 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
Nov 16, 2025Optimizing recommender systems for objectives beyond accuracy, such as diversity, novelty, and personalization, is crucial for long-term user satisfaction. To this end, industrial practitioners have accumulated vast amounts of structured domain knowledge, which we term human priors (e.g., item taxonomies, temporal patterns). This knowledge is typically applied through post-hoc adjustments during ranking or post-ranking. However, this approach remains decoupled from the core model learning, which is particularly undesirable as the industry shifts to end-to-end generative recommendation foundation models. On the other hand, many methods targeting these beyond-accuracy objectives often require architecture-specific modifications and discard these valuable human priors by learning user intent in a fully unsupervised manner. Instead of discarding the human priors accumulated over years of practice, we introduce a backbone-agnostic framework that seamlessly integrates these human priors directly into the end-to-end training of generative recommenders. With lightweight, prior-conditioned adapter heads inspired by efficient LLM decoding strategies, our approach guides the model to disentangle user intent along human-understandable axes (e.g., interaction types, long- vs. short-term interests). We also introduce a hierarchical composition strategy for modeling complex interactions across different prior types. Extensive experiments on three large-scale datasets demonstrate that our method significantly enhances both accuracy and beyond-accuracy objectives. We also show that human priors allow the backbone model to more effectively leverage longer context lengths and larger model sizes.
CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025


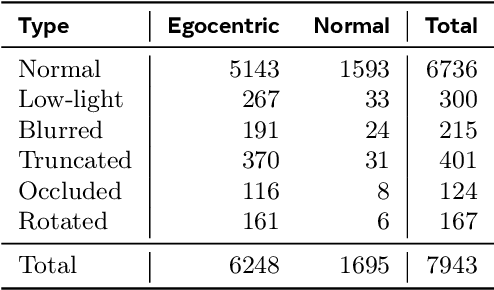
Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
S'MoRE: Structural Mixture of Residual Experts for LLM Fine-tuning
Apr 08, 2025Fine-tuning pre-trained large language models (LLMs) presents a dual challenge of balancing parameter efficiency and model capacity. Existing methods like low-rank adaptations (LoRA) are efficient but lack flexibility, while Mixture-of-Experts (MoE) architectures enhance model capacity at the cost of more & under-utilized parameters. To address these limitations, we propose Structural Mixture of Residual Experts (S'MoRE), a novel framework that seamlessly integrates the efficiency of LoRA with the flexibility of MoE. Specifically, S'MoRE employs hierarchical low-rank decomposition of expert weights, yielding residuals of varying orders interconnected in a multi-layer structure. By routing input tokens through sub-trees of residuals, S'MoRE emulates the capacity of many experts by instantiating and assembling just a few low-rank matrices. We craft the inter-layer propagation of S'MoRE's residuals as a special type of Graph Neural Network (GNN), and prove that under similar parameter budget, S'MoRE improves "structural flexibility" of traditional MoE (or Mixture-of-LoRA) by exponential order. Comprehensive theoretical analysis and empirical results demonstrate that S'MoRE achieves superior fine-tuning performance, offering a transformative approach for efficient LLM adaptation.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025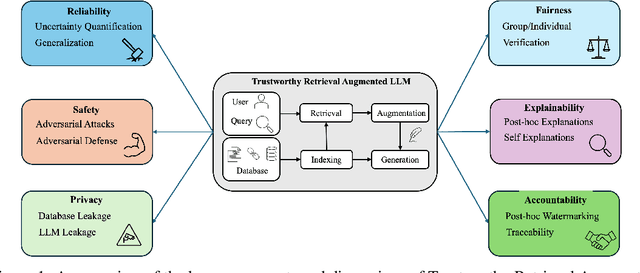
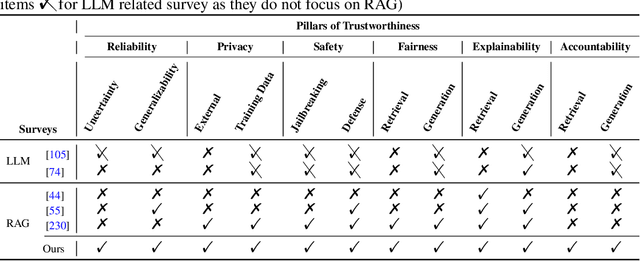


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Retrieval-Augmented Generation with Graphs (GraphRAG)
Jan 08, 2025



Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.
