 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Models Perform the Best When Token Distributions Follow Zipf's Law
Jul 30, 2025Tokenization is a fundamental step in natural language processing (NLP) and other sequence modeling domains, where the choice of vocabulary size significantly impacts model performance. Despite its importance, selecting an optimal vocabulary size remains underexplored, typically relying on heuristics or dataset-specific choices. In this work, we propose a principled method for determining the vocabulary size by analyzing token frequency distributions through Zipf's law. We show that downstream task performance correlates with how closely token distributions follow power-law behavior, and that aligning with Zipfian scaling improves both model efficiency and effectiveness. Extensive experiments across NLP, genomics, and chemistry demonstrate that models consistently achieve peak performance when the token distribution closely adheres to Zipf's law, establishing Zipfian alignment as a robust and generalizable criterion for vocabulary size selection.
Graph Foundation Models: A Comprehensive Survey
May 21, 2025Graph-structured data pervades domains such as social networks, biological systems, knowledge graphs, and recommender systems. While foundation models have transformed natural language processing, vision, and multimodal learning through large-scale pretraining and generalization, extending these capabilities to graphs -- characterized by non-Euclidean structures and complex relational semantics -- poses unique challenges and opens new opportunities. To this end, Graph Foundation Models (GFMs) aim to bring scalable, general-purpose intelligence to structured data, enabling broad transfer across graph-centric tasks and domains. This survey provides a comprehensive overview of GFMs, unifying diverse efforts under a modular framework comprising three key components: backbone architectures, pretraining strategies, and adaptation mechanisms. We categorize GFMs by their generalization scope -- universal, task-specific, and domain-specific -- and review representative methods, key innovations, and theoretical insights within each category. Beyond methodology, we examine theoretical foundations including transferability and emergent capabilities, and highlight key challenges such as structural alignment, heterogeneity, scalability, and evaluation. Positioned at the intersection of graph learning and general-purpose AI, GFMs are poised to become foundational infrastructure for open-ended reasoning over structured data. This survey consolidates current progress and outlines future directions to guide research in this rapidly evolving field. Resources are available at https://github.com/Zehong-Wang/Awesome-Foundation-Models-on-Graphs.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025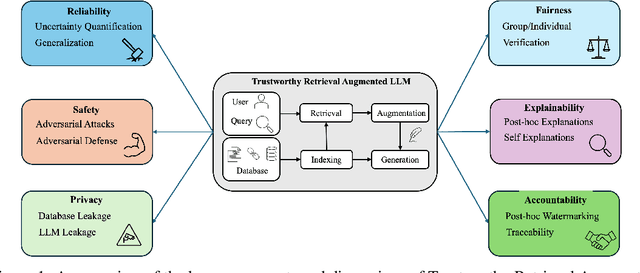


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Protecting Privacy in Multimodal Large Language Models with MLLMU-Bench
Oct 29, 2024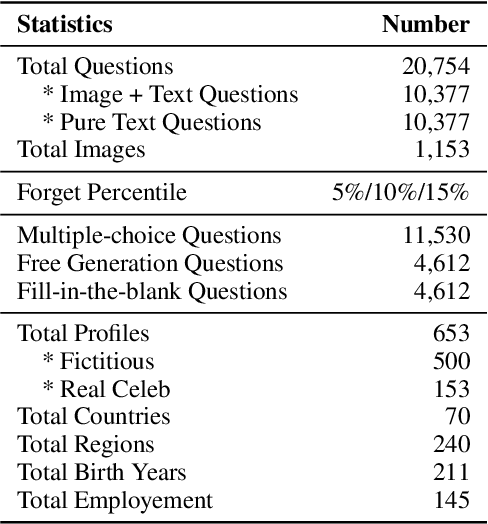
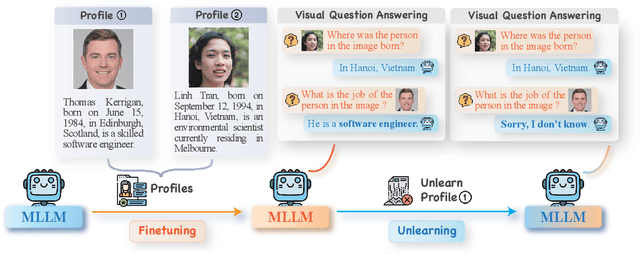

