 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectVisA-120: Object-based Visual Attention Prediction in Interactive Street-crossing Environments
Jan 19, 2026The object-based nature of human visual attention is well-known in cognitive science, but has only played a minor role in computational visual attention models so far. This is mainly due to a lack of suitable datasets and evaluation metrics for object-based attention. To address these limitations, we present \dataset~ -- a novel 120-participant dataset of spatial street-crossing navigation in virtual reality specifically geared to object-based attention evaluations. The uniqueness of the presented dataset lies in the ethical and safety affiliated challenges that make collecting comparable data in real-world environments highly difficult. \dataset~ not only features accurate gaze data and a complete state-space representation of objects in the virtual environment, but it also offers variable scenario complexities and rich annotations, including panoptic segmentation, depth information, and vehicle keypoints. We further propose object-based similarity (oSIM) as a novel metric to evaluate the performance of object-based visual attention models, a previously unexplored performance characteristic. Our evaluations show that explicitly optimising for object-based attention not only improves oSIM performance but also leads to an improved model performance on common metrics. In addition, we present SUMGraph, a Mamba U-Net-based model, which explicitly encodes critical scene objects (vehicles) in a graph representation, leading to further performance improvements over several state-of-the-art visual attention prediction methods. The dataset, code and models will be publicly released.
Context-empowered Visual Attention Prediction in Pedestrian Scenarios
Oct 30, 2022Effective and flexible allocation of visual attention is key for pedestrians who have to navigate to a desired goal under different conditions of urgency and safety preferences. While automatic modelling of pedestrian attention holds great promise to improve simulations of pedestrian behavior, current saliency prediction approaches mostly focus on generic free-viewing scenarios and do not reflect the specific challenges present in pedestrian attention prediction. In this paper, we present Context-SalNET, a novel encoder-decoder architecture that explicitly addresses three key challenges of visual attention prediction in pedestrians: First, Context-SalNET explicitly models the context factors urgency and safety preference in the latent space of the encoder-decoder model. Second, we propose the exponentially weighted mean squared error loss (ew-MSE) that is able to better cope with the fact that only a small part of the ground truth saliency maps consist of non-zero entries. Third, we explicitly model epistemic uncertainty to account for the fact that training data for pedestrian attention prediction is limited. To evaluate Context-SalNET, we recorded the first dataset of pedestrian visual attention in VR that includes explicit variation of the context factors urgency and safety preference. Context-SalNET achieves clear improvements over state-of-the-art saliency prediction approaches as well as over ablations. Our novel dataset will be made fully available and can serve as a valuable resource for further research on pedestrian attention prediction.
CamLessMonoDepth: Monocular Depth Estimation with Unknown Camera Parameters
Oct 27, 2021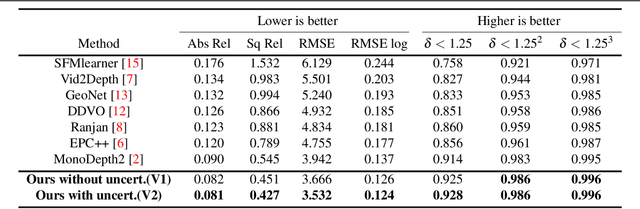

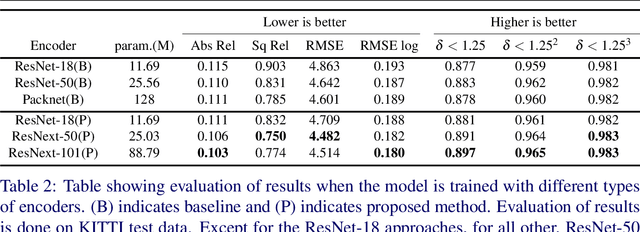
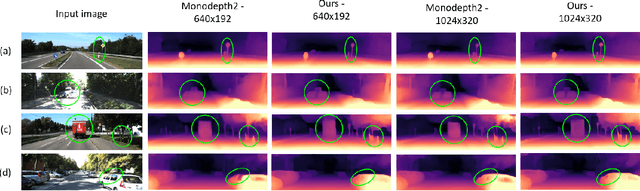
Perceiving 3D information is of paramount importance in many applications of computer vision. Recent advances in monocular depth estimation have shown that gaining such knowledge from a single camera input is possible by training deep neural networks to predict inverse depth and pose, without the necessity of ground truth data. The majority of such approaches, however, require camera parameters to be fed explicitly during training. As a result, image sequences from wild cannot be used during training. While there exist methods which also predict camera intrinsics, their performance is not on par with novel methods taking camera parameters as input. In this work, we propose a method for implicit estimation of pinhole camera intrinsics along with depth and pose, by learning from monocular image sequences alone. In addition, by utilizing efficient sub-pixel convolutions, we show that high fidelity depth estimates can be obtained. We also embed pixel-wise uncertainty estimation into the framework, to emphasize the possible applicability of this work in practical domain. Finally, we demonstrate the possibility of accurate prediction of depth information without prior knowledge of camera intrinsics, while outperforming the existing state-of-the-art approaches on KITTI benchmark.