 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-Agent: Adaptive Graph Reasoning Agent under Incomplete Knowledge
Dec 16, 2025

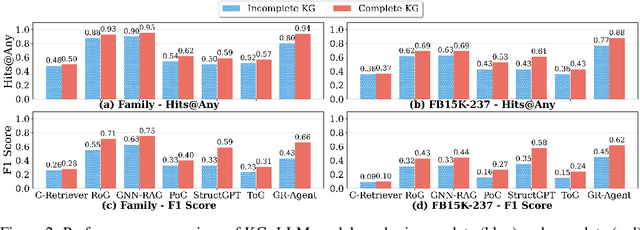

Large language models (LLMs) achieve strong results on knowledge graph question answering (KGQA), but most benchmarks assume complete knowledge graphs (KGs) where direct supporting triples exist. This reduces evaluation to shallow retrieval and overlooks the reality of incomplete KGs, where many facts are missing and answers must be inferred from existing facts. We bridge this gap by proposing a methodology for constructing benchmarks under KG incompleteness, which removes direct supporting triples while ensuring that alternative reasoning paths required to infer the answer remain. Experiments on benchmarks constructed using our methodology show that existing methods suffer consistent performance degradation under incompleteness, highlighting their limited reasoning ability. To overcome this limitation, we present the Adaptive Graph Reasoning Agent (GR-Agent). It first constructs an interactive environment from the KG, and then formalizes KGQA as agent environment interaction within this environment. GR-Agent operates over an action space comprising graph reasoning tools and maintains a memory of potential supporting reasoning evidence, including relevant relations and reasoning paths. Extensive experiments demonstrate that GR-Agent outperforms non-training baselines and performs comparably to training-based methods under both complete and incomplete settings.
Defect-aware Hybrid Prompt Optimization via Progressive Tuning for Zero-Shot Multi-type Anomaly Detection and Segmentation
Dec 10, 2025



Recent vision language models (VLMs) like CLIP have demonstrated impressive anomaly detection performance under significant distribution shift by utilizing high-level semantic information through text prompts. However, these models often neglect fine-grained details, such as which kind of anomalies, like "hole", "cut", "scratch" that could provide more specific insight into the nature of anomalies. We argue that recognizing fine-grained anomaly types 1) enriches the representation of "abnormal" with structured semantics, narrowing the gap between coarse anomaly signals and fine-grained defect categories; 2) enables manufacturers to understand the root causes of the anomaly and implement more targeted and appropriate corrective measures quickly. While incorporating such detailed semantic information is crucial, designing handcrafted prompts for each defect type is both time-consuming and susceptible to human bias. For this reason, we introduce DAPO, a novel approach for Defect-aware Prompt Optimization based on progressive tuning for the zero-shot multi-type and binary anomaly detection and segmentation under distribution shifts. Our approach aligns anomaly-relevant image features with their corresponding text semantics by learning hybrid defect-aware prompts with both fixed textual anchors and learnable token embeddings. We conducted experiments on public benchmarks (MPDD, VisA, MVTec-AD, MAD, and Real-IAD) and an internal dataset. The results suggest that compared to the baseline models, DAPO achieves a 3.7% average improvement in AUROC and average precision metrics at the image level under distribution shift, and a 6.5% average improvement in localizing novel anomaly types under zero-shot settings.
What Breaks Knowledge Graph based RAG? Empirical Insights into Reasoning under Incomplete Knowledge
Aug 11, 2025Knowledge Graph-based Retrieval-Augmented Generation (KG-RAG) is an increasingly explored approach for combining the reasoning capabilities of large language models with the structured evidence of knowledge graphs. However, current evaluation practices fall short: existing benchmarks often include questions that can be directly answered using existing triples in KG, making it unclear whether models perform reasoning or simply retrieve answers directly. Moreover, inconsistent evaluation metrics and lenient answer matching criteria further obscure meaningful comparisons. In this work, we introduce a general method for constructing benchmarks, together with an evaluation protocol, to systematically assess KG-RAG methods under knowledge incompleteness. Our empirical results show that current KG-RAG methods have limited reasoning ability under missing knowledge, often rely on internal memorization, and exhibit varying degrees of generalization depending on their design.
MultiADS: Defect-aware Supervision for Multi-type Anomaly Detection and Segmentation in Zero-Shot Learning
Apr 09, 2025Precise optical inspection in industrial applications is crucial for minimizing scrap rates and reducing the associated costs. Besides merely detecting if a product is anomalous or not, it is crucial to know the distinct type of defect, such as a bent, cut, or scratch. The ability to recognize the "exact" defect type enables automated treatments of the anomalies in modern production lines. Current methods are limited to solely detecting whether a product is defective or not without providing any insights on the defect type, nevertheless detecting and identifying multiple defects. We propose MultiADS, a zero-shot learning approach, able to perform Multi-type Anomaly Detection and Segmentation. The architecture of MultiADS comprises CLIP and extra linear layers to align the visual- and textual representation in a joint feature space. To the best of our knowledge, our proposal, is the first approach to perform a multi-type anomaly segmentation task in zero-shot learning. Contrary to the other baselines, our approach i) generates specific anomaly masks for each distinct defect type, ii) learns to distinguish defect types, and iii) simultaneously identifies multiple defect types present in an anomalous product. Additionally, our approach outperforms zero/few-shot learning SoTA methods on image-level and pixel-level anomaly detection and segmentation tasks on five commonly used datasets: MVTec-AD, Visa, MPDD, MAD and Real-IAD.
Predicting the Road Ahead: A Knowledge Graph based Foundation Model for Scene Understanding in Autonomous Driving
Mar 24, 2025The autonomous driving field has seen remarkable advancements in various topics, such as object recognition, trajectory prediction, and motion planning. However, current approaches face limitations in effectively comprehending the complex evolutions of driving scenes over time. This paper proposes FM4SU, a novel methodology for training a symbolic foundation model (FM) for scene understanding in autonomous driving. It leverages knowledge graphs (KGs) to capture sensory observation along with domain knowledge such as road topology, traffic rules, or complex interactions between traffic participants. A bird's eye view (BEV) symbolic representation is extracted from the KG for each driving scene, including the spatio-temporal information among the objects across the scenes. The BEV representation is serialized into a sequence of tokens and given to pre-trained language models (PLMs) for learning an inherent understanding of the co-occurrence among driving scene elements and generating predictions on the next scenes. We conducted a number of experiments using the nuScenes dataset and KG in various scenarios. The results demonstrate that fine-tuned models achieve significantly higher accuracy in all tasks. The fine-tuned T5 model achieved a next scene prediction accuracy of 86.7%. This paper concludes that FM4SU offers a promising foundation for developing more comprehensive models for scene understanding in autonomous driving.
Towards Ideal Temporal Graph Neural Networks: Evaluations and Conclusions after 10,000 GPU Hours
Dec 28, 2024



