 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeSCAN: ScreenCast ANalysis for Video Programming Tutorials
Sep 27, 2024Programming tutorials in the form of coding screencasts play a crucial role in programming education, serving both novices and experienced developers. However, the video format of these tutorials presents a challenge due to the difficulty of searching for and within videos. Addressing the absence of large-scale and diverse datasets for screencast analysis, we introduce the CodeSCAN dataset. It comprises 12,000 screenshots captured from the Visual Studio Code environment during development, featuring 24 programming languages, 25 fonts, and over 90 distinct themes, in addition to diverse layout changes and realistic user interactions. Moreover, we conduct detailed quantitative and qualitative evaluations to benchmark the performance of Integrated Development Environment (IDE) element detection, color-to-black-and-white conversion, and Optical Character Recognition (OCR). We hope that our contributions facilitate more research in coding screencast analysis, and we make the source code for creating the dataset and the benchmark publicly available on this website.
FZI-WIM at SemEval-2024 Task 2: Self-Consistent CoT for Complex NLI in Biomedical Domain
Jun 14, 2024
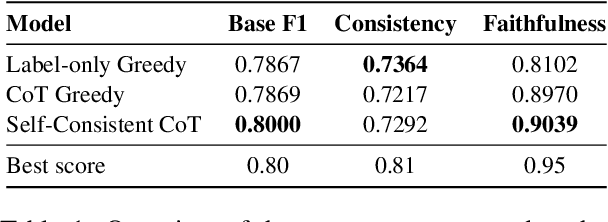
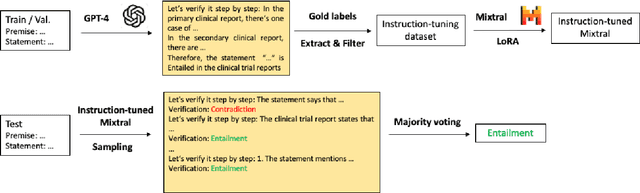

This paper describes the inference system of FZI-WIM at the SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials. Our system utilizes the chain of thought (CoT) paradigm to tackle this complex reasoning problem and further improves the CoT performance with self-consistency. Instead of greedy decoding, we sample multiple reasoning chains with the same prompt and make the final verification with majority voting. The self-consistent CoT system achieves a baseline F1 score of 0.80 (1st), faithfulness score of 0.90 (3rd), and consistency score of 0.73 (12th). We release the code and data publicly https://github.com/jens5588/FZI-WIM-NLI4CT.
Heterogeneous Graph-based Trajectory Prediction using Local Map Context and Social Interactions
Nov 30, 2023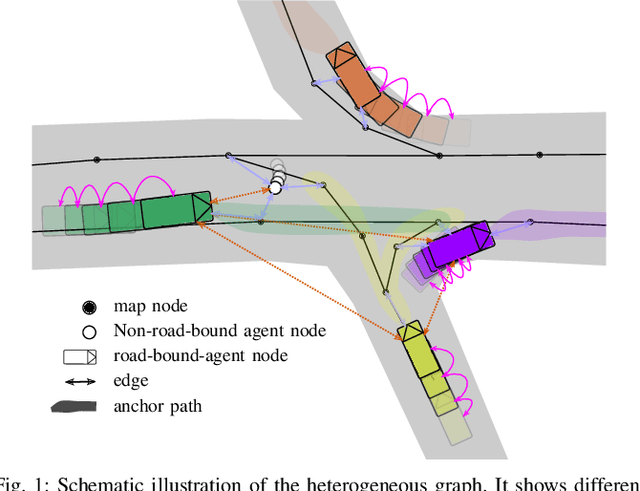
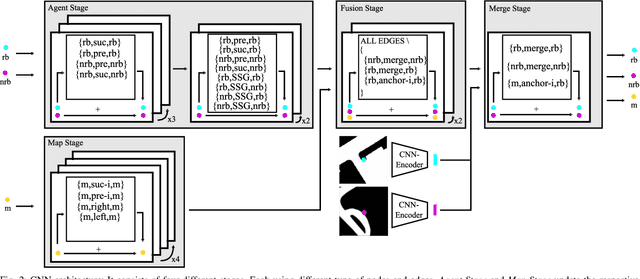
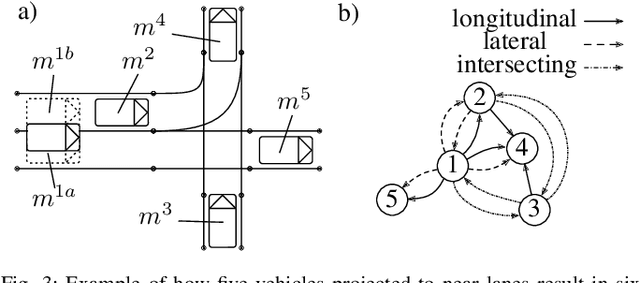
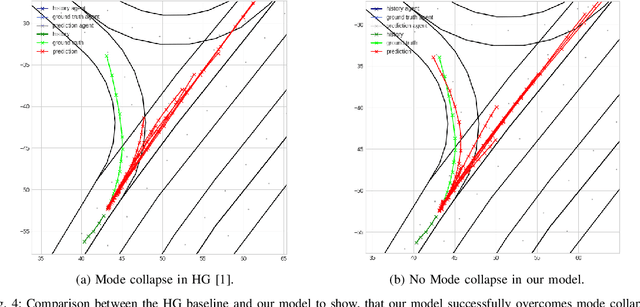
Precisely predicting the future trajectories of surrounding traffic participants is a crucial but challenging problem in autonomous driving, due to complex interactions between traffic agents, map context and traffic rules. Vector-based approaches have recently shown to achieve among the best performances on trajectory prediction benchmarks. These methods model simple interactions between traffic agents but don't distinguish between relation-type and attributes like their distance along the road. Furthermore, they represent lanes only by sequences of vectors representing center lines and ignore context information like lane dividers and other road elements. We present a novel approach for vector-based