 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableRCA: Robust Graph-Agnostic Mechanism-Level Root Cause Analysis
Jun 04, 2026Root-Cause Analysis (RCA) seeks to identify the variables responsible for abnormal system behavior in complex domains such as manufacturing, cloud computing, and healthcare. Existing approaches face a critical bottleneck: graph-based causal methods can identify intervention targets but typically require a known or accurately estimated causal graph, while graph-free statistical methods either localize marginal anomalies rather than structural causes, or rely on restrictive assumptions about graph structure or functional form. We propose StableRCA, a local mechanism-level RCA framework that avoids global graph discovery by estimating local Markov boundaries and detecting conditional distribution shifts within them. Leveraging the Independent Causal Mechanism principle, we show that intervention targets can be identified with probability converging exponentially in sample size under faithful Markov boundary recovery and non-degenerate mechanism shifts. Experiments on synthetic benchmarks and five real-world datasets demonstrate that StableRCA is robust to graph misspecification, effective under multiple intervention targets, scalable to large systems, and reliable across diverse application domains. Code is available at: https://anonymous.4open.science/r/StableRCA-E362
ORCA: An End-to-End Interactive Copilot for Optimized Root Cause Analysis
May 26, 2026Causal analysis is a crucial task in many domains, including manufacturing, social science, and medicine. However, despite recent progress, the conceptual and methodological complexity of causal methods makes them largely inaccessible to domain experts. This gap prevents experts from leveraging these advances and hinders researchers who lack access to real-world data for validation. To bridge this divide, we introduce ORCA, a copilot for end-to-end causal analysis. ORCA orchestrates agents to understand the user's goals and guide them through the most appropriate causal analysis workflow, from fully automatic to highly user-guided execution. It features causal discovery, causal effect estimation, explainability and Root-Cause-Analysis (RCA). ORCA evaluates and compares performance, generates key metrics and diagrams, and generates insights through structured reports. We highlight its effectiveness across several real-world use-cases.
Defect-aware Hybrid Prompt Optimization via Progressive Tuning for Zero-Shot Multi-type Anomaly Detection and Segmentation
Dec 10, 2025



Recent vision language models (VLMs) like CLIP have demonstrated impressive anomaly detection performance under significant distribution shift by utilizing high-level semantic information through text prompts. However, these models often neglect fine-grained details, such as which kind of anomalies, like "hole", "cut", "scratch" that could provide more specific insight into the nature of anomalies. We argue that recognizing fine-grained anomaly types 1) enriches the representation of "abnormal" with structured semantics, narrowing the gap between coarse anomaly signals and fine-grained defect categories; 2) enables manufacturers to understand the root causes of the anomaly and implement more targeted and appropriate corrective measures quickly. While incorporating such detailed semantic information is crucial, designing handcrafted prompts for each defect type is both time-consuming and susceptible to human bias. For this reason, we introduce DAPO, a novel approach for Defect-aware Prompt Optimization based on progressive tuning for the zero-shot multi-type and binary anomaly detection and segmentation under distribution shifts. Our approach aligns anomaly-relevant image features with their corresponding text semantics by learning hybrid defect-aware prompts with both fixed textual anchors and learnable token embeddings. We conducted experiments on public benchmarks (MPDD, VisA, MVTec-AD, MAD, and Real-IAD) and an internal dataset. The results suggest that compared to the baseline models, DAPO achieves a 3.7% average improvement in AUROC and average precision metrics at the image level under distribution shift, and a 6.5% average improvement in localizing novel anomaly types under zero-shot settings.
Enhancing Manufacturing Knowledge Access with LLMs and Context-aware Prompting
Jul 30, 2025



Knowledge graphs (KGs) have transformed data management within the manufacturing industry, offering effective means for integrating disparate data sources through shared and structured conceptual schemas. However, harnessing the power of KGs can be daunting for non-experts, as it often requires formulating complex SPARQL queries to retrieve specific information. With the advent of Large Language Models (LLMs), there is a growing potential to automatically translate natural language queries into the SPARQL format, thus bridging the gap between user-friendly interfaces and the sophisticated architecture of KGs. The challenge remains in adequately informing LLMs about the relevant context and structure of domain-specific KGs, e.g., in manufacturing, to improve the accuracy of generated queries. In this paper, we evaluate multiple strategies that use LLMs as mediators to facilitate information retrieval from KGs. We focus on the manufacturing domain, particularly on the Bosch Line Information System KG and the I40 Core Information Model. In our evaluation, we compare various approaches for feeding relevant context from the KG to the LLM and analyze their proficiency in transforming real-world questions into SPARQL queries. Our findings show that LLMs can significantly improve their performance on generating correct and complete queries when provided only the adequate context of the KG schema. Such context-aware prompting techniques help LLMs to focus on the relevant parts of the ontology and reduce the risk of hallucination. We anticipate that the proposed techniques help LLMs to democratize access to complex data repositories and empower informed decision-making in manufacturing settings.