Retrieval Augmentation via User Interest Clustering
Aug 07, 2024
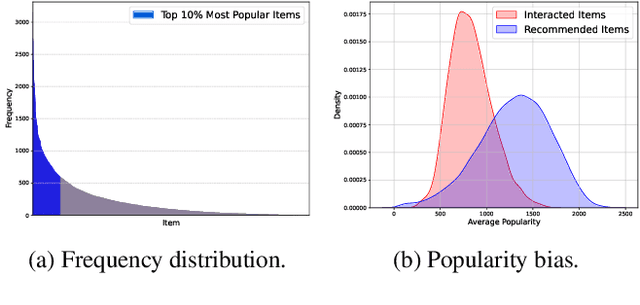
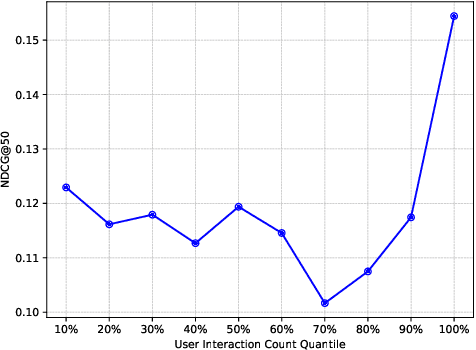

Many existing industrial recommender systems are sensitive to the patterns of user-item engagement. Light users, who interact less frequently, correspond to a data sparsity problem, making it difficult for the system to accurately learn and represent their preferences. On the other hand, heavy users with rich interaction history often demonstrate a variety of niche interests that are hard to be precisely captured under the standard "user-item" similarity measurement. Moreover, implementing these systems in an industrial environment necessitates that they are resource-efficient and scalable to process web-scale data under strict latency constraints. In this paper, we address these challenges by introducing an intermediate "interest" layer between users and items. We propose a novel approach that efficiently constructs user interest and facilitates low computational cost inference by clustering engagement graphs and incorporating user-interest attention. This method enhances the understanding of light users' preferences by linking them with heavy users. By integrating user-interest attention, our approach allows a more personalized similarity metric, adept at capturing the complex dynamics of user-item interactions. The use of interest as an intermediary layer fosters a balance between scalability and expressiveness in the model. Evaluations on two public datasets reveal that our method not only achieves improved recommendation performance but also demonstrates enhanced computational efficiency compared to item-level attention models. Our approach has also been deployed in multiple products at Meta, facilitating short-form video related recommendation.
TASER: Temporal Adaptive Sampling for Fast and Accurate Dynamic Graph Representation Learning
Feb 18, 2024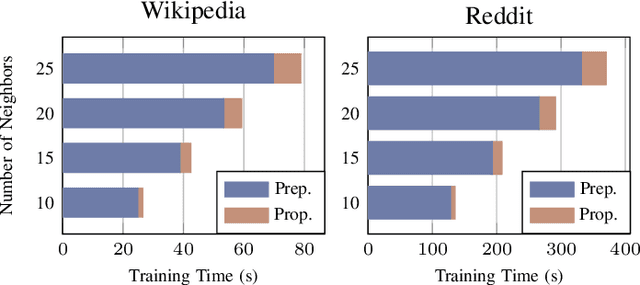
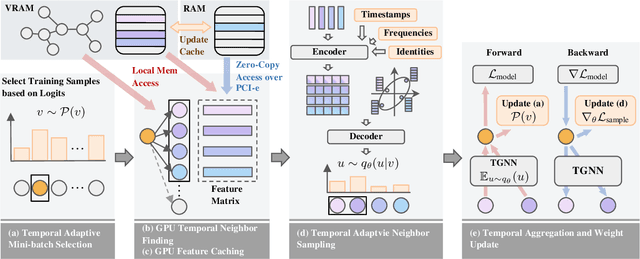
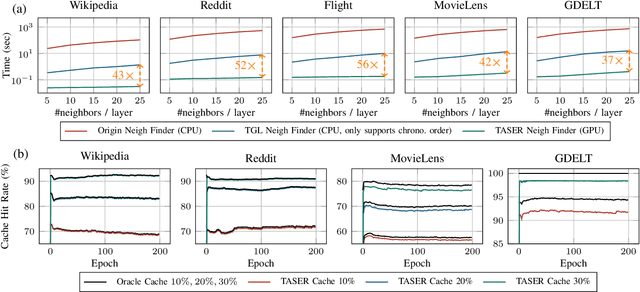
Recently, Temporal Graph Neural Networks (TGNNs) have demonstrated state-of-the-art performance in various high-impact applications, including fraud detection and content recommendation. Despite the success of TGNNs, they are prone to the prevalent noise found in real-world dynamic graphs like time-deprecated links and skewed interaction distribution. The noise causes two critical issues that significantly compromise the accuracy of TGNNs: (1) models are supervised by inferior interactions, and (2) noisy input induces high variance in the aggregated messages. However, current TGNN denoising techniques do not consider the diverse and dynamic noise pattern of each node. In addition, they also suffer from the excessive mini-batch generation overheads caused by traversing more neighbors. We believe the remedy for fast and accurate TGNNs lies in temporal adaptive sampling. In this work, we propose TASER, the first adaptive sampling method for TGNNs optimized for accuracy, efficiency, and scalability. TASER adapts its mini-batch selection based on training dynamics and temporal neighbor selection based on the contextual, structural, and temporal properties of past interactions. To alleviate the bottleneck in mini-batch generation, TASER implements a pure GPU-based temporal neighbor finder and a dedicated GPU feature cache. We evaluate the performance of TASER using two state-of-the-art backbone TGNNs. On five popular datasets, TASER outperforms the corresponding baselines by an average of 2.3% in Mean Reciprocal Rank (MRR) while achieving an average of 5.1x speedup in training time.
