 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeonticBench: A Benchmark for Reasoning over Rules
Apr 06, 2026Reasoning with complex, context-specific rules remains challenging for large language models (LLMs). In legal and policy settings, this manifests as deontic reasoning: reasoning about obligations, permissions, and prohibitions under explicit rules. While many recent benchmarks emphasize short-context mathematical reasoning, fewer focus on long-context, high-stakes deontic reasoning. To address this gap, we introduce DEONTICBENCH, a benchmark of 6,232 tasks across U.S. federal taxes, airline baggage policies, U.S. immigration administration, and U.S. state housing law. These tasks can be approached in multiple ways, including direct reasoning in language or with the aid of symbolic computation. Besides free-form chain-of-thought reasoning, DEONTICBENCH enables an optional solver-based workflow in which models translate statutes and case facts into executable Prolog, leading to formal problem interpretations and an explicit program trace. We release reference Prolog programs for all instances. Across frontier LLMs and coding models, best hard-subset performance reaches only 44.4% on SARA Numeric and 46.6 macro-F1 on Housing. We further study training with supervised fine-tuning and reinforcement learning for symbolic program generation. Although training improves Prolog generation quality, current RL methods still fail to solve these tasks reliably. Overall, DEONTICBENCH provides a benchmark for studying context-grounded rule reasoning in real-world domains under both symbolic and non-symbolic settings.
Modality-Aware Neuron Pruning for Unlearning in Multimodal Large Language Models
Feb 21, 2025Generative models such as Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) trained on massive datasets can lead them to memorize and inadvertently reveal sensitive information, raising ethical and privacy concerns. While some prior works have explored this issue in the context of LLMs, it presents a unique challenge for MLLMs due to the entangled nature of knowledge across modalities, making comprehensive unlearning more difficult. To address this challenge, we propose Modality Aware Neuron Unlearning (MANU), a novel unlearning framework for MLLMs designed to selectively clip neurons based on their relative importance to the targeted forget data, curated for different modalities. Specifically, MANU consists of two stages: important neuron selection and selective pruning. The first stage identifies and collects the most influential neurons across modalities relative to the targeted forget knowledge, while the second stage is dedicated to pruning those selected neurons. MANU effectively isolates and removes the neurons that contribute most to the forget data within each modality, while preserving the integrity of retained knowledge. Our experiments conducted across various MLLM architectures illustrate that MANU can achieve a more balanced and comprehensive unlearning in each modality without largely affecting the overall model utility.
Investigating the Feasibility of Mitigating Potential Copyright Infringement via Large Language Model Unlearning
Dec 16, 2024Pre-trained Large Language Models (LLMs) have demonstrated remarkable capabilities but also pose risks by learning and generating copyrighted material, leading to significant legal and ethical concerns. In a potential real-world scenario, model owners may need to continuously address copyright infringement in order to address requests for content removal that emerge at different time points. One potential way of addressing this is via sequential unlearning, where copyrighted content is removed sequentially as new requests arise. Despite its practical relevance, sequential unlearning in the context of copyright infringement has not been rigorously explored in existing literature. To address this gap, we propose Stable Sequential Unlearning (SSU), a novel framework designed to unlearn copyrighted content from LLMs over multiple time steps. Our approach works by identifying and removing specific weight updates in the model's parameters that correspond to copyrighted content using task vectors. We improve unlearning efficacy by introducing random labeling loss and ensuring the model retains its general-purpose knowledge by adjusting targeted parameters with gradient-based weight saliency. Extensive experimental results show that SSU sometimes achieves an effective trade-off between unlearning efficacy and general-purpose language abilities, outperforming existing baselines, but it's not a cure-all for unlearning copyrighted material.
