 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime to REFLECT: Can We Trust LLM Judges for Evidence-based Research Agents?
May 18, 2026Deep research agents increasingly automate complex information-seeking tasks, producing evidence-grounded reports via multi-step reasoning, tool use, and synthesis. Their growing role demands scalable, reliable evaluation, positioning LLM-as-judge as a supervision paradigm for assessing factual accuracy, evidence use, and reasoning quality. Yet the reliability of these judges for deep research agents remains poorly understood, posing a critical meta-evaluation problem: before deploying LLM judges to supervise research agents, we must first evaluate the judges themselves. Existing meta-evaluations fall short in two ways: (1) reliance on coarse, subjective human-preference agreement; (2) focus on instruction-following or verifiable tasks, leaving open-ended agent executions unexplored. To address these gaps, we introduce REFLECT (REliable Fine-grained LLM judge Evaluation via Controlled inTervention), a meta-evaluation benchmark targeting fine-grained failure detection in agentic environments. REFLECT defines a detailed taxonomy of process- and outcome-level failure modes, instantiated by performing controlled and localized interventions on quality-screened agent execution traces. This yields verifiable, comprehensive, and fine-grained instances for validating the judge models. Our experiments show that current LLM judges remain unreliable: even the best-performing models achieve overall accuracies below 55% across reasoning, tool-use, and report-quality failures, with especially poor performance on evidence verification. Together, our taxonomy and findings expose systematic judge limitations, reveal tradeoffs in cost and reliability, and offer actionable guidance for building more reliable evaluation pipelines for deep research agents.
A Survey on LLM-based Conversational User Simulation
Apr 27, 2026User simulation has long played a vital role in computer science due to its potential to support a wide range of applications. Language, as the primary medium of human communication, forms the foundation of social interaction and behavior. Consequently, simulating conversational behavior has become a key area of study. Recent advancements in large language models (LLMs) have significantly catalyzed progress in this domain by enabling high-fidelity generation of synthetic user conversation. In this paper, we survey recent advancements in LLM-based conversational user simulation. We introduce a novel taxonomy covering user granularity and simulation objectives. Additionally, we systematically analyze core techniques and evaluation methodologies. We aim to keep the research community informed of the latest advancements in conversational user simulation and to further facilitate future research by identifying open challenges and organizing existing work under a unified framework.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025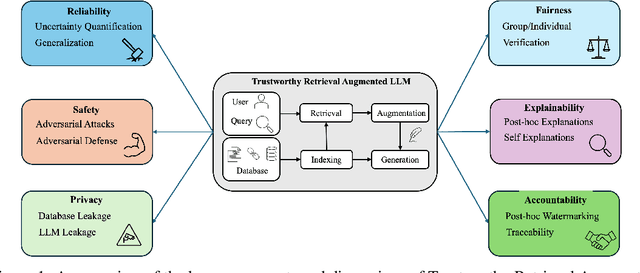
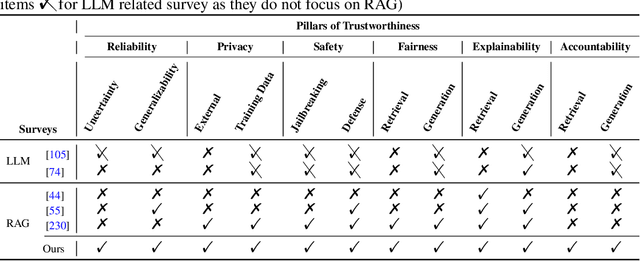


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Sensor2Text: Enabling Natural Language Interactions for Daily Activity Tracking Using Wearable Sensors
Oct 26, 2024Visual Question-Answering, a technology that generates textual responses from an image and natural language question, has progressed significantly. Notably, it can aid in tracking and inquiring about daily activities, crucial in healthcare monitoring, especially for elderly patients or those with memory disabilities. However, video poses privacy concerns and has a limited field of view. This paper presents Sensor2Text, a model proficient in tracking daily activities and engaging in conversations using wearable sensors. The approach outlined here tackles several challenges, including low information density in wearable sensor data, insufficiency of single wearable sensors in human activities recognition, and model's limited capacity for Question-Answering and interactive conversations. To resolve these obstacles, transfer learning and student-teacher networks are utilized to leverage knowledge from visual-language models. Additionally, an encoder-decoder neural network model is devised to jointly process language and sensor data for conversational purposes. Furthermore, Large Language Models are also utilized to enable interactive capabilities. The model showcases the ability to identify human activities and engage in Q\&A dialogues using various wearable sensor modalities. It performs comparably to or better than existing visual-language models in both captioning and conversational tasks. To our knowledge, this represents the first model capable of conversing about wearable sensor data, offering an innovative approach to daily activity tracking that addresses privacy and field-of-view limitations associated with current vision-based solutions.