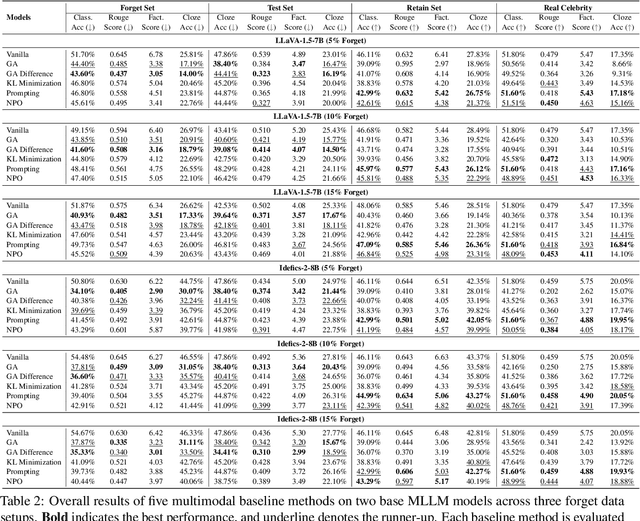
Generative models such as Large Language Models (LLM) and Multimodal Large Language models (MLLMs) trained on massive web corpora can memorize and disclose individuals' confidential and private data, raising legal and ethical concerns. While many previous works have addressed this issue in LLM via machine unlearning, it remains largely unexplored for MLLMs. To tackle this challenge, we introduce Multimodal Large Language Model Unlearning Benchmark (MLLMU-Bench), a novel benchmark aimed at advancing the understanding of multimodal machine unlearning. MLLMU-Bench consists of 500 fictitious profiles and 153 profiles for public celebrities, each profile feature over 14 customized question-answer pairs, evaluated from both multimodal (image+text) and unimodal (text) perspectives. The benchmark is divided into four sets to assess unlearning algorithms in terms of efficacy, generalizability, and model utility. Finally, we provide baseline results using existing generative model unlearning algorithms. Surprisingly, our experiments show that unimodal unlearning algorithms excel in generation and cloze tasks, while multimodal unlearning approaches perform better in classification tasks with multimodal inputs.
Enhancing Mathematical Reasoning in LLMs by Stepwise Correction
Oct 16, 2024



Best-of-N decoding methods instruct large language models (LLMs) to generate multiple solutions, score each using a scoring function, and select the highest scored as the final answer to mathematical reasoning problems. However, this repeated independent process often leads to the same mistakes, making the selected solution still incorrect. We propose a novel prompting method named Stepwise Correction (StepCo) that helps LLMs identify and revise incorrect steps in their generated reasoning paths. It iterates verification and revision phases that employ a process-supervised verifier. The verify-then-revise process not only improves answer correctness but also reduces token consumption with fewer paths needed to generate. With StepCo, a series of LLMs demonstrate exceptional performance. Notably, using GPT-4o as the backend LLM, StepCo achieves an average accuracy of 94.1 across eight datasets, significantly outperforming the state-of-the-art Best-of-N method by +2.4, while reducing token consumption by 77.8%.
CodeTaxo: Enhancing Taxonomy Expansion with Limited Examples via Code Language Prompts
Aug 17, 2024



Taxonomies play a crucial role in various applications by providing a structural representation of knowledge. The task of taxonomy expansion involves integrating emerging concepts into existing taxonomies by identifying appropriate parent concepts for these new query concepts. Previous approaches typically relied on self-supervised methods that generate annotation data from existing taxonomies. However, these methods are less effective when the existing taxonomy is small (fewer than 100 entities). In this work, we introduce \textsc{CodeTaxo}, a novel approach that leverages large language models through code language prompts to capture the taxonomic structure. Extensive experiments on five real-world benchmarks from different domains demonstrate that \textsc{CodeTaxo} consistently achieves superior performance across all evaluation metrics, significantly outperforming previous state-of-the-art methods. The code and data are available at \url{https://github.com/QingkaiZeng/CodeTaxo-Pub}.
A Psychology-based Unified Dynamic Framework for Curriculum Learning
Aug 09, 2024
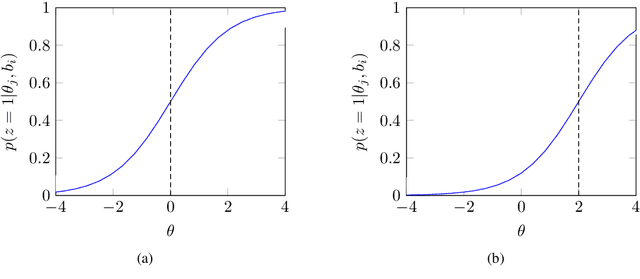
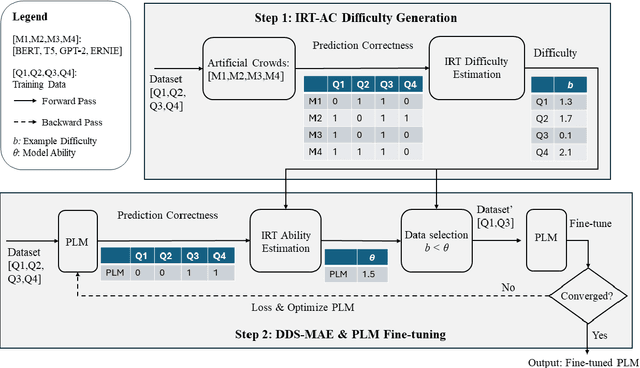