Temporal Graph Neural Networks (TGNNs) have emerged as powerful tools for modeling dynamic interactions across various domains. The design space of TGNNs is notably complex, given the unique challenges in runtime efficiency and scalability raised by the evolving nature of temporal graphs. We contend that many of the existing works on TGNN modeling inadequately explore the design space, leading to suboptimal designs. Viewing TGNN models through a performance-focused lens often obstructs a deeper understanding of the advantages and disadvantages of each technique. Specifically, benchmarking efforts inherently evaluate models in their original designs and implementations, resulting in unclear accuracy comparisons and misleading runtime. To address these shortcomings, we propose a practical comparative evaluation framework that performs a design space search across well-known TGNN modules based on a unified, optimized code implementation. Using our framework, we make the first efforts towards addressing three critical questions in TGNN design, spending over 10,000 GPU hours: (1) investigating the efficiency of TGNN module designs, (2) analyzing how the effectiveness of these modules correlates with dataset patterns, and (3) exploring the interplay between multiple modules. Key outcomes of this directed investigative approach include demonstrating that the most recent neighbor sampling and attention aggregator outperform uniform neighbor sampling and MLP-Mixer aggregator; Assessing static node memory as an effective node memory alternative, and showing that the choice between static or dynamic node memory should be based on the repetition patterns in the dataset. Our in-depth analysis of the interplay between TGNN modules and dataset patterns should provide a deeper insight into TGNN performance along with potential research directions for designing more general and effective TGNNs.
Visual Representation Learning Guided By Multi-modal Prior Knowledge
Oct 21, 2024Despite the remarkable success of deep neural networks (DNNs) in computer vision, they fail to remain high-performing when facing distribution shifts between training and testing data. In this paper, we propose Knowledge-Guided Visual representation learning (KGV), a distribution-based learning approach leveraging multi-modal prior knowledge, to improve generalization under distribution shift. We use prior knowledge from two distinct modalities: 1) a knowledge graph (KG) with hierarchical and association relationships; and 2) generated synthetic images of visual elements semantically represented in the KG. The respective embeddings are generated from the given modalities in a common latent space, i.e., visual embeddings from original and synthetic images as well as knowledge graph embeddings (KGEs). These embeddings are aligned via a novel variant of translation-based KGE methods, where the node and relation embeddings of the KG are modeled as Gaussian distributions and translations respectively. We claim that incorporating multi-model prior knowledge enables more regularized learning of image representations. Thus, the models are able to better generalize across different data distributions. We evaluate KGV on different image classification tasks with major or minor distribution shifts, namely road sign classification across datasets from Germany, China, and Russia, image classification with the mini-ImageNet dataset and its variants, as well as the DVM-CAR dataset. The results demonstrate that KGV consistently exhibits higher accuracy and data efficiency than the baselines across all experiments.
Learning Personalized Scoping for Graph Neural Networks under Heterophily
Sep 11, 2024