MultiADS: Defect-aware Supervision for Multi-type Anomaly Detection and Segmentation in Zero-Shot Learning
Apr 09, 2025Precise optical inspection in industrial applications is crucial for minimizing scrap rates and reducing the associated costs. Besides merely detecting if a product is anomalous or not, it is crucial to know the distinct type of defect, such as a bent, cut, or scratch. The ability to recognize the "exact" defect type enables automated treatments of the anomalies in modern production lines. Current methods are limited to solely detecting whether a product is defective or not without providing any insights on the defect type, nevertheless detecting and identifying multiple defects. We propose MultiADS, a zero-shot learning approach, able to perform Multi-type Anomaly Detection and Segmentation. The architecture of MultiADS comprises CLIP and extra linear layers to align the visual- and textual representation in a joint feature space. To the best of our knowledge, our proposal, is the first approach to perform a multi-type anomaly segmentation task in zero-shot learning. Contrary to the other baselines, our approach i) generates specific anomaly masks for each distinct defect type, ii) learns to distinguish defect types, and iii) simultaneously identifies multiple defect types present in an anomalous product. Additionally, our approach outperforms zero/few-shot learning SoTA methods on image-level and pixel-level anomaly detection and segmentation tasks on five commonly used datasets: MVTec-AD, Visa, MPDD, MAD and Real-IAD.
Predicting the Road Ahead: A Knowledge Graph based Foundation Model for Scene Understanding in Autonomous Driving
Mar 24, 2025The autonomous driving field has seen remarkable advancements in various topics, such as object recognition, trajectory prediction, and motion planning. However, current approaches face limitations in effectively comprehending the complex evolutions of driving scenes over time. This paper proposes FM4SU, a novel methodology for training a symbolic foundation model (FM) for scene understanding in autonomous driving. It leverages knowledge graphs (KGs) to capture sensory observation along with domain knowledge such as road topology, traffic rules, or complex interactions between traffic participants. A bird's eye view (BEV) symbolic representation is extracted from the KG for each driving scene, including the spatio-temporal information among the objects across the scenes. The BEV representation is serialized into a sequence of tokens and given to pre-trained language models (PLMs) for learning an inherent understanding of the co-occurrence among driving scene elements and generating predictions on the next scenes. We conducted a number of experiments using the nuScenes dataset and KG in various scenarios. The results demonstrate that fine-tuned models achieve significantly higher accuracy in all tasks. The fine-tuned T5 model achieved a next scene prediction accuracy of 86.7%. This paper concludes that FM4SU offers a promising foundation for developing more comprehensive models for scene understanding in autonomous driving.
CausalMan: A physics-based simulator for large-scale causality
Feb 18, 2025A comprehensive understanding of causality is critical for navigating and operating within today's complex real-world systems. The absence of realistic causal models with known data generating processes complicates fair benchmarking. In this paper, we present the CausalMan simulator, modeled after a real-world production line. The simulator features a diverse range of linear and non-linear mechanisms and challenging-to-predict behaviors, such as discrete mode changes. We demonstrate the inadequacy of many state-of-the-art approaches and analyze the significant differences in their performance and tractability, both in terms of runtime and memory complexity. As a contribution, we will release the CausalMan large-scale simulator. We present two derived datasets, and perform an extensive evaluation of both.
Visual Representation Learning Guided By Multi-modal Prior Knowledge
Oct 21, 2024Despite the remarkable success of deep neural networks (DNNs) in computer vision, they fail to remain high-performing when facing distribution shifts between training and testing data. In this paper, we propose Knowledge-Guided Visual representation learning (KGV), a distribution-based learning approach leveraging multi-modal prior knowledge, to improve generalization under distribution shift. We use prior knowledge from two distinct modalities: 1) a knowledge graph (KG) with hierarchical and association relationships; and 2) generated synthetic images of visual elements semantically represented in the KG. The respective embeddings are generated from the given modalities in a common latent space, i.e., visual embeddings from original and synthetic images as well as knowledge graph embeddings (KGEs). These embeddings are aligned via a novel variant of translation-based KGE methods, where the node and relation embeddings of the KG are modeled as Gaussian distributions and translations respectively. We claim that incorporating multi-model prior knowledge enables more regularized learning of image representations. Thus, the models are able to better generalize across different data distributions. We evaluate KGV on different image classification tasks with major or minor distribution shifts, namely road sign classification across datasets from Germany, China, and Russia, image classification with the mini-ImageNet dataset and its variants, as well as the DVM-CAR dataset. The results demonstrate that KGV consistently exhibits higher accuracy and data efficiency than the baselines across all experiments.
