 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware and Temporally Regulated Expert Advice in Reinforcement Learning for Autonomous Driving
May 28, 2026Exploration in reinforcement learning for autonomous driving is inherently unsafe: agents must experience novel behaviors to learn, yet exploration can lead to collisions or off-road driving. We propose an uncertainty-aware framework that leverages expert advice to guide exploration while avoiding long-term dependence. Advice is triggered when epistemic or aleatoric uncertainty exceeds adaptive thresholds derived from rolling buffers, ensuring advice evolves with the agent's confidence. A commitment-cooldown strategy with a stochastic early-stop heuristic regulates the duration and frequency of guidance, exposing the agent to coherent maneuvers without exhausting the advice budget. Expert and agent experiences are combined in a shared replay buffer within an off-policy implicit quantile network (IQN) backbone, enabling efficient reuse of expert trajectories. Experiments in CARLA show that our method outperforms the IQN baseline, improving success by 5-7% and reducing failures, demonstrating that risk-sensitive uncertainty coupled with regulated expert integration enables safer and more efficient exploration for sensor-based RL policy learning in unsignalized intersection navigation.
CIG: Exploration via Conditional Information Gain
May 20, 2026Intrinsic rewards for exploration in reinforcement learning condition on different contexts: lifelong rewards score each transition against accumulated experience but ignore within-rollout redundancy; episodic rewards penalize intra-trajectory repetition but discard lifetime progress. Hybrid methods combine both signals through heuristic weights or require Gaussian-process dynamics that do not scale beyond low-dimensional state spaces. Trajectory-level information gain decomposes into per-step terms that condition on the replay buffer and rollout prefix simultaneously, but remains intractable for deep models. We derive the Conditional Information Gain (CIG) reward as a tractable surrogate: a log-determinant objective over an ensemble disagreement kernel whose Cholesky factorization yields causal per-step rewards that retain both conditioning sets while scaling to high-dimensional state spaces. We instantiate CIG in a model-based setting, where rollouts are short and within-rollout corrections remain largely unexplored. Across twelve tasks spanning discrete (MiniGrid) and continuous control (OGBench), in both clean and stochastic-distractor settings, CIG outperforms or matches prior exploration methods while remaining robust to stochastic distractors.
Towards a Systematic Risk Assessment of Deep Neural Network Limitations in Autonomous Driving Perception
Apr 21, 2026Safety and security are essential for the admission and acceptance of automated and autonomous vehicles. Deep neural networks (DNNs) are widely used for perception and further components of the autonomous driving (AD) stack. However, they possess several limitations, including lack of generalization, efficiency, explainability, plausibility, and robustness. These insufficiencies can pose significant risks to autonomous driving systems. However, hazards, threats, and risks associated with DNN limitations in this domain have not been systematically studied so far. In this work, we propose a joint workflow for risk assessment combining the hazard analysis and risk assessment (HARA) following ISO 26262 and threat analysis and risk assessment (TARA) following the ISO/SAE 21434 to identify and analyze risks arising from inherent DNN limitations in AD perception.
Domain-Specialized Object Detection via Model-Level Mixtures of Experts
Apr 20, 2026Mixture-of-Experts (MoE) models provide a structured approach to combining specialized neural networks and offer greater interpretability than conventional ensembles. While MoEs have been successfully applied to image classification and semantic segmentation, their use in object detection remains limited due to challenges in merging dense and structured predictions. In this work, we investigate model-level mixtures of object detectors and analyze their suitability for improving performance and interpretability in object detection. We propose an MoE architecture that combines YOLO-based detectors trained on semantically disjoint data subsets, with a learned gating network that dynamically weights expert contributions. We study different strategies for fusing detection outputs and for training the gating mechanism, including balancing losses to prevent expert collapse. Experiments on the BDD100K dataset demonstrate that the proposed MoE consistently outperforms standard ensemble approaches and provides insights into expert specialization across domains, highlighting model-level MoEs as a viable alternative to traditional ensembling for object detection. Our code is available at https://github.com/KASTEL-MobilityLab/mixtures-of-experts/.
Design and Behavior of Sparse Mixture-of-Experts Layers in CNN-based Semantic Segmentation
Apr 15, 2026Sparse mixture-of-experts (MoE) layers have been shown to substantially increase model capacity without a proportional increase in computational cost and are widely used in transformer architectures, where they typically replace feed-forward network blocks. In contrast, integrating sparse MoE layers into convolutional neural networks (CNNs) remains inconsistent, with most prior work focusing on fine-grained MoEs operating at the filter or channel levels. In this work, we investigate a coarser, patch-wise formulation of sparse MoE layers for semantic segmentation, where local regions are routed to a small subset of convolutional experts. Through experiments on the Cityscapes and BDD100K datasets using encoder-decoder and backbone-based CNNs, we conduct a design analysis to assess how architectural choices affect routing dynamics and expert specialization. Our results demonstrate consistent, architecture-dependent improvements (up to +3.9 mIoU) with little computational overhead, while revealing strong design sensitivity. Our work provides empirical insights into the design and internal dynamics of sparse MoE layers in CNN-based dense prediction. Our code is available at https://github.com/KASTEL-MobilityLab/moe-layers/.
