 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware and Temporally Regulated Expert Advice in Reinforcement Learning for Autonomous Driving
May 28, 2026Exploration in reinforcement learning for autonomous driving is inherently unsafe: agents must experience novel behaviors to learn, yet exploration can lead to collisions or off-road driving. We propose an uncertainty-aware framework that leverages expert advice to guide exploration while avoiding long-term dependence. Advice is triggered when epistemic or aleatoric uncertainty exceeds adaptive thresholds derived from rolling buffers, ensuring advice evolves with the agent's confidence. A commitment-cooldown strategy with a stochastic early-stop heuristic regulates the duration and frequency of guidance, exposing the agent to coherent maneuvers without exhausting the advice budget. Expert and agent experiences are combined in a shared replay buffer within an off-policy implicit quantile network (IQN) backbone, enabling efficient reuse of expert trajectories. Experiments in CARLA show that our method outperforms the IQN baseline, improving success by 5-7% and reducing failures, demonstrating that risk-sensitive uncertainty coupled with regulated expert integration enables safer and more efficient exploration for sensor-based RL policy learning in unsignalized intersection navigation.
Real-World On-Vehicle Evaluation of Embedding-Based Anomaly Detection
May 19, 2026Detecting anomalies in traffic scenes is crucial for ensuring safety in autonomous driving, yet collecting representative anomalous data remains challenging. Existing anomaly detection methods are highly specialized and rely on normality as defined by the abstract semantic Cityscapes classes, making it difficult to adapt to diverse real-world scenarios. We propose an adaptable real-time anomaly detection method that leverages foundation models in the form of pretrained vision transformer embeddings to detect deviations via nearest-neighbor similarity in the latent semantic feature space. Based on patch-wise processing, the algorithm produces dense anomaly masks, allowing for the localization of detected anomalies. The method robustly models normality through a single reference image. This formulation avoids explicit supervision and dataset-specific training, making it suitable for real-world deployment. We evaluate the method on standard benchmarks and on an automated vehicle in real-world scenarios. Despite its simplicity, the method achieves good performance on the Road Anomaly benchmark and demonstrates consistent qualitative behavior in practice, successfully highlighting semantically unusual objects in diverse scenes. These results suggest that simple, reference-based methods can provide useful anomaly signals under realistic operating conditions.
Efficient Cross-Country Data Acquisition Strategy for ADAS via Street-View Imagery
Feb 02, 2026Deploying ADAS and ADS across countries remains challenging due to differences in legislation, traffic infrastructure, and visual conventions, which introduce domain shifts that degrade perception performance. Traditional cross-country data collection relies on extensive on-road driving, making it costly and inefficient to identify representative locations. To address this, we propose a street-view-guided data acquisition strategy that leverages publicly available imagery to identify places of interest (POI). Two POI scoring methods are introduced: a KNN-based feature distance approach using a vision foundation model, and a visual-attribution approach using a vision-language model. To enable repeatable evaluation, we adopt a collect-detect protocol and construct a co-located dataset by pairing the Zenseact Open Dataset with Mapillary street-view images. Experiments on traffic sign detection, a task particularly sensitive to cross-country variations in sign appearance, show that our approach achieves performance comparable to random sampling while using only half of the target-domain data. We further provide cost estimations for full-country analysis, demonstrating that large-scale street-view processing remains economically feasible. These results highlight the potential of street-view-guided data acquisition for efficient and cost-effective cross-country model adaptation.
Automatic Curriculum Learning for Driving Scenarios: Towards Robust and Efficient Reinforcement Learning
May 13, 2025This paper addresses the challenges of training end-to-end autonomous driving agents using Reinforcement Learning (RL). RL agents are typically trained in a fixed set of scenarios and nominal behavior of surrounding road users in simulations, limiting their generalization and real-life deployment. While domain randomization offers a potential solution by randomly sampling driving scenarios, it frequently results in inefficient training and sub-optimal policies due to the high variance among training scenarios. To address these limitations, we propose an automatic curriculum learning framework that dynamically generates driving scenarios with adaptive complexity based on the agent's evolving capabilities. Unlike manually designed curricula that introduce expert bias and lack scalability, our framework incorporates a ``teacher'' that automatically generates and mutates driving scenarios based on their learning potential -- an agent-centric metric derived from the agent's current policy -- eliminating the need for expert design. The framework enhances training efficiency by excluding scenarios the agent has mastered or finds too challenging. We evaluate our framework in a reinforcement learning setting where the agent learns a driving policy from camera images. Comparative results against baseline methods, including fixed scenario training and domain randomization, demonstrate that our approach leads to enhanced generalization, achieving higher success rates: +9\% in low traffic density, +21\% in high traffic density, and faster convergence with fewer training steps. Our findings highlight the potential of ACL in improving the robustness and efficiency of RL-based autonomous driving agents.