SocialFormer: Social Interaction Modeling with Edge-enhanced Heterogeneous Graph Transformers for Trajectory Prediction
May 06, 2024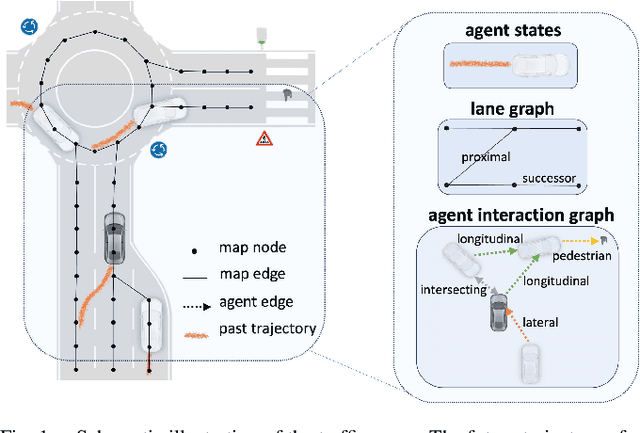
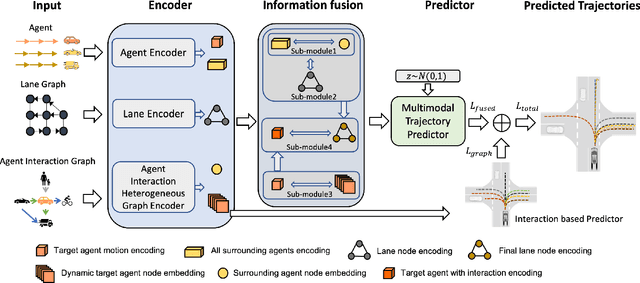
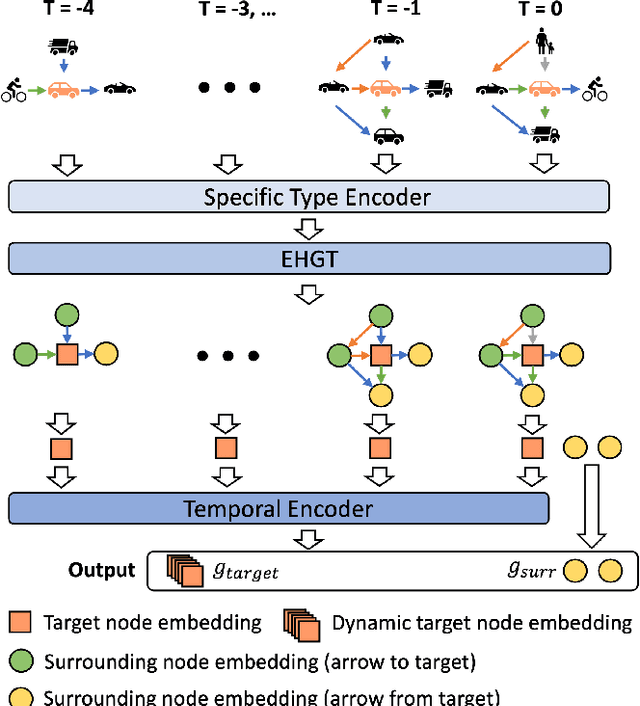
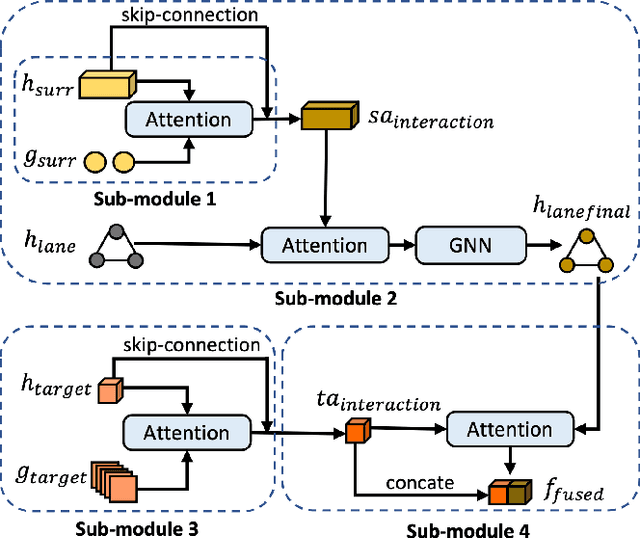
Accurate trajectory prediction is crucial for ensuring safe and efficient autonomous driving. However, most existing methods overlook complex interactions between traffic participants that often govern their future trajectories. In this paper, we propose SocialFormer, an agent interaction-aware trajectory prediction method that leverages the semantic relationship between the target vehicle and surrounding vehicles by making use of the road topology. We also introduce an edge-enhanced heterogeneous graph transformer (EHGT) as the aggregator in a graph neural network (GNN) to encode the semantic and spatial agent interaction information. Additionally, we introduce a temporal encoder based on gated recurrent units (GRU) to model the temporal social behavior of agent movements. Finally, we present an information fusion framework that integrates agent encoding, lane encoding, and agent interaction encoding for a holistic representation of the traffic scene. We evaluate SocialFormer for the trajectory prediction task on the popular nuScenes benchmark and achieve state-of-the-art performance.