Efficient Cross-Country Data Acquisition Strategy for ADAS via Street-View Imagery
Feb 02, 2026Deploying ADAS and ADS across countries remains challenging due to differences in legislation, traffic infrastructure, and visual conventions, which introduce domain shifts that degrade perception performance. Traditional cross-country data collection relies on extensive on-road driving, making it costly and inefficient to identify representative locations. To address this, we propose a street-view-guided data acquisition strategy that leverages publicly available imagery to identify places of interest (POI). Two POI scoring methods are introduced: a KNN-based feature distance approach using a vision foundation model, and a visual-attribution approach using a vision-language model. To enable repeatable evaluation, we adopt a collect-detect protocol and construct a co-located dataset by pairing the Zenseact Open Dataset with Mapillary street-view images. Experiments on traffic sign detection, a task particularly sensitive to cross-country variations in sign appearance, show that our approach achieves performance comparable to random sampling while using only half of the target-domain data. We further provide cost estimations for full-country analysis, demonstrating that large-scale street-view processing remains economically feasible. These results highlight the potential of street-view-guided data acquisition for efficient and cost-effective cross-country model adaptation.
DenseBEV: Transforming BEV Grid Cells into 3D Objects
Dec 18, 2025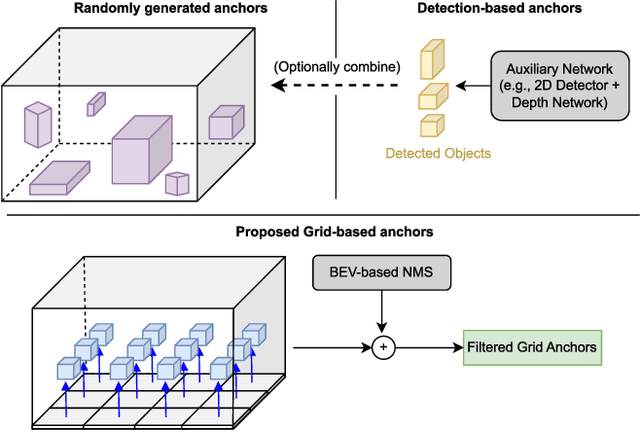
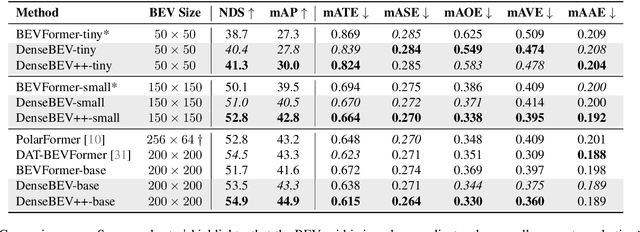
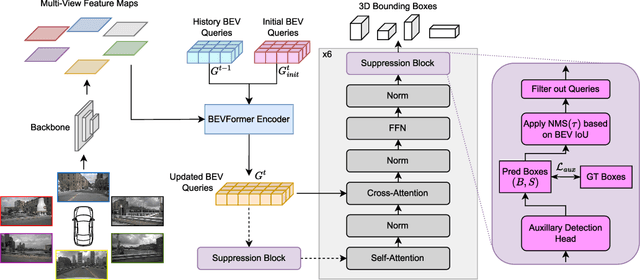
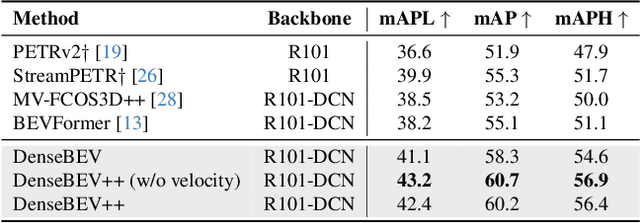
In current research, Bird's-Eye-View (BEV)-based transformers are increasingly utilized for multi-camera 3D object detection. Traditional models often employ random queries as anchors, optimizing them successively. Recent advancements complement or replace these random queries with detections from auxiliary networks. We propose a more intuitive and efficient approach by using BEV feature cells directly as anchors. This end-to-end approach leverages the dense grid of BEV queries, considering each cell as a potential object for the final detection task. As a result, we introduce a novel two-stage anchor generation method specifically designed for multi-camera 3D object detection. To address the scaling issues of attention with a large number of queries, we apply BEV-based Non-Maximum Suppression, allowing gradients to flow only through non-suppressed objects. This ensures efficient training without the need for post-processing. By using BEV features from encoders such as BEVFormer directly as object queries, temporal BEV information is inherently embedded. Building on the temporal BEV information already embedded in our object queries, we introduce a hybrid temporal modeling approach by integrating prior detections to further enhance detection performance. Evaluating our method on the nuScenes dataset shows consistent and significant improvements in NDS and mAP over the baseline, even with sparser BEV grids and therefore fewer initial anchors. It is particularly effective for small objects, enhancing pedestrian detection with a 3.8% mAP increase on nuScenes and an 8% increase in LET-mAP on Waymo. Applying our method, named DenseBEV, to the challenging Waymo Open dataset yields state-of-the-art performance, achieving a LET-mAP of 60.7%, surpassing the previous best by 5.4%. Code is available at https://github.com/mdaehl/DenseBEV.