trajectory prediction that addresses these shortcomings by leveraging three crucial sources of information: First, we model interactions between traffic agents by a semantic scene graph, that accounts for the nature and important features of their relation. Second, we extract agent-centric image-based map features to model the local map context. Finally, we generate anchor paths to enforce the policy in multi-modal prediction to permitted trajectories only. Each of these three enhancements shows advantages over the baseline model HoliGraph.
XTSC-Bench: Quantitative Benchmarking for Explainers on Time Series Classification
Oct 23, 2023Despite the growing body of work on explainable machine learning in time series classification (TSC), it remains unclear how to evaluate different explainability methods. Resorting to qualitative assessment and user studies to evaluate explainers for TSC is difficult since humans have difficulties understanding the underlying information contained in time series data. Therefore, a systematic review and quantitative comparison of explanation methods to confirm their correctness becomes crucial. While steps to standardized evaluations were taken for tabular, image, and textual data, benchmarking explainability methods on time series is challenging due to a) traditional metrics not being directly applicable, b) implementation and adaption of traditional metrics for time series in the literature vary, and c) varying baseline implementations. This paper proposes XTSC-Bench, a benchmarking tool providing standardized datasets, models, and metrics for evaluating explanation methods on TSC. We analyze 3 perturbation-, 6 gradient- and 2 example-based explanation methods to TSC showing that improvements in the explainers' robustness and reliability are necessary, especially for multivariate data.
Literature Review: Computer Vision Applications in Transportation Logistics and Warehousing
Apr 12, 2023
Computer vision applications in transportation logistics and warehousing have a huge potential for process automation. We present a structured literature review on research in the field to help leverage this potential. All literature is categorized w.r.t. the application, i.e. the task it tackles and w.r.t. the computer vision techniques that are used. Regarding applications, we subdivide the literature in two areas: Monitoring, i.e. observing and retrieving relevant information from the environment, and manipulation, where approaches are used to analyze and interact with the environment. In addition to that, we point out directions for future research and link to recent developments in computer vision that are suitable for application in logistics. Finally, we present an overview of existing datasets and industrial solutions. We conclude that while already many research areas have been investigated, there is still huge potential for future research. The results of our analysis are also available online at https://a-nau.github.io/cv-in-logistics.
