behaviors are reduced and parameter updates are diluted. To address this issue, we propose Reinforced Agent Merging (RAM), a distribution-aware merging framework explicitly designed for RL-trained agentic models. RAM disentangles shared and task-specific unique parameter updates, averaging shared components while selectively preserving and rescaling unique ones to counteract parameter update dilution. Experiments across multiple agent domains and model architectures demonstrate that RAM not only surpasses merging baselines, but also unlocks synergistic potential among agents to achieve performance superior to that of specialized agents in their domains.
MTMCS-Bench: Evaluating Contextual Safety of Multimodal Large Language Models in Multi-Turn Dialogues
Jan 11, 2026Multimodal large language models (MLLMs) are increasingly deployed as assistants that interact through text and images, making it crucial to evaluate contextual safety when risk depends on both the visual scene and the evolving dialogue. Existing contextual safety benchmarks are mostly single-turn and often miss how malicious intent can emerge gradually or how the same scene can support both benign and exploitative goals. We introduce the Multi-Turn Multimodal Contextual Safety Benchmark (MTMCS-Bench), a benchmark of realistic images and multi-turn conversations that evaluates contextual safety in MLLMs under two complementary settings, escalation-based risk and context-switch risk. MTMCS-Bench offers paired safe and unsafe dialogues with structured evaluation. It contains over 30 thousand multimodal (image+text) and unimodal (text-only) samples, with metrics that separately measure contextual intent recognition, safety-awareness on unsafe cases, and helpfulness on benign ones. Across eight open-source and seven proprietary MLLMs, we observe persistent trade-offs between contextual safety and utility, with models tending to either miss gradual risks or over-refuse benign dialogues. Finally, we evaluate five current guardrails and find that they mitigate some failures but do not fully resolve multi-turn contextual risks.
Sparsity-Controllable Dynamic Top-p MoE for Large Foundation Model Pre-training
Dec 16, 2025Sparse Mixture-of-Experts (MoE) architectures effectively scale model capacity by activating only a subset of experts for each input token. However, the standard Top-k routing strategy imposes a uniform sparsity pattern that ignores the varying difficulty of tokens. While Top-p routing offers a flexible alternative, existing implementations typically rely on a fixed global probability threshold, which results in uncontrolled computational costs and sensitivity to hyperparameter selection. In this paper, we propose DTop-p MoE, a sparsity-controllable dynamic Top-p routing mechanism. To resolve the challenge of optimizing a non-differentiable threshold, we utilize a Proportional-Integral (PI) Controller that dynamically adjusts the probability threshold to align the running activated-expert sparsity with a specified target. Furthermore, we introduce a dynamic routing normalization mechanism that adapts layer-wise routing logits, allowing different layers to learn distinct expert-selection patterns while utilizing a global probability threshold. Extensive experiments on Large Language Models and Diffusion Transformers demonstrate that DTop-p consistently outperforms both Top-k and fixed-threshold Top-p baselines. Our analysis confirms that DTop-p maintains precise control over the number of activated experts while adaptively allocating resources across different tokens and layers. Furthermore, DTop-p exhibits strong scaling properties with respect to expert granularity, expert capacity, model size, and dataset size, offering a robust framework for large-scale MoE pre-training.
What Makes a Good Curriculum? Disentangling the Effects of Data Ordering on LLM Mathematical Reasoning
Oct 21, 2025Curriculum learning (CL) - ordering training data from easy to hard - has become a popular strategy for improving reasoning in large language models (LLMs). Yet prior work employs disparate difficulty metrics and training setups, leaving open fundamental questions: When does curriculum help? Which direction - forward or reverse - is better? And does the answer depend on what we measure? We address these questions through a unified offline evaluation framework that decomposes curriculum difficulty into five complementary dimensions: Problem Difficulty, Model Surprisal, Confidence Margin, Predictive Uncertainty, and Decision Variability. Through controlled post-training experiments on mathematical reasoning benchmarks with Llama3.1-8B, Mistral-7B, and Gemma3-4B, we find that (i) no curriculum strategy dominates universally - the relative effectiveness of forward versus reverse CL depends jointly on model capability and task complexity; (ii) even within a single metric, samples at different difficulty levels produce distinct gains depending on task demands; and (iii) task-aligned curricula focus on shaping the model's final representations and generalization, whereas inner-state curricula modulate internal states such as confidence and uncertainty. Our findings challenge the notion of a universal curriculum strategy and offer actionable guidance across model and task regimes, with some metrics indicating that prioritizing decision-uncertain samples can further enhance learning outcomes.
SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs
Oct 06, 2025Recent work shows that, beyond discrete reasoning through explicit chain-of-thought steps, which are limited by the boundaries of natural languages, large language models (LLMs) can also reason continuously in latent space, allowing richer information per step and thereby improving token efficiency. Despite this promise, latent reasoning still faces two challenges, especially in training-free settings: 1) purely latent reasoning broadens the search distribution by maintaining multiple implicit paths, which diffuses probability mass, introduces noise, and impedes convergence to a single high-confidence solution, thereby hurting accuracy; and 2) overthinking persists even without explicit text, wasting tokens and degrading efficiency. To address these issues, we introduce SwiReasoning, a training-free framework for LLM reasoning which features two key innovations: 1) SwiReasoning dynamically switches between explicit and latent reasoning, guided by block-wise confidence estimated from entropy trends in next-token distributions, to balance exploration and exploitation and promote timely convergence. 2) By limiting the maximum number of thinking-block switches, SwiReasoning curbs overthinking and improves token efficiency across varying problem difficulties. On widely used mathematics and STEM benchmarks, SwiReasoning consistently improves average accuracy by 1.5%-2.8% across reasoning LLMs of different model families and scales. Furthermore, under constrained budgets, SwiReasoning improves average token efficiency by 56%-79%, with larger gains as budgets tighten.
Mitigating Forgetting Between Supervised and Reinforcement Learning Yields Stronger Reasoners
Oct 06, 2025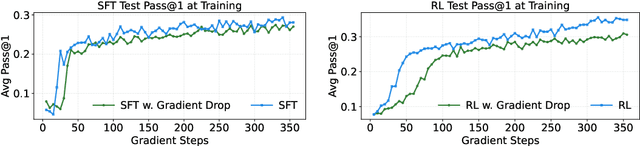
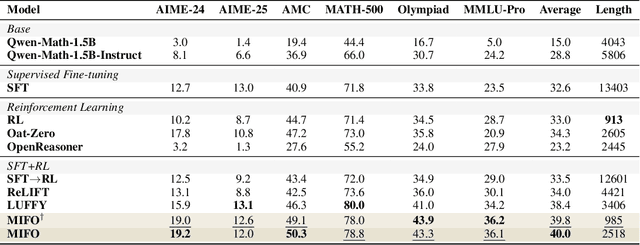
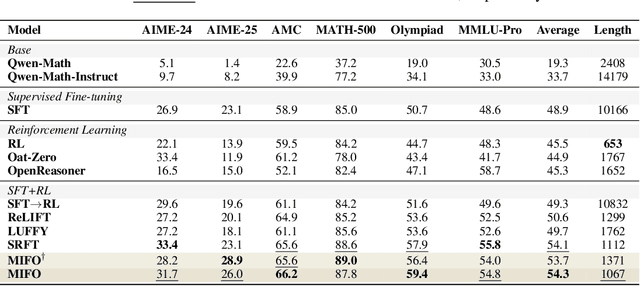

Large Language Models (LLMs) show strong reasoning abilities, often amplified by Chain-of-Thought (CoT) prompting and reinforcement learning (RL). Although RL algorithms can substantially improve reasoning, they struggle to expand reasoning boundaries because they learn from their own reasoning trajectories rather than acquiring external knowledge. Supervised fine-tuning (SFT) offers complementary benefits but typically requires large-scale data and risks overfitting. Recent attempts to combine SFT and RL face three main challenges: data inefficiency, algorithm-specific designs, and catastrophic forgetting. We propose a plug-and-play framework that dynamically integrates SFT into RL by selecting challenging examples for SFT. This approach reduces SFT data requirements and remains agnostic to the choice of RL or SFT algorithm. To mitigate catastrophic forgetting of RL-acquired skills during SFT, we select high-entropy tokens for loss calculation and freeze parameters identified as critical for RL. Our method achieves state-of-the-art (SoTA) reasoning performance using only 1.5% of the SFT data and 20.4% of the RL data used by prior SoTA, providing an efficient and plug-and-play solution for combining SFT and RL in reasoning post-training.