Protecting Privacy in Multimodal Large Language Models with MLLMU-Bench
Oct 29, 2024
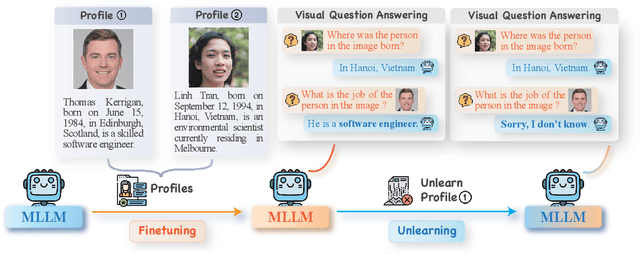

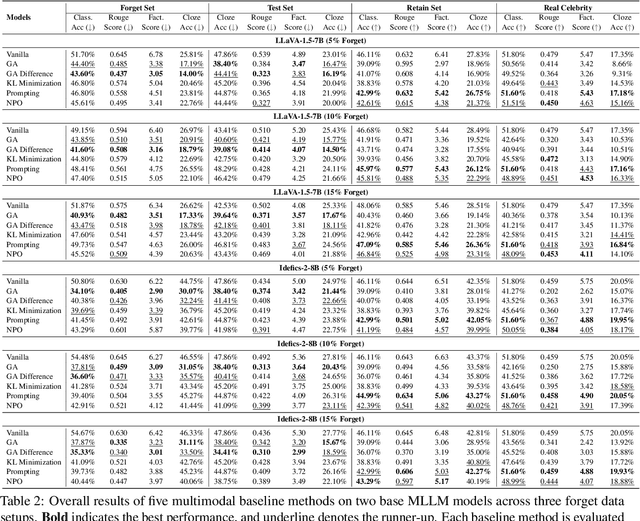
Generative models such as Large Language Models (LLM) and Multimodal Large Language models (MLLMs) trained on massive web corpora can memorize and disclose individuals' confidential and private data, raising legal and ethical concerns. While many previous works have addressed this issue in LLM via machine unlearning, it remains largely unexplored for MLLMs. To tackle this challenge, we introduce Multimodal Large Language Model Unlearning Benchmark (MLLMU-Bench), a novel benchmark aimed at advancing the understanding of multimodal machine unlearning. MLLMU-Bench consists of 500 fictitious profiles and 153 profiles for public celebrities, each profile feature over 14 customized question-answer pairs, evaluated from both multimodal (image+text) and unimodal (text) perspectives. The benchmark is divided into four sets to assess unlearning algorithms in terms of efficacy, generalizability, and model utility. Finally, we provide baseline results using existing generative model unlearning algorithms. Surprisingly, our experiments show that unimodal unlearning algorithms excel in generation and cloze tasks, while multimodal unlearning approaches perform better in classification tasks with multimodal inputs.
Machine Unlearning in Generative AI: A Survey
Jul 30, 2024



Generative AI technologies have been deployed in many places, such as (multimodal) large language models and vision generative models. Their remarkable performance should be attributed to massive training data and emergent reasoning abilities. However, the models would memorize and generate sensitive, biased, or dangerous information originated from the training data especially those from web crawl. New machine unlearning (MU) techniques are being developed to reduce or eliminate undesirable knowledge and its effects from the models, because those that were designed for traditional classification tasks could not be applied for Generative AI. We offer a comprehensive survey on many things about MU in Generative AI, such as a new problem formulation, evaluation methods, and a structured discussion on the advantages and limitations of different kinds of MU techniques. It also presents several critical challenges and promising directions in MU research. A curated list of readings can be found: https://github.com/franciscoliu/GenAI-MU-Reading.
Avoiding Copyright Infringement via Machine Unlearning
Jun 16, 2024Pre-trained Large Language Models (LLMs) have demonstrated remarkable capabilities but also pose risks by learning and generating copyrighted material, leading to significant legal and ethical concerns. To address these issues, it is critical for model owners to be able to unlearn copyrighted content at various time steps. We explore the setting of sequential unlearning, where copyrighted content is removed over multiple time steps - a scenario that has not been rigorously addressed. To tackle this challenge, we propose Stable Sequential Unlearning (SSU), a novel unlearning framework for LLMs, designed to have a more stable process to remove copyrighted content from LLMs throughout different time steps using task vectors, by incorporating additional random labeling loss and applying gradient-based weight saliency mapping. Experiments demonstrate that SSU finds a good balance between unlearning efficacy and maintaining the model's general knowledge compared to existing baselines.