Mixture of Weak & Strong Experts on Graphs
Nov 09, 2023Realistic graphs contain both rich self-features of nodes and informative structures of neighborhoods, jointly handled by a GNN in the typical setup. We propose to decouple the two modalities by mixture of weak and strong experts (Mowst), where the weak expert is a light-weight Multi-layer Perceptron (MLP), and the strong expert is an off-the-shelf Graph Neural Network (GNN). To adapt the experts' collaboration to different target nodes, we propose a "confidence" mechanism based on the dispersion of the weak expert's prediction logits. The strong expert is conditionally activated when either the node's classification relies on neighborhood information, or the weak expert has low model quality. We reveal interesting training dynamics by analyzing the influence of the confidence function on loss: our training algorithm encourages the specialization of each expert by effectively generating soft splitting of the graph. In addition, our "confidence" design imposes a desirable bias toward the strong expert to benefit from GNN's better generalization capability. Mowst is easy to optimize and achieves strong expressive power, with a computation cost comparable to a single GNN. Empirically, Mowst shows significant accuracy improvement on 6 standard node classification benchmarks (including both homophilous and heterophilous graphs).
Deceptive Fairness Attacks on Graphs via Meta Learning
Oct 24, 2023We study deceptive fairness attacks on graphs to answer the following question: How can we achieve poisoning attacks on a graph learning model to exacerbate the bias deceptively? We answer this question via a bi-level optimization problem and propose a meta learning-based framework named FATE. FATE is broadly applicable with respect to various fairness definitions and graph learning models, as well as arbitrary choices of manipulation operations. We further instantiate FATE to attack statistical parity and individual fairness on graph neural networks. We conduct extensive experimental evaluations on real-world datasets in the task of semi-supervised node classification. The experimental results demonstrate that FATE could amplify the bias of graph neural networks with or without fairness consideration while maintaining the utility on the downstream task. We hope this paper provides insights into the adversarial robustness of fair graph learning and can shed light on designing robust and fair graph learning in future studies.
Resprompt: Residual Connection Prompting Advances Multi-Step Reasoning in Large Language Models
Oct 07, 2023Chain-of-thought (CoT) prompting, which offers step-by-step problem-solving rationales, has impressively unlocked the reasoning potential of large language models (LLMs). Yet, the standard CoT is less effective in problems demanding multiple reasoning steps. This limitation arises from the complex reasoning process in multi-step problems: later stages often depend on the results of several steps earlier, not just the results of the immediately preceding step. Such complexities suggest the reasoning process is naturally represented as a graph. The almost linear and straightforward structure of CoT prompting, however, struggles to capture this complex reasoning graph. To address this challenge, we propose Residual Connection Prompting (RESPROMPT), a new prompting strategy that advances multi-step reasoning in LLMs. Our key idea is to reconstruct the reasoning graph within prompts. We achieve this by integrating necessary connections-links present in the reasoning graph but missing in the linear CoT flow-into the prompts. Termed "residual connections", these links are pivotal in morphing the linear CoT structure into a graph representation, effectively capturing the complex reasoning graphs inherent in multi-step problems. We evaluate RESPROMPT on six benchmarks across three diverse domains: math, sequential, and commonsense reasoning. For the open-sourced LLaMA family of models, RESPROMPT yields a significant average reasoning accuracy improvement of 12.5% on LLaMA-65B and 6.8% on LLaMA2-70B. Breakdown analysis further highlights RESPROMPT particularly excels in complex multi-step reasoning: for questions demanding at least five reasoning steps, RESPROMPT outperforms the best CoT based benchmarks by a remarkable average improvement of 21.1% on LLaMA-65B and 14.3% on LLaMA2-70B. Through extensive ablation studies and analyses, we pinpoint how to most effectively build residual connections.