Directly learning from examples of random difficulty levels is often challenging for both humans and machine learning models. A more effective strategy involves exposing learners to examples in a progressive order, from easy to difficult. Curriculum Learning (CL) has been proposed to implement this strategy in machine learning model training. However, two key challenges persist in CL framework design: defining the difficulty of training data and determining the appropriate amount of data to input at each training step. This paper presents a Psychology-based Unified Dynamic Framework for Curriculum Learning (PUDF), drawing inspiration from psychometrics. We quantify the difficulty of training data by applying Item Response Theory (IRT) to responses from Artificial Crowds (AC). This theory-driven IRT-AC approach leads to global (i.e., model-independent) and interpretable difficulty values. Leveraging IRT, we propose a Dynamic Data Selection via Model Ability Estimation (DDS-MAE) strategy to schedule the appropriate amount of data during model training. Since our difficulty labeling and model ability estimation are based on a consistent theory, namely IRT, their values are comparable within the same scope, potentially leading to a faster convergence compared to the other CL methods. Experimental results demonstrate that fine-tuning pre-trained language models with PUDF enhances their performance on the GLUE benchmark. Moreover, PUDF surpasses other state-of-the-art (SOTA) CL methods on the GLUE benchmark. We further explore the components of PUDF, namely the difficulty measurer (IRT-AC) and the training scheduler (DDS-MAE) qualitatively and quantitatively. Lastly, we conduct an ablation study to clarify which components of PUDF contribute to faster convergence and higher accuracy.
Large Language Models Can Self-Correct with Minimal Effort
May 23, 2024



Intrinsic self-correct was a method that instructed large language models (LLMs) to verify and correct their responses without external feedback. Unfortunately, the study concluded that the LLMs could not self-correct reasoning yet. We find that a simple yet effective verification method can unleash inherent capabilities of the LLMs. That is to mask a key condition in the question, add the current response to construct a verification question, and predict the condition to verify the response. The condition can be an entity in an open-domain question or a numeric value in a math question, which requires minimal effort (via prompting) to identify. We propose an iterative verify-then-correct framework to progressively identify and correct (probably) false responses, named ProCo. We conduct experiments on three reasoning tasks. On average, ProCo, with GPT-3.5-Turbo as the backend LLM, yields $+6.8$ exact match on four open-domain question answering datasets, $+14.1$ accuracy on three arithmetic reasoning datasets, and $+9.6$ accuracy on a commonsense reasoning dataset, compared to Self-Correct.
ChatEL: Entity Linking with Chatbots
Feb 20, 2024Entity Linking (EL) is an essential and challenging task in natural language processing that seeks to link some text representing an entity within a document or sentence with its corresponding entry in a dictionary or knowledge base. Most existing approaches focus on creating elaborate contextual models that look for clues the words surrounding the entity-text to help solve the linking problem. Although these fine-tuned language models tend to work, they can be unwieldy, difficult to train, and do not transfer well to other domains. Fortunately, Large Language Models (LLMs) like GPT provide a highly-advanced solution to the problems inherent in EL models, but simply naive prompts to LLMs do not work well. In the present work, we define ChatEL, which is a three-step framework to prompt LLMs to return accurate results. Overall the ChatEL framework improves the average F1 performance across 10 datasets by more than 2%. Finally, a thorough error analysis shows many instances with the ground truth labels were actually incorrect, and the labels predicted by ChatEL were actually correct. This indicates that the quantitative results presented in this paper may be a conservative estimate of the actual performance. All data and code are available as an open-source package on GitHub at https://github.com/yifding/In_Context_EL.
Chain-of-Layer: Iteratively Prompting Large Language Models for Taxonomy Induction from Limited Examples
Feb 12, 2024



Automatic taxonomy induction is crucial for web search, recommendation systems, and question answering. Manual curation of taxonomies is expensive in terms of human effort, making automatic taxonomy construction highly desirable. In this work, we introduce Chain-of-Layer which is an in-context learning framework designed to induct taxonomies from a given set of entities. Chain-of-Layer breaks down the task into selecting relevant candidate entities in each layer and gradually building the taxonomy from top to bottom. To minimize errors, we introduce the Ensemble-based Ranking Filter to reduce the hallucinated content generated at each iteration. Through extensive experiments, we demonstrate that Chain-of-Layer achieves state-of-the-art performance on four real-world benchmarks.