SemanticFormer: Holistic and Semantic Traffic Scene Representation for Trajectory Prediction using Knowledge Graphs
Apr 30, 2024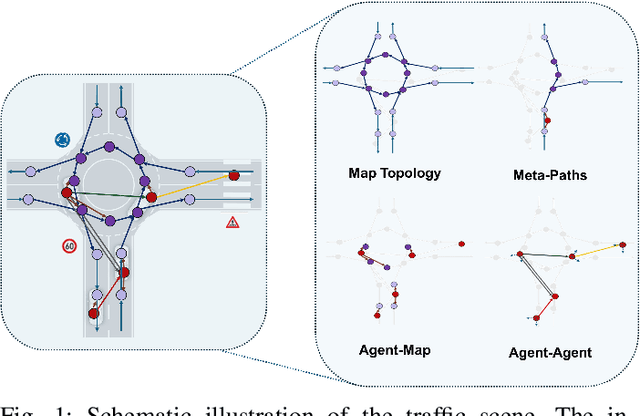
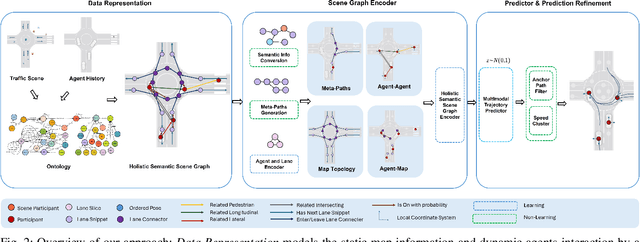
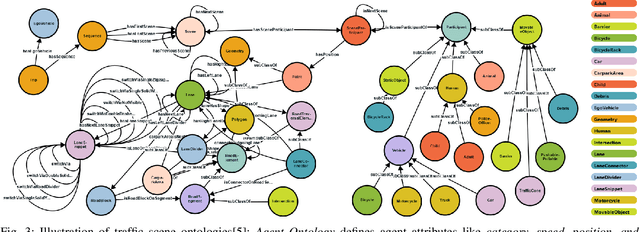
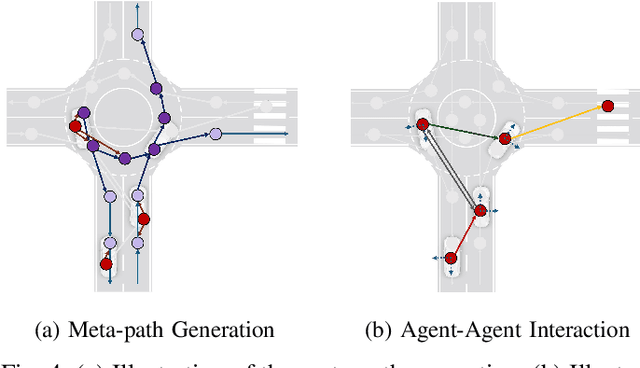
Trajectory prediction in autonomous driving relies on accurate representation of all relevant contexts of the driving scene including traffic participants, road topology, traffic signs as well as their semantic relations to each other. Despite increased attention to this issue, most approaches in trajectory prediction do not consider all of these factors sufficiently. This paper describes a method SemanticFormer to predict multimodal trajectories by reasoning over a semantic traffic scene graph using a hybrid approach. We extract high-level information in the form of semantic meta-paths from a knowledge graph which is then processed by a novel pipeline based on multiple attention mechanisms to predict accurate trajectories. The proposed architecture comprises a hierarchical heterogeneous graph encoder, which can capture spatio-temporal and relational information across agents and between agents and road elements, and a predictor that fuses the different encodings and decodes trajectories with probabilities. Finally, a refinement module evaluates permitted meta-paths of trajectories and speed profiles to obtain final predicted trajectories. Evaluation of the nuScenes benchmark demonstrates improved performance compared to the state-of-the-art methods.