 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models
May 25, 2025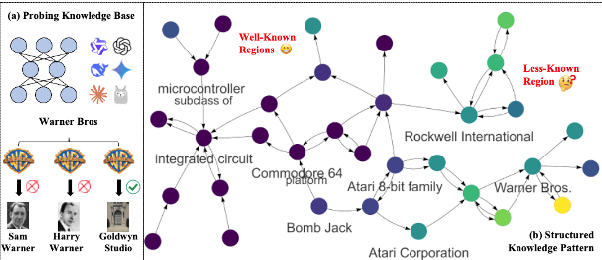
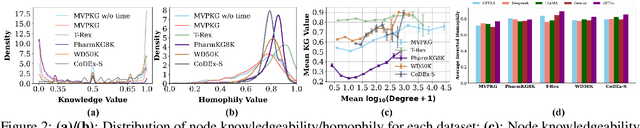
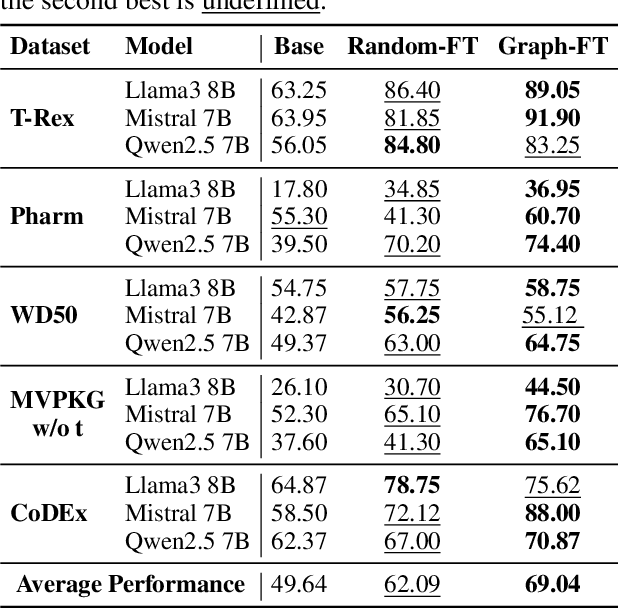
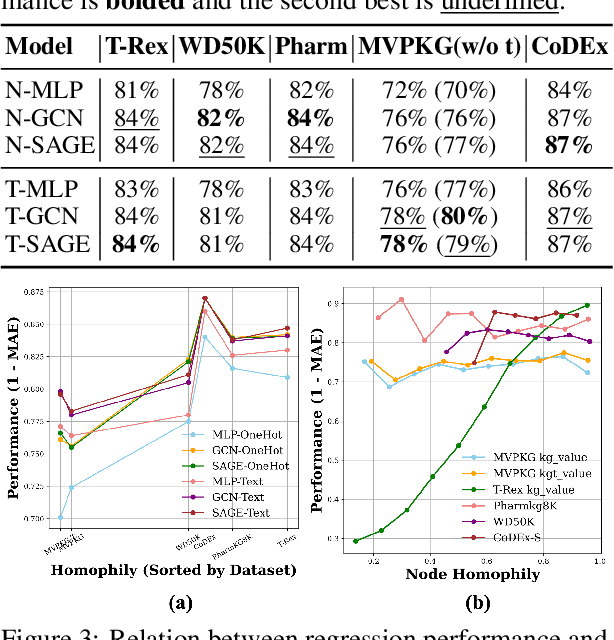
Large language models have been extensively studied as neural knowledge bases for their knowledge access, editability, reasoning, and explainability. However, few works focus on the structural patterns of their knowledge. Motivated by this gap, we investigate these structural patterns from a graph perspective. We quantify the knowledge of LLMs at both the triplet and entity levels, and analyze how it relates to graph structural properties such as node degree. Furthermore, we uncover the knowledge homophily, where topologically close entities exhibit similar levels of knowledgeability, which further motivates us to develop graph machine learning models to estimate entity knowledge based on its local neighbors. This model further enables valuable knowledge checking by selecting triplets less known to LLMs. Empirical results show that using selected triplets for fine-tuning leads to superior performance.
Mixture of Structural-and-Textual Retrieval over Text-rich Graph Knowledge Bases
Feb 27, 2025Text-rich Graph Knowledge Bases (TG-KBs) have become increasingly crucial for answering queries by providing textual and structural knowledge. However, current retrieval methods often retrieve these two types of knowledge in isolation without considering their mutual reinforcement and some hybrid methods even bypass structural retrieval entirely after neighboring aggregation. To fill in this gap, we propose a Mixture of Structural-and-Textual Retrieval (MoR) to retrieve these two types of knowledge via a Planning-Reasoning-Organizing framework. In the Planning stage, MoR generates textual planning graphs delineating the logic for answering queries. Following planning graphs, in the Reasoning stage, MoR interweaves structural traversal and textual matching to obtain candidates from TG-KBs. In the Organizing stage, MoR further reranks fetched candidates based on their structural trajectory. Extensive experiments demonstrate the superiority of MoR in harmonizing structural and textual retrieval with insights, including uneven retrieving performance across different query logics and the benefits of integrating structural trajectories for candidate reranking. Our code is available at https://github.com/Yoega/MoR.
RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
Feb 17, 2025Retrieval-Augmented Generation (RAG) enhances the performance of LLMs across various tasks by retrieving relevant information from external sources, particularly on text-based data. For structured data, such as knowledge graphs, GraphRAG has been widely used to retrieve relevant information. However, recent studies have revealed that structuring implicit knowledge from text into graphs can benefit certain tasks, extending the application of GraphRAG from graph data to general text-based data. Despite their successful extensions, most applications of GraphRAG for text data have been designed for specific tasks and datasets, lacking a systematic evaluation and comparison between RAG and GraphRAG on widely used text-based benchmarks. In this paper, we systematically evaluate RAG and GraphRAG on well-established benchmark tasks, such as Question Answering and Query-based Summarization. Our results highlight the distinct strengths of RAG and GraphRAG across different tasks and evaluation perspectives. Inspired by these observations, we investigate strategies to integrate their strengths to improve downstream tasks. Additionally, we provide an in-depth discussion of the shortcomings of current GraphRAG approaches and outline directions for future research.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025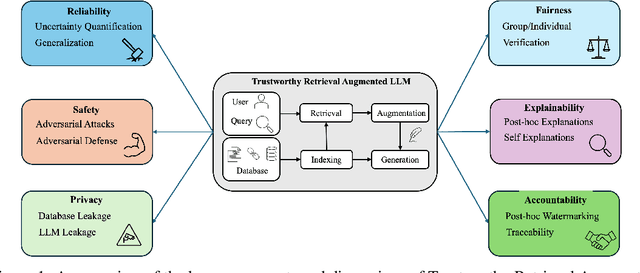
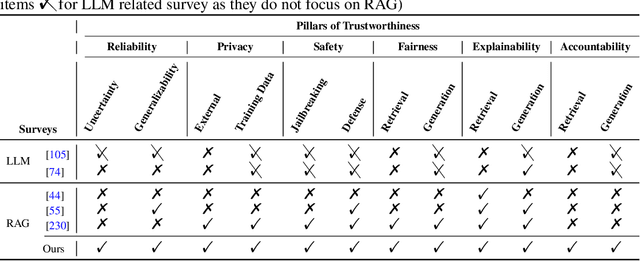


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Retrieval-Augmented Generation with Graphs (GraphRAG)
Jan 08, 2025



Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.