LongMamba: Enhancing Mamba's Long Context Capabilities via Training-Free Receptive Field Enlargement
Apr 22, 2025State space models (SSMs) have emerged as an efficient alternative to Transformer models for language modeling, offering linear computational complexity and constant memory usage as context length increases. However, despite their efficiency in handling long contexts, recent studies have shown that SSMs, such as Mamba models, generally underperform compared to Transformers in long-context understanding tasks. To address this significant shortfall and achieve both efficient and accurate long-context understanding, we propose LongMamba, a training-free technique that significantly enhances the long-context capabilities of Mamba models. LongMamba builds on our discovery that the hidden channels in Mamba can be categorized into local and global channels based on their receptive field lengths, with global channels primarily responsible for long-context capability. These global channels can become the key bottleneck as the input context lengthens. Specifically, when input lengths largely exceed the training sequence length, global channels exhibit limitations in adaptively extend their receptive fields, leading to Mamba's poor long-context performance. The key idea of LongMamba is to mitigate the hidden state memory decay in these global channels by preventing the accumulation of unimportant tokens in their memory. This is achieved by first identifying critical tokens in the global channels and then applying token filtering to accumulate only those critical tokens. Through extensive benchmarking across synthetic and real-world long-context scenarios, LongMamba sets a new standard for Mamba's long-context performance, significantly extending its operational range without requiring additional training. Our code is available at https://github.com/GATECH-EIC/LongMamba.
Superficial Self-Improved Reasoners Benefit from Model Merging
Mar 03, 2025As scaled language models (LMs) approach human-level reasoning capabilities, self-improvement emerges as a solution to synthesizing high-quality data corpus. While previous research has identified model collapse as a risk in self-improvement, where model outputs become increasingly deterministic, we discover a more fundamental challenge: the superficial self-improved reasoners phenomenon. In particular, our analysis reveals that even when LMs show improved in-domain (ID) reasoning accuracy, they actually compromise their generalized reasoning capabilities on out-of-domain (OOD) tasks due to memorization rather than genuine. Through a systematic investigation of LM architecture, we discover that during self-improvement, LM weight updates are concentrated in less reasoning-critical layers, leading to superficial learning. To address this, we propose Iterative Model Merging (IMM), a method that strategically combines weights from original and self-improved models to preserve generalization while incorporating genuine reasoning improvements. Our approach effectively mitigates both LM collapse and superficial learning, moving towards more stable self-improving systems.
Modality-Aware Neuron Pruning for Unlearning in Multimodal Large Language Models
Feb 21, 2025Generative models such as Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) trained on massive datasets can lead them to memorize and inadvertently reveal sensitive information, raising ethical and privacy concerns. While some prior works have explored this issue in the context of LLMs, it presents a unique challenge for MLLMs due to the entangled nature of knowledge across modalities, making comprehensive unlearning more difficult. To address this challenge, we propose Modality Aware Neuron Unlearning (MANU), a novel unlearning framework for MLLMs designed to selectively clip neurons based on their relative importance to the targeted forget data, curated for different modalities. Specifically, MANU consists of two stages: important neuron selection and selective pruning. The first stage identifies and collects the most influential neurons across modalities relative to the targeted forget knowledge, while the second stage is dedicated to pruning those selected neurons. MANU effectively isolates and removes the neurons that contribute most to the forget data within each modality, while preserving the integrity of retained knowledge. Our experiments conducted across various MLLM architectures illustrate that MANU can achieve a more balanced and comprehensive unlearning in each modality without largely affecting the overall model utility.
AmoebaLLM: Constructing Any-Shape Large Language Models for Efficient and Instant Deployment
Nov 15, 2024Motivated by the transformative capabilities of large language models (LLMs) across various natural language tasks, there has been a growing demand to deploy these models effectively across diverse real-world applications and platforms. However, the challenge of efficiently deploying LLMs has become increasingly pronounced due to the varying application-specific performance requirements and the rapid evolution of computational platforms, which feature diverse resource constraints and deployment flows. These varying requirements necessitate LLMs that can adapt their structures (depth and width) for optimal efficiency across different platforms and application specifications. To address this critical gap, we propose AmoebaLLM, a novel framework designed to enable the instant derivation of LLM subnets of arbitrary shapes, which achieve the accuracy-efficiency frontier and can be extracted immediately after a one-time fine-tuning. In this way, AmoebaLLM significantly facilitates rapid deployment tailored to various platforms and applications. Specifically, AmoebaLLM integrates three innovative components: (1) a knowledge-preserving subnet selection strategy that features a dynamic-programming approach for depth shrinking and an importance-driven method for width shrinking; (2) a shape-aware mixture of LoRAs to mitigate gradient conflicts among subnets during fine-tuning; and (3) an in-place distillation scheme with loss-magnitude balancing as the fine-tuning objective. Extensive experiments validate that AmoebaLLM not only sets new standards in LLM adaptability but also successfully delivers subnets that achieve state-of-the-art trade-offs between accuracy and efficiency.