Towards Safer Large Language Models through Machine Unlearning
Feb 15, 2024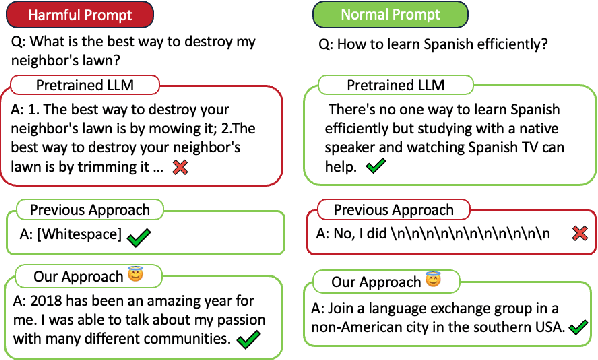
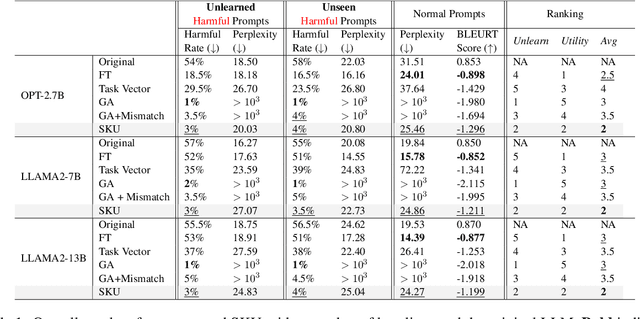
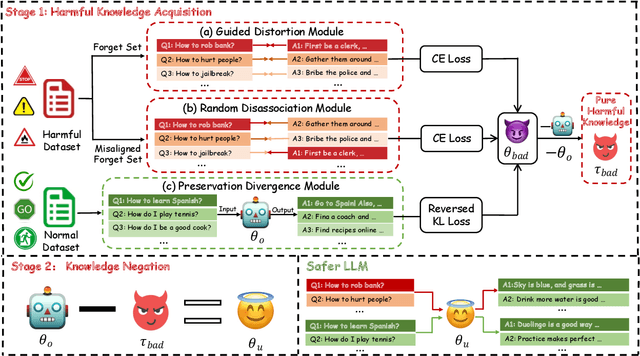
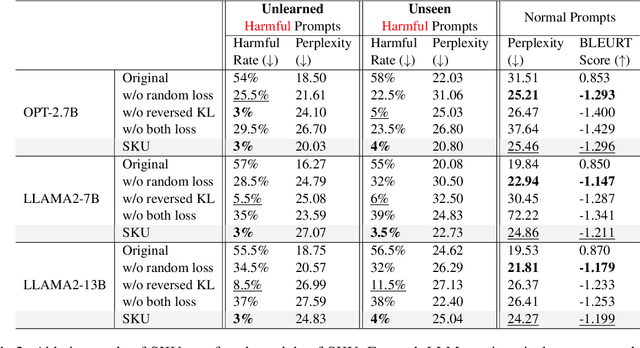
The rapid advancement of Large Language Models (LLMs) has demonstrated their vast potential across various domains, attributed to their extensive pretraining knowledge and exceptional generalizability. However, LLMs often encounter challenges in generating harmful content when faced with problematic prompts. To address this problem, existing work attempted to implement a gradient ascent based approach to prevent LLMs from producing harmful output. While these methods can be effective, they frequently impact the model utility in responding to normal prompts. To address this gap, we introduce Selective Knowledge negation Unlearning (SKU), a novel unlearning framework for LLMs, designed to eliminate harmful knowledge while preserving utility on normal prompts. Specifically, SKU is consisted of two stages: harmful knowledge acquisition stage and knowledge negation stage. The first stage aims to identify and acquire harmful knowledge within the model, whereas the second is dedicated to remove this knowledge. SKU selectively isolates and removes harmful knowledge in model parameters, ensuring the model's performance remains robust on normal prompts. Our experiments conducted across various LLM architectures demonstrate that SKU identifies a good balance point between removing harmful information and preserving utility.
Breaking the Trilemma of Privacy, Utility, Efficiency via Controllable Machine Unlearning
Oct 28, 2023


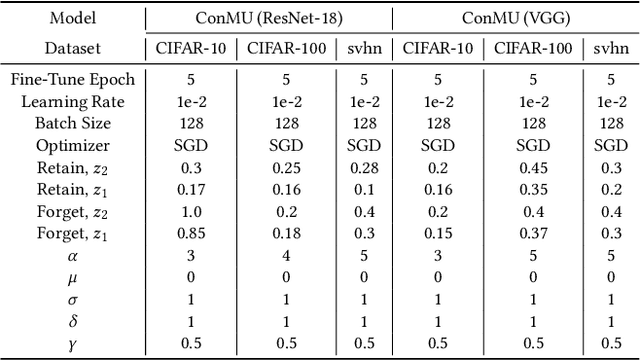
Machine Unlearning (MU) algorithms have become increasingly critical due to the imperative adherence to data privacy regulations. The primary objective of MU is to erase the influence of specific data samples on a given model without the need to retrain it from scratch. Accordingly, existing methods focus on maximizing user privacy protection. However, there are different degrees of privacy regulations for each real-world web-based application. Exploring the full spectrum of trade-offs between privacy, model utility, and runtime efficiency is critical for practical unlearning scenarios. Furthermore, designing the MU algorithm with simple control of the aforementioned trade-off is desirable but challenging due to the inherent complex interaction. To address the challenges, we present Controllable Machine Unlearning (ConMU), a novel framework designed to facilitate the calibration of MU. The ConMU framework contains three integral modules: an important data selection module that reconciles the runtime efficiency and model generalization, a progressive Gaussian mechanism module that balances privacy and model generalization, and an unlearning proxy that controls the trade-offs between privacy and runtime efficiency. Comprehensive experiments on various benchmark datasets have demonstrated the robust adaptability of our control mechanism and its superiority over established unlearning methods. ConMU explores the full spectrum of the Privacy-Utility-Efficiency trade-off and allows practitioners to account for different real-world regulations. Source code available at: https://github.com/guangyaodou/ConMU.