TPK: Trustworthy Trajectory Prediction Integrating Prior Knowledge For Interpretability and Kinematic Feasibility
May 10, 2025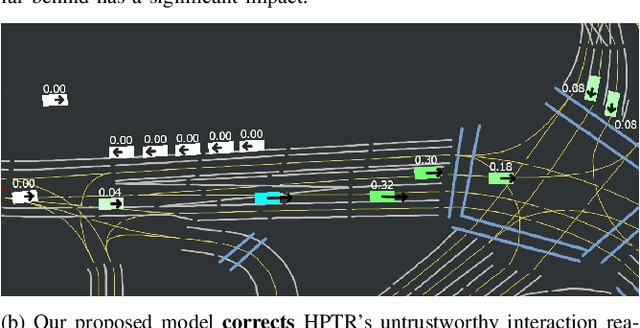
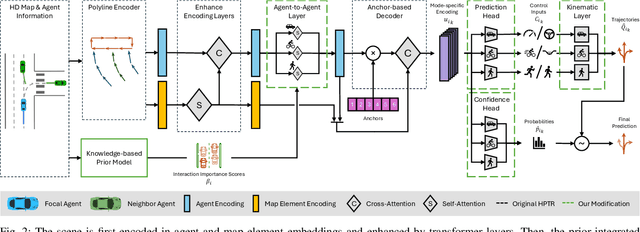
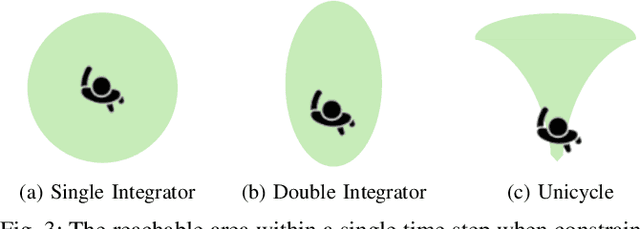
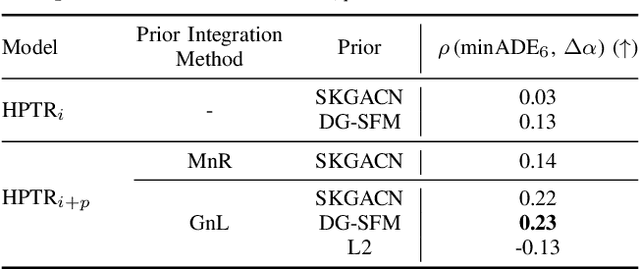
Trajectory prediction is crucial for autonomous driving, enabling vehicles to navigate safely by anticipating the movements of surrounding road users. However, current deep learning models often lack trustworthiness as their predictions can be physically infeasible and illogical to humans. To make predictions more trustworthy, recent research has incorporated prior knowledge, like the social force model for modeling interactions and kinematic models for physical realism. However, these approaches focus on priors that suit either vehicles or pedestrians and do not generalize to traffic with mixed agent classes. We propose incorporating interaction and kinematic priors of all agent classes--vehicles, pedestrians, and cyclists with class-specific interaction layers to capture agent behavioral differences. To improve the interpretability of the agent interactions, we introduce DG-SFM, a rule-based interaction importance score that guides the interaction layer. To ensure physically feasible predictions, we proposed suitable kinematic models for all agent classes with a novel pedestrian kinematic model. We benchmark our approach on the Argoverse 2 dataset, using the state-of-the-art transformer HPTR as our baseline. Experiments demonstrate that our method improves interaction interpretability, revealing a correlation between incorrect predictions and divergence from our interaction prior. Even though incorporating the kinematic models causes a slight decrease in accuracy, they eliminate infeasible trajectories found in the dataset and the baseline model. Thus, our approach fosters trust in trajectory prediction as its interaction reasoning is interpretable, and its predictions adhere to physics.