Runtime Safety Monitoring of Deep Neural Networks for Perception: A Survey
Nov 08, 2025Deep neural networks (DNNs) are widely used in perception systems for safety-critical applications, such as autonomous driving and robotics. However, DNNs remain vulnerable to various safety concerns, including generalization errors, out-of-distribution (OOD) inputs, and adversarial attacks, which can lead to hazardous failures. This survey provides a comprehensive overview of runtime safety monitoring approaches, which operate in parallel to DNNs during inference to detect these safety concerns without modifying the DNN itself. We categorize existing methods into three main groups: Monitoring inputs, internal representations, and outputs. We analyze the state-of-the-art for each category, identify strengths and limitations, and map methods to the safety concerns they address. In addition, we highlight open challenges and future research directions.
DEAP DIVE: Dataset Investigation with Vision transformers for EEG evaluation
Oct 01, 2025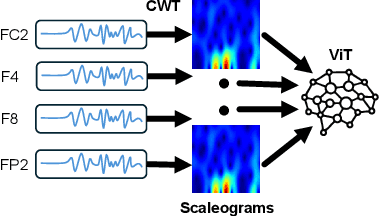
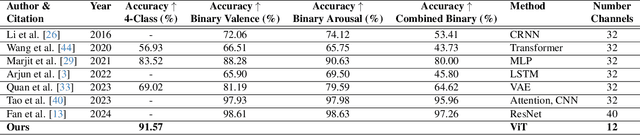


Accurately predicting emotions from brain signals has the potential to achieve goals such as improving mental health, human-computer interaction, and affective computing. Emotion prediction through neural signals offers a promising alternative to traditional methods, such as self-assessment and facial expression analysis, which can be subjective or ambiguous. Measurements of the brain activity via electroencephalogram (EEG) provides a more direct and unbiased data source. However, conducting a full EEG is a complex, resource-intensive process, leading to the rise of low-cost EEG devices with simplified measurement capabilities. This work examines how subsets of EEG channels from the DEAP dataset can be used for sufficiently accurate emotion prediction with low-cost EEG devices, rather than fully equipped EEG-measurements. Using Continuous Wavelet Transformation to convert EEG data into scaleograms, we trained a vision transformer (ViT) model for emotion classification. The model achieved over 91,57% accuracy in predicting 4 quadrants (high/low per arousal and valence) with only 12 measuring points (also referred to as channels). Our work shows clearly, that a significant reduction of input channels yields high results compared to state-of-the-art results of 96,9% with 32 channels. Training scripts to reproduce our code can be found here: https://gitlab.kit.edu/kit/aifb/ATKS/public/AutoSMiLeS/DEAP-DIVE.
CrowdQuery: Density-Guided Query Module for Enhanced 2D and 3D Detection in Crowded Scenes
Sep 10, 2025This paper introduces a novel method for end-to-end crowd detection that leverages object density information to enhance existing transformer-based detectors. We present CrowdQuery (CQ), whose core component is our CQ module that predicts and subsequently embeds an object density map. The embedded density information is then systematically integrated into the decoder. Existing density map definitions typically depend on head positions or object-based spatial statistics. Our method extends these definitions to include individual bounding box dimensions. By incorporating density information into object queries, our method utilizes density-guided queries to improve detection in crowded scenes. CQ is universally applicable to both 2D and 3D detection without requiring additional data. Consequently, we are the first to design a method that effectively bridges 2D and 3D detection in crowded environments. We demonstrate the integration of CQ into both a general 2D and 3D transformer-based object detector, introducing the architectures CQ2D and CQ3D. CQ is not limited to the specific transformer models we selected. Experiments on the STCrowd dataset for both 2D and 3D domains show significant performance improvements compared to the base models, outperforming most state-of-the-art methods. When integrated into a state-of-the-art crowd detector, CQ can further improve performance on the challenging CrowdHuman dataset, demonstrating its generalizability. The code is released at https://github.com/mdaehl/CrowdQuery.