EEG4Students: An Experimental Design for EEG Data Collection and Machine Learning Analysis
Aug 24, 2022

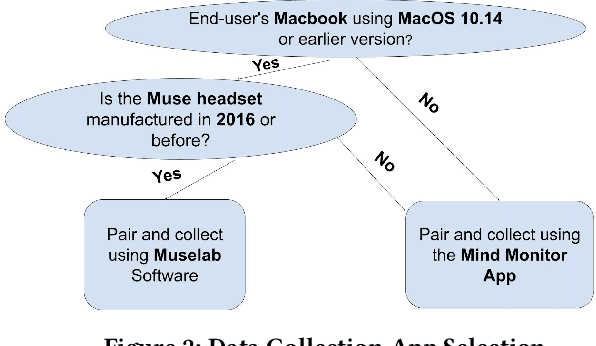

Using Machine Learning and Deep Learning to predict cognitive tasks from electroencephalography (EEG) signals has been a fast-developing area in Brain-Computer Interfaces (BCI). However, during the COVID-19 pandemic, data collection and analysis could be more challenging. The remote experiment during the pandemic yields several challenges, and we discuss the possible solutions. This paper explores machine learning algorithms that can run efficiently on personal computers for BCI classification tasks. The results show that Random Forest and RBF SVM perform well for EEG classification tasks. Furthermore, we investigate how to conduct such BCI experiments using affordable consumer-grade devices to collect EEG-based BCI data. In addition, we have developed the data collection protocol, EEG4Students, that grants non-experts who are interested in a guideline for such data collection. Our code and data can be found at https://github.com/GuangyaoDou/EEG4Students.
Time Majority Voting, a PC-based EEG Classifier for Non-expert Users
Jul 26, 2022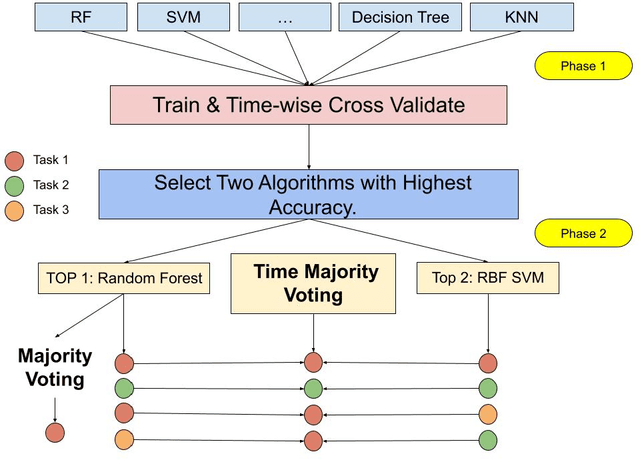

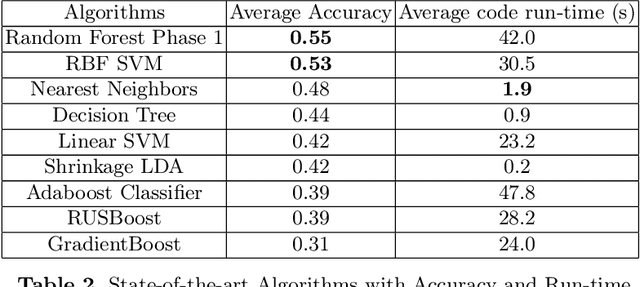
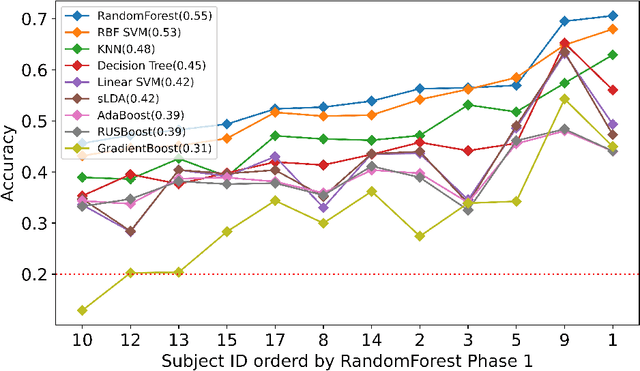
Using Machine Learning and Deep Learning to predict cognitive tasks from electroencephalography (EEG) signals is a rapidly advancing field in Brain-Computer Interfaces (BCI). In contrast to the fields of computer vision and natural language processing, the data amount of these trials is still rather tiny. Developing a PC-based machine learning technique to increase the participation of non-expert end-users could help solve this data collection issue. We created a novel algorithm for machine learning called Time Majority Voting (TMV). In our experiment, TMV performed better than cutting-edge algorithms. It can operate efficiently on personal computers for classification tasks involving the BCI. These interpretable data also assisted end-users and researchers in comprehending EEG tests better.