Balancing Progress and Safety: A Novel Risk-Aware Objective for RL in Autonomous Driving
May 10, 2025Reinforcement Learning (RL) is a promising approach for achieving autonomous driving due to robust decision-making capabilities. RL learns a driving policy through trial and error in traffic scenarios, guided by a reward function that combines the driving objectives. The design of such reward function has received insufficient attention, yielding ill-defined rewards with various pitfalls. Safety, in particular, has long been regarded only as a penalty for collisions. This leaves the risks associated with actions leading up to a collision unaddressed, limiting the applicability of RL in real-world scenarios. To address these shortcomings, our work focuses on enhancing the reward formulation by defining a set of driving objectives and structuring them hierarchically. Furthermore, we discuss the formulation of these objectives in a normalized manner to transparently determine their contribution to the overall reward. Additionally, we introduce a novel risk-aware objective for various driving interactions based on a two-dimensional ellipsoid function and an extension of Responsibility-Sensitive Safety (RSS) concepts. We evaluate the efficacy of our proposed reward in unsignalized intersection scenarios with varying traffic densities. The approach decreases collision rates by 21\% on average compared to baseline rewards and consistently surpasses them in route progress and cumulative reward, demonstrating its capability to promote safer driving behaviors while maintaining high-performance levels.
Boundary-Guided Trajectory Prediction for Road Aware and Physically Feasible Autonomous Driving
May 10, 2025



Accurate prediction of surrounding road users' trajectories is essential for safe and efficient autonomous driving. While deep learning models have improved performance, challenges remain in preventing off-road predictions and ensuring kinematic feasibility. Existing methods incorporate road-awareness modules and enforce kinematic constraints but lack plausibility guarantees and often introduce trade-offs in complexity and flexibility. This paper proposes a novel framework that formulates trajectory prediction as a constrained regression guided by permissible driving directions and their boundaries. Using the agent's current state and an HD map, our approach defines the valid boundaries and ensures on-road predictions by training the network to learn superimposed paths between left and right boundary polylines. To guarantee feasibility, the model predicts acceleration profiles that determine the vehicle's travel distance along these paths while adhering to kinematic constraints. We evaluate our approach on the Argoverse-2 dataset against the HPTR baseline. Our approach shows a slight decrease in benchmark metrics compared to HPTR but notably improves final displacement error and eliminates infeasible trajectories. Moreover, the proposed approach has superior generalization to less prevalent maneuvers and unseen out-of-distribution scenarios, reducing the off-road rate under adversarial attacks from 66\% to just 1\%. These results highlight the effectiveness of our approach in generating feasible and robust predictions.
A Review of Reward Functions for Reinforcement Learning in the context of Autonomous Driving
Apr 12, 2024Reinforcement learning has emerged as an important approach for autonomous driving. A reward function is used in reinforcement learning to establish the learned skill objectives and guide the agent toward the optimal policy. Since autonomous driving is a complex domain with partly conflicting objectives with varying degrees of priority, developing a suitable reward function represents a fundamental challenge. This paper aims to highlight the gap in such function design by assessing different proposed formulations in the literature and dividing individual objectives into Safety, Comfort, Progress, and Traffic Rules compliance categories. Additionally, the limitations of the reviewed reward functions are discussed, such as objectives aggregation and indifference to driving context. Furthermore, the reward categories are frequently inadequately formulated and lack standardization. This paper concludes by proposing future research that potentially addresses the observed shortcomings in rewards, including a reward validation framework and structured rewards that are context-aware and able to resolve conflicts.
Informed Reinforcement Learning for Situation-Aware Traffic Rule Exceptions
Feb 06, 2024Reinforcement Learning is a highly active research field with promising advancements. In the field of autonomous driving, however, often very simple scenarios are being examined. Common approaches use non-interpretable control commands as the action space and unstructured reward designs which lack structure. In this work, we introduce Informed Reinforcement Learning, where a structured rulebook is integrated as a knowledge source. We learn trajectories and asses them with a situation-aware reward design, leading to a dynamic reward which allows the agent to learn situations which require controlled traffic rule exceptions. Our method is applicable to arbitrary RL models. We successfully demonstrate high completion rates of complex scenarios with recent model-based agents.
KI-PMF: Knowledge Integrated Plausible Motion Forecasting
Oct 18, 2023Accurately forecasting the motion of traffic actors is crucial for the deployment of autonomous vehicles at a large scale. Current trajectory forecasting approaches primarily concentrate on optimizing a loss function with a specific metric, which can result in predictions that do not adhere to physical laws or violate external constraints. Our objective is to incorporate explicit knowledge priors that allow a network to forecast future trajectories in compliance with both the kinematic constraints of a vehicle and the geometry of the driving environment. To achieve this, we introduce a non-parametric pruning layer and attention layers to integrate the defined knowledge priors. Our proposed method is designed to ensure reachability guarantees for traffic actors in both complex and dynamic situations. By conditioning the network to follow physical laws, we can obtain accurate and safe predictions, essential for maintaining autonomous vehicles' safety and efficiency in real-world settings.In summary, this paper presents concepts that prevent off-road predictions for safe and reliable motion forecasting by incorporating knowledge priors into the training process.