Heterophilous graphs, where dissimilar nodes tend to connect, pose a challenge for graph neural networks (GNNs) as their superior performance typically comes from aggregating homophilous information. Increasing the GNN depth can expand the scope (i.e., receptive field), potentially finding homophily from the higher-order neighborhoods. However, uniformly expanding the scope results in subpar performance since real-world graphs often exhibit homophily disparity between nodes. An ideal way is personalized scopes, allowing nodes to have varying scope sizes. Existing methods typically add node-adaptive weights for each hop. Although expressive, they inevitably suffer from severe overfitting. To address this issue, we formalize personalized scoping as a separate scope classification problem that overcomes GNN overfitting in node classification. Specifically, we predict the optimal GNN depth for each node. Our theoretical and empirical analysis suggests that accurately predicting the depth can significantly enhance generalization. We further propose Adaptive Scope (AS), a lightweight MLP-based approach that only participates in GNN inference. AS encodes structural patterns and predicts the depth to select the best model for each node's prediction. Experimental results show that AS is highly flexible with various GNN architectures across a wide range of datasets while significantly improving accuracy.
TASER: Temporal Adaptive Sampling for Fast and Accurate Dynamic Graph Representation Learning
Feb 18, 2024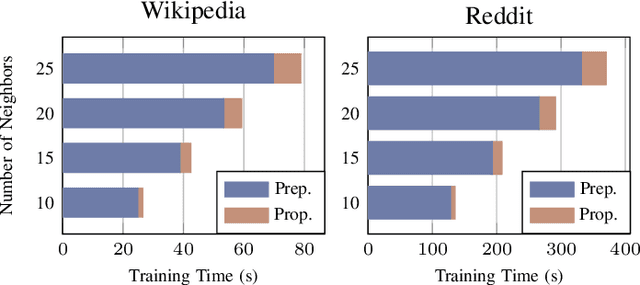
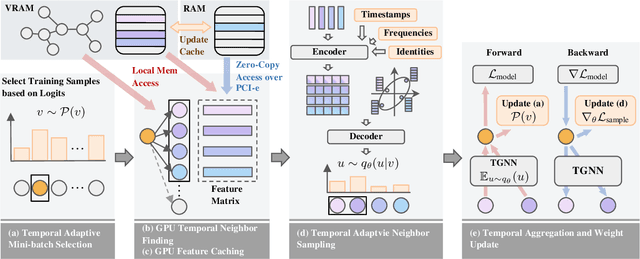
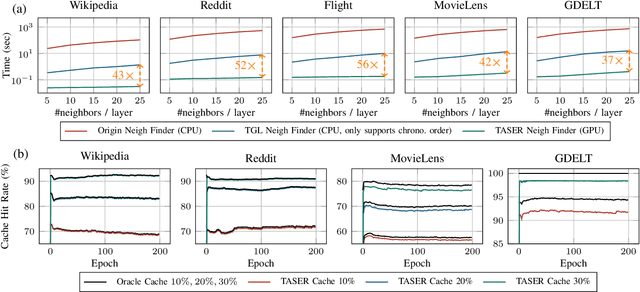
Recently, Temporal Graph Neural Networks (TGNNs) have demonstrated state-of-the-art performance in various high-impact applications, including fraud detection and content recommendation. Despite the success of TGNNs, they are prone to the prevalent noise found in real-world dynamic graphs like time-deprecated links and skewed interaction distribution. The noise causes two critical issues that significantly compromise the accuracy of TGNNs: (1) models are supervised by inferior interactions, and (2) noisy input induces high variance in the aggregated messages. However, current TGNN denoising techniques do not consider the diverse and dynamic noise pattern of each node. In addition, they also suffer from the excessive mini-batch generation overheads caused by traversing more neighbors. We believe the remedy for fast and accurate TGNNs lies in temporal adaptive sampling. In this work, we propose TASER, the first adaptive sampling method for TGNNs optimized for accuracy, efficiency, and scalability. TASER adapts its mini-batch selection based on training dynamics and temporal neighbor selection based on the contextual, structural, and temporal properties of past interactions. To alleviate the bottleneck in mini-batch generation, TASER implements a pure GPU-based temporal neighbor finder and a dedicated GPU feature cache. We evaluate the performance of TASER using two state-of-the-art backbone TGNNs. On five popular datasets, TASER outperforms the corresponding baselines by an average of 2.3% in Mean Reciprocal Rank (MRR) while achieving an average of 5.1x speedup in training time.
Language-conditioned Learning for Robotic Manipulation: A Survey
Dec 17, 2023Language-conditioned robotic manipulation represents a cutting-edge area of research, enabling seamless communication and cooperation between humans and robotic agents. This field focuses on teaching robotic systems to comprehend and execute instructions conveyed in natural language. To achieve this, the development of robust language understanding models capable of extracting actionable insights from textual input is essential. In this comprehensive survey, we systematically explore recent advancements in language-conditioned approaches within the context of robotic manipulation. We analyze these approaches based on their learning paradigms, which encompass reinforcement learning, imitation learning, and the integration of foundational models, such as large language models and vision-language models. Furthermore, we conduct an in-depth comparative analysis, considering aspects like semantic information extraction, environment & evaluation, auxiliary tasks, and task representation. Finally, we outline potential future research directions in the realm of language-conditioned learning for robotic manipulation, with the topic of generalization capabilities and safety issues.