Large Language Model-based Augmentation for Imbalanced Node Classification on Text-Attributed Graphs
Oct 22, 2024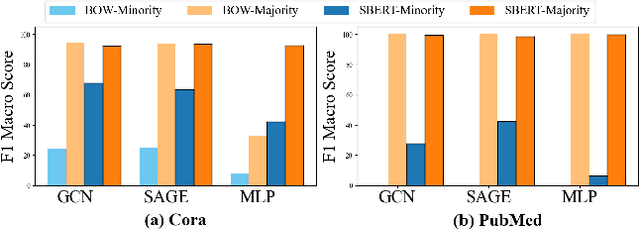
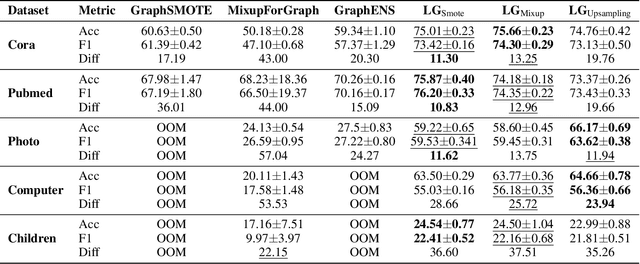

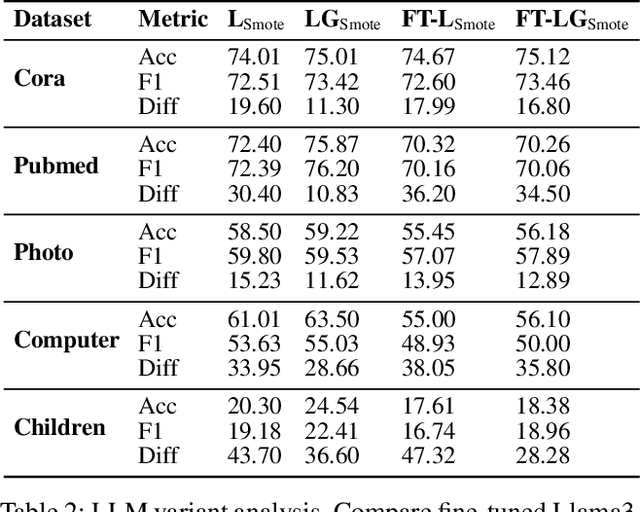
Node classification on graphs frequently encounters the challenge of class imbalance, leading to biased performance and posing significant risks in real-world applications. Although several data-centric solutions have been proposed, none of them focus on Text-Attributed Graphs (TAGs), and therefore overlook the potential of leveraging the rich semantics encoded in textual features for boosting the classification of minority nodes. Given this crucial gap, we investigate the possibility of augmenting graph data in the text space, leveraging the textual generation power of Large Language Models (LLMs) to handle imbalanced node classification on TAGs. Specifically, we propose a novel approach called LA-TAG (LLM-based Augmentation on Text-Attributed Graphs), which prompts LLMs to generate synthetic texts based on existing node texts in the graph. Furthermore, to integrate these synthetic text-attributed nodes into the graph, we introduce a text-based link predictor to connect the synthesized nodes with the existing nodes. Our experiments across multiple datasets and evaluation metrics show that our framework significantly outperforms traditional non-textual-based data augmentation strategies and specific node imbalance solutions. This highlights the promise of using LLMs to resolve imbalance issues on TAGs.