Relation-based Motion Prediction using Traffic Scene Graphs
Nov 24, 2022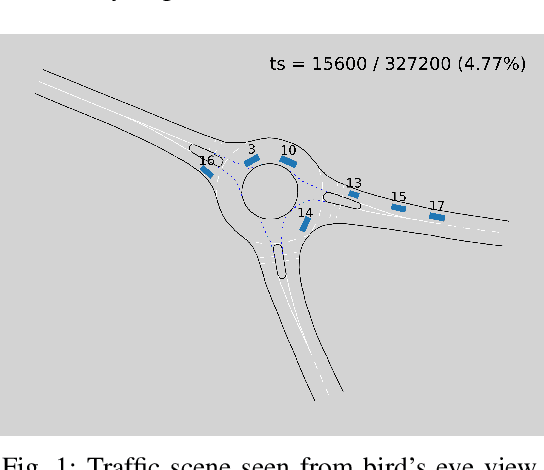
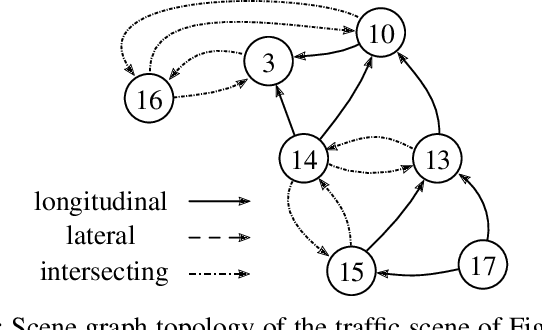
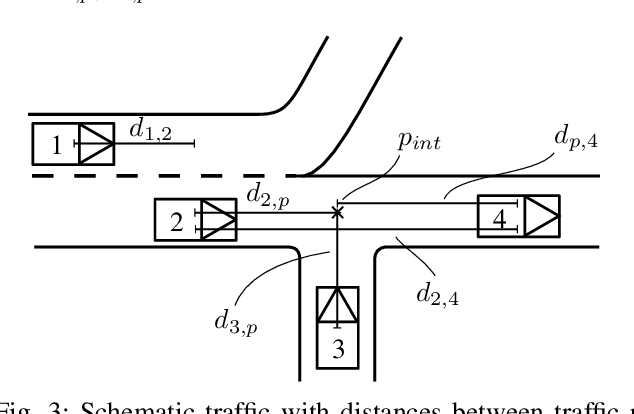
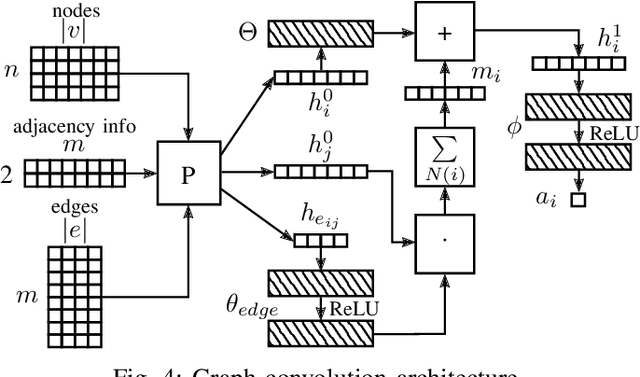
Representing relevant information of a traffic scene and understanding its environment is crucial for the success of autonomous driving. Modeling the surrounding of an autonomous car using semantic relations, i.e., how different traffic participants relate in the context of traffic rule based behaviors, is hardly been considered in previous work. This stems from the fact that these relations are hard to extract from real-world traffic scenes. In this work, we model traffic scenes in a form of spatial semantic scene graphs for various different predictions about the traffic participants, e.g., acceleration and deceleration. Our learning and inference approach uses Graph Neural Networks (GNNs) and shows that incorporating explicit information about the spatial semantic relations between traffic participants improves the predicdtion results. Specifically, the acceleration prediction of traffic participants is improved by up to 12% compared to the baselines, which do not exploit this explicit information. Furthermore, by including additional information about previous scenes, we achieve 73% improvements.
TSInterpret: A unified framework for time series interpretability
Aug 15, 2022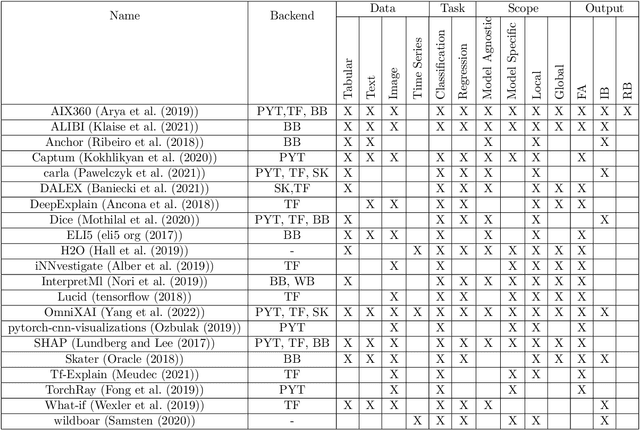
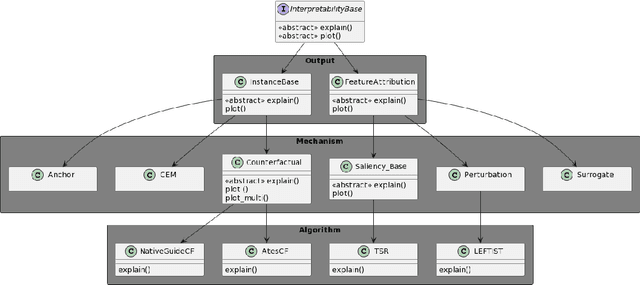

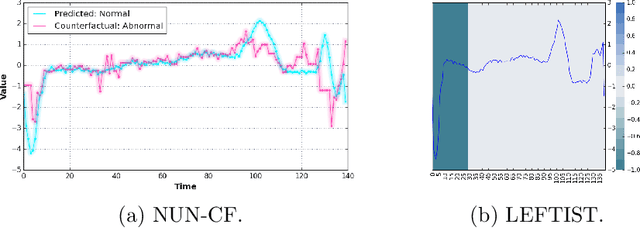
With the increasing application of deep learning algorithms to time series classification, especially in high-stake scenarios, the relevance of interpreting those algorithms becomes key. Although research in time series interpretability has grown, accessibility for practitioners is still an obstacle. Interpretability approaches and their visualizations are diverse in use without a unified API or framework. To close this gap, we introduce TSInterpret an easily extensible open-source Python library for interpreting predictions of time series classifiers that combines existing interpretation approaches into one unified framework. The library features (i) state-of-the-art interpretability algorithms, (ii) exposes a unified API enabling users to work with explanations consistently and provides (iii) suitable visualizations for each explanation.
Knowledge Fusion via Embeddings from Text, Knowledge Graphs, and Images
Apr 20, 2017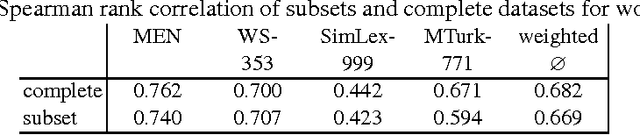
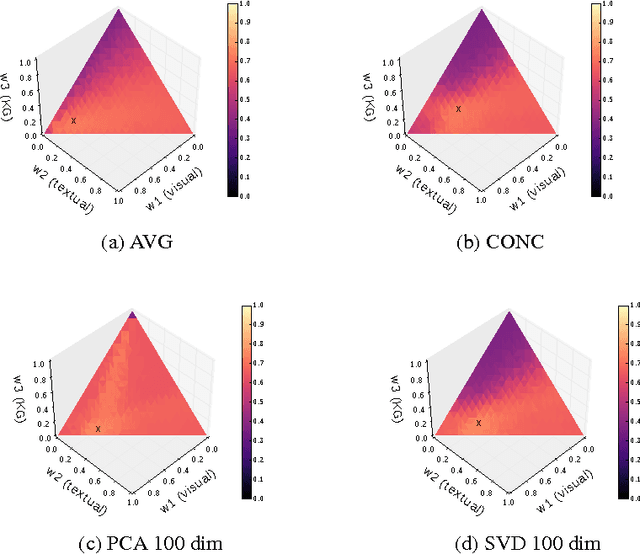
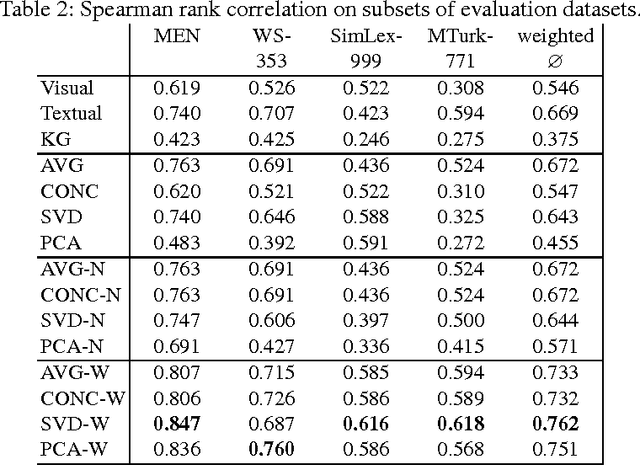
We present a baseline approach for cross-modal knowledge fusion. Different basic fusion methods are evaluated on existing embedding approaches to show the potential of joining knowledge about certain concepts across modalities